目录月初得了新冠,症状比较重,一个月了还没有痊愈,耽误了不少时间
前段时间买了一年的.asia域名,利用vercel部署了RSSHub并在win端利用Fluent Reader订阅了一些有趣的论坛、公众号和博客。摆脱了推荐算法的感觉让我很快乐,对接收信息有很好的掌控感\^o^
我打算之后每周发布一条阅读摘选,加深对读过的优质信息的印象,以供查阅
学术相关
“研究困惑”的困惑——社会学研究中的理论困惑丨Sociological Theory
作者:Ashley Mears, 波士顿大学社会学系教授
在研究中解决一个重要的“困惑”是最为典型的社会科学理论贡献之一,然而目前许多研究都是为了发表而程序化地解决一个所谓的“困惑”,形成了“为了困惑而困惑”的问题现象。
Ashley通过整理前人研究认为,困惑是一个超出了我们预期并且尚无现成解释的难解谜题,显示了现有理论无法解释的东西,它最终是一个解释,而常用的寻找困惑的方式就是借助gap来定位困惑。她指出,困惑必须加以解释,并进一步理论化。
作为构建”困惑“的粉丝,Ashley也喜欢使用”悖论“(paradox)一词,但是她强调惯例性地运用”困惑“不仅不能增强过往文献和手头研究之间的关联,甚至会降低它们间的关联性。为减少此类问题,她对困惑进行分类,并为如何构建困惑提出了一些建议。
首先,Ashley将困惑分为“软困惑”和“硬困惑”两种。
软困惑:对某一事物的认知不完整而导致的困惑
- 奇怪现象而非理论上的困惑
- 很少直接呈现在研究者面前
- 在文献脉络和田野工作中都需要付出努力才能找到
硬困惑:过去的理论无法解释世上的经验问题
- 理论缺陷导致的困惑
困惑可以采取悖论的形式:一个矛盾到荒谬的命题在经过经验调查后被证明是正确的
Ashley进一步认为,无论软困惑还是硬困惑都可以为一项研究提供依据,在质性研究领域尤其如此。研究者必须通过困惑传递给读者研究目的和价值,如此才能让读者重视质性经验数据。
相比于困惑是什么,如何构建困惑是更为重要的一个问题。我们以往的教材学习和干中学可能会将我们引向错误路径。
“困惑”根治于美国学术写作当中(毫无疑问,全球的学术写作都如此),Yale教学与学习中心提出的“如何引人入胜”(motivating moves)写作八法中大部分都涉及困惑。
1.真相并不是人们所料想的,也不是一读就会发现的。
2.到目前为止,关于这个主题的知识有限。
3.这里有一个谜题或困惑有待回答。
4.与已发表的观点冲突。
5.透过研究这个微观现象,我们可以获知更宏观的现象。
6.这个看似次要或毫无意义的事物实际上很重要、也有趣。
7.这一事物存在不协调、矛盾或紧张,这有待解释。
8.标准的主流观点并不完美,需要加上限定条件。
事实上,困惑能够引起读者的注意力,并让他们感到惊喜(这通常很受审稿人欢迎),进而强调理论贡献的重要性。
传统上,我们总是在写作、展示和演讲中将困惑置于方法论和发现之前,但这歪曲了我们实际中长期的、数据驱动的研究过程,最终导致我们把大多实质上的归纳研究转化成了(形式上的)演绎性研究。
演绎性研究从理论开始,并使用经验推断出更广泛的命题与主张以概括现象,但以扎根理论为代表的归纳性方法则强调经验先于概念或叙事而存在,困惑来自于经验数据。
一个错误的做法是我们以一些理论假设来开启论文(但我们已经怀疑这些理论),并声称要设计一个项目测试或探索这些理论,之后假装很惊讶的指出个案/数据解决了理论困惑。但事实上,困惑和研究问题本身通常是研究者对数据非常熟悉后才发现的。我们在开始研究某一领域时,往往只有泛泛的兴趣,在之后继续研究和数据收集过程中,我们几乎同时找到真正的困惑和解惑方法。
对于困惑的偏爱致使我们在解开困惑的过程中产生了一种“恋惑癖”的问题。我们在构建困惑的过程中生造出了无用的类别或尝试不合适的理论、概念,装模作样地思考、煞有其事地测量(即使我们的认知早已超越)。最终在收集了许多奇形怪状的其他学者观点后拼凑出一幅精巧的理论拼图,但这些自我参照的解释都是精心拼凑的故事,看似相关,实则无关。
Ashley认为如果我们教条化的“困惑”使人们把“好理论”理解为“解释”,产生无关、无意义的理论,不如放弃对“好理论”虚假的热衷,退而求其次寻求深描作为最重要的贡献,为日后概括性的见解和解释提供基础。当然,在不发表就出局的世界,深描的写作更容易出现在专著之中,而非论文。
通过恋惑癖和把困惑“演绎化”,那些一开始想把使描述变得有相关性和有趣的努力都变成了对“好理论”的不敬。通过(不)解开困惑,那些看起来不寻常的危险做法或许恰恰是更好的。
规律与因果:大数据对社会科学研究冲击之反思
珞珈管理转载的一篇大数据方法对传统社会科学研究方法冲击的文章,里面有几个小的点我觉得还是值得关注的。
-
大数据提供一定范围的总体
- 可以分析抽样数据的偏差,减低对显著性检验的过度依赖
-
大数据边界不清晰
-
涌现出群体层面的规律
-
帕特里克·塔克尔指出 : “人类行为的可预测性比任何人想象中的都要强。” 艾伯特-拉斯洛·巴拉巴西 ( AlbertLászló Barabási) 同样认为 : “人类行为遵循着一套简单并可重复的模型,而这些模型则受制于更加广泛的规律。
-
-
极端值通常不再孤立呈现,可以被重新纳入研究框架
-
传统有限数据得出的结论需要接受大数据的检验
除此之外,我认为这篇文章的作者对大数据的理解浮于表面,有些观点并不正确。
如何用深度学习模型预测未来?
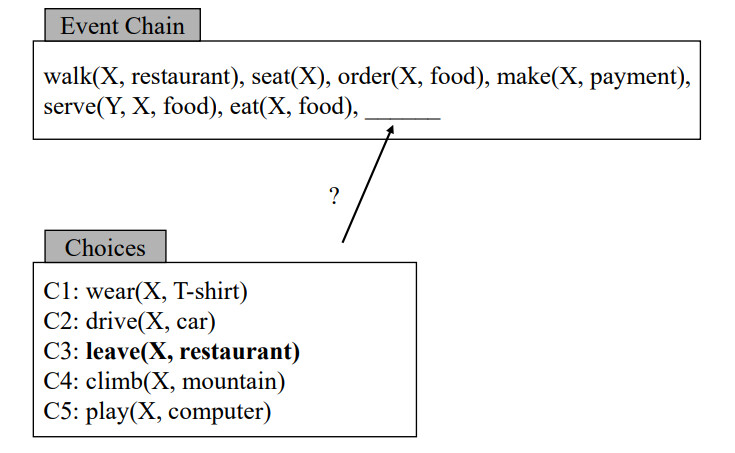
脚本:描述了特定任务一系列行为的事件序列1
任务目标:根据已知的事件序列,从若干候选的事件之中预测接下来会发生的事情
事件表示
-
离散事件表示:由事件元素构成的元组
- 对象谓词、对象间关系/属性、时间发生时间(三元组;Kim)
- 事件发生的动作/状态、一/多个实施者、一/多个时间作用对象、一/多个事件发生工具、一/多个地点、时间戳(六元组;Radinsky)
- 事件动作、实施者、受事者、时间戳(四元组;Ding)
- Predicate-GR任务中与同一角色相关的事件按事件关系整理成事件链,每个事件表示为动作与动作角色依存关系的二元组(Jurafsky)
- WordNet+VerbNet方法
-
稠密的事件表示:分布式语义表示—将文本单元嵌入到向量空间
-
基于词向量参数化加法的事件表示
- 事件元素词向量求均值(Weber)
- 词向量进行拼接作为事件的向量表示(Li)
- 词向量拼接,输入多层全连接神经网络(EventComp方法;Granroth-Wilding)
- 使用Predicate-GR的向量作为向量表示(Lee)
- 矩阵表示(Tilk等、Hong等)
设词表大小为$V$,角色数量为$R$,词向量维数$H$,构成三维张量$T\in\mathbb{R}^{V\times R\times H}$
为降低参数,将张量分解为$F$个一阶张量乘积的形式,使用三个矩阵A、B、C代替原本的三维张量
设$r$为表示角色的one-hot向量,角色$r$对应的词向量矩阵为一个切片$T$
$W_r = A\cdot diag(r\cdot B)\cdot C$
对每个事件元素,分别在其对应角色的词向量矩阵中查找其词向量,并将所有事件元素的词向量进行组合作为事件向量
-
基于张量神经网络的事件表示
基于词向量参数化加法的事件表示难以对事件表面形式的细微差异进行建模
双线性张量运算组合事件元素
设两个元素的向量分别为$v_1,v_2\in \mathbb{R}^d$
三维张量$T\in \mathbb{R}^{k\times d \times d}$是张量神经网络的参数
双线性张量计算$v_{comp}=v_1^T\cdot T^{[1:k]}\cdot v_2$
$v_{comp}$是$k$维向量
模型以乘性的方式捕获事件论元的交互,使微小表面差异在语义上放大
-
Neural Tensor Network模型NTN
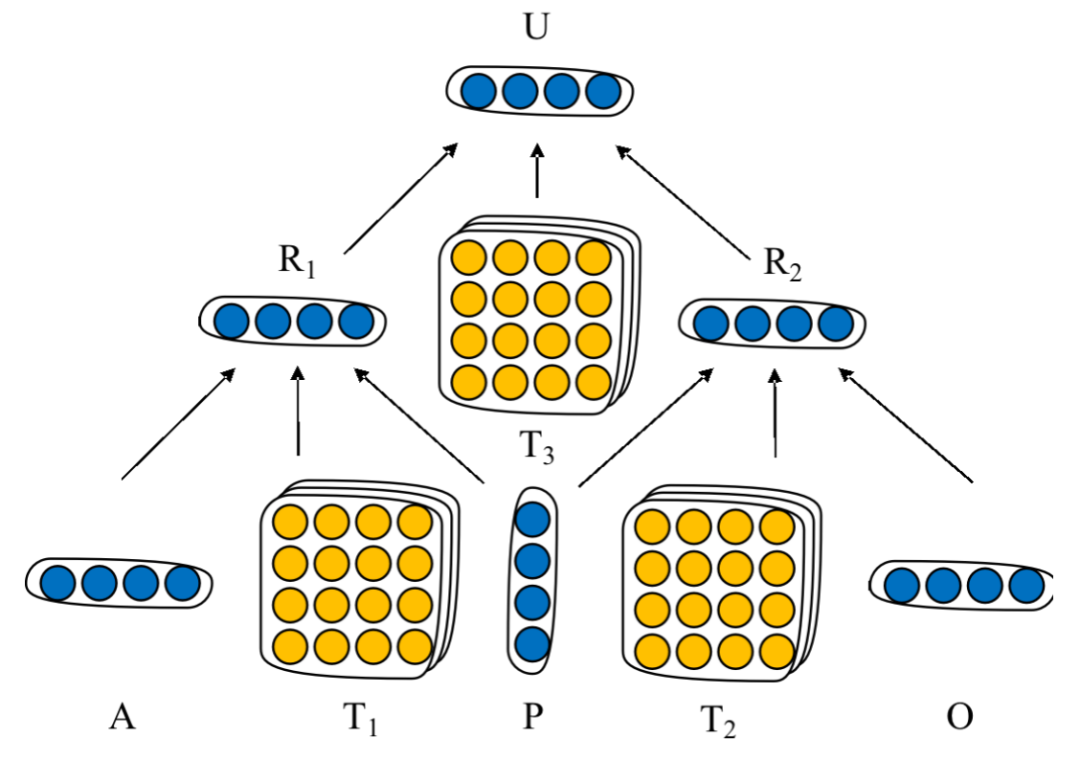
考虑$(O_1施事者, P动作, O_2受事者)$三元组事件结构
首先将$O_1$与$P$、$P$与$O_2$组合,再将获得的2向量组合得到最终的石坚表示U
每次组合有一个双线性张量运算,一个常规的线性运算与激活函数组成
-
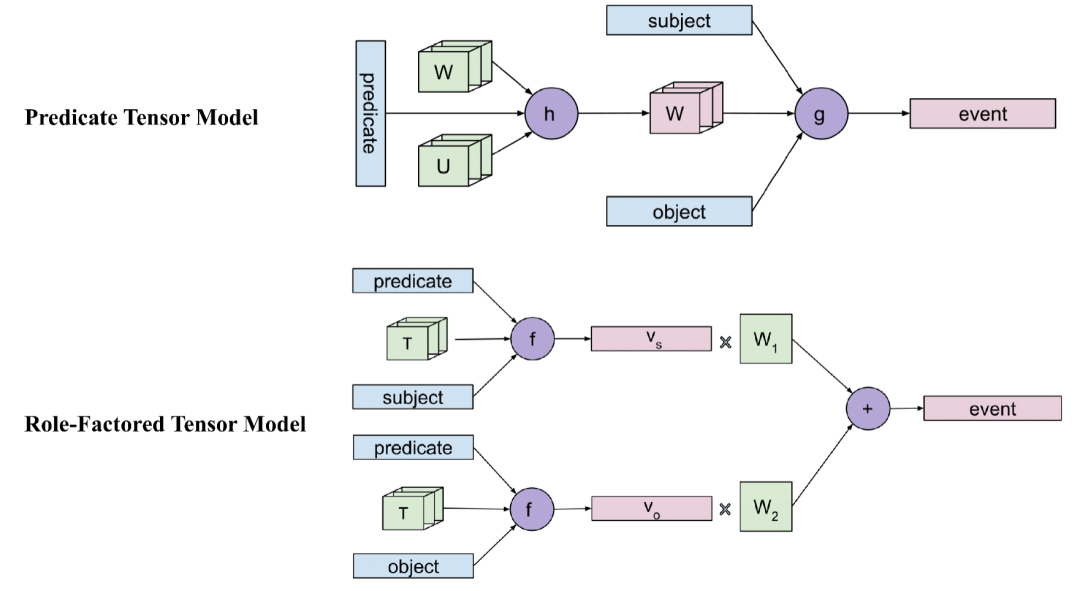
predicate Tensor模型&Role-Factored Tensor模型
-
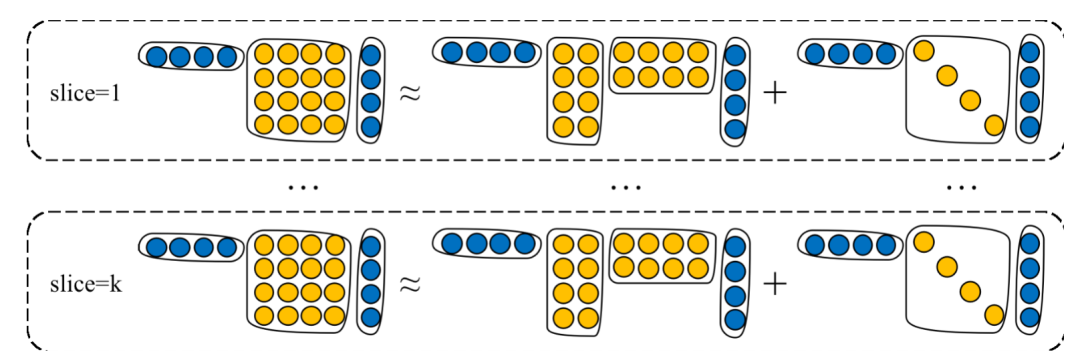
低秩张量分解
-
-
基于事件对关联建模的事件预测
事件:由主语、谓语、宾语、间接宾语构成的四元组表示
事件对:由事件序列中的事件与候选事件构成
早期方法:通过概率与统计相关算法计算事件对的共现频率,再通过整个事件序列中事件对的概率综合选择候选事件
*ex. 点互信息PMI算法(Pointwise Mutual Information)* *PMI用于衡量两个对象(如词)之间的相关性* $PMI(x,y)=log\frac{p(x,y)}{p(x)p(y)}=log\frac{p(x|y)}{p(x)}=log\frac{p(y|x)}{p(y)}$ 若PMI=0则两词独立,PMI>0则相关,PMI<0则互斥-
其他应用:SO-PMI情感倾向点互信息算法
- 选用一组褒义词和贬义词作为基准次
- 将测试词与褒义词和贬义词分别求PMI,并做差
随深度学习发展,深度学习成为更现代化的方法。
AAAI2016上提出的EventComp方法3
- 通过词嵌入方法进行事件元素表示
- 使用全连接网络对时间是否满足顺承关系进行分类
- 训练过程中使用随机采样构建满足顺承关系的正采样时间和不满足顺承关系负样本事件对
- 通过交叉熵进行模型优化
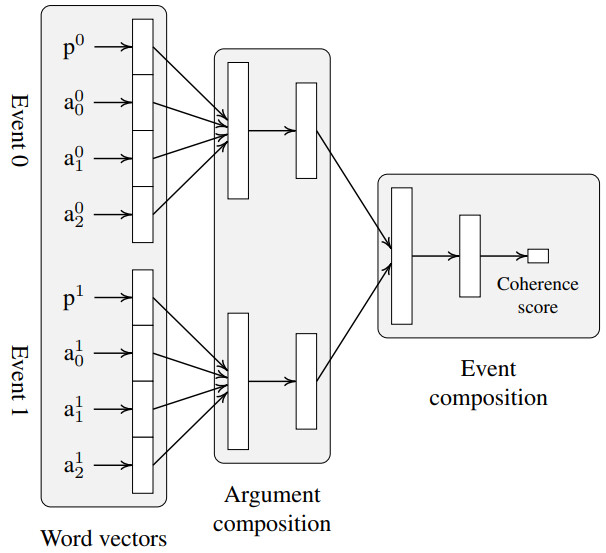
基于事件序列建模的事件预测
基于事件对的方法聚焦于亮亮单独事件之间的关联性,忽略整个事件序列中的语义交互
事件序列级别建模:AAAI2019: SAM-Net2
事件序列片段(event segment):由事件序列中若干个语义关联较强的事件构成的事件子序列(包含若干个连续/不连续的事件)
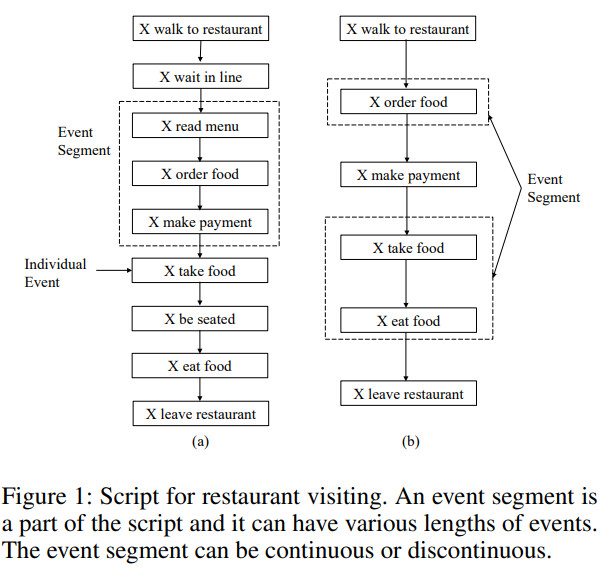
- 设计自注意机制建模事件间的语义关联性,将关联性强的事件划分为一个事件序列——实现事件序列片段划分
- 通过事件层面和事件序列层面的注意力机制分别来衡量单个事件和事件片段对事件预测的影响,并在二者的结合下进行最终的事件候选事件预测
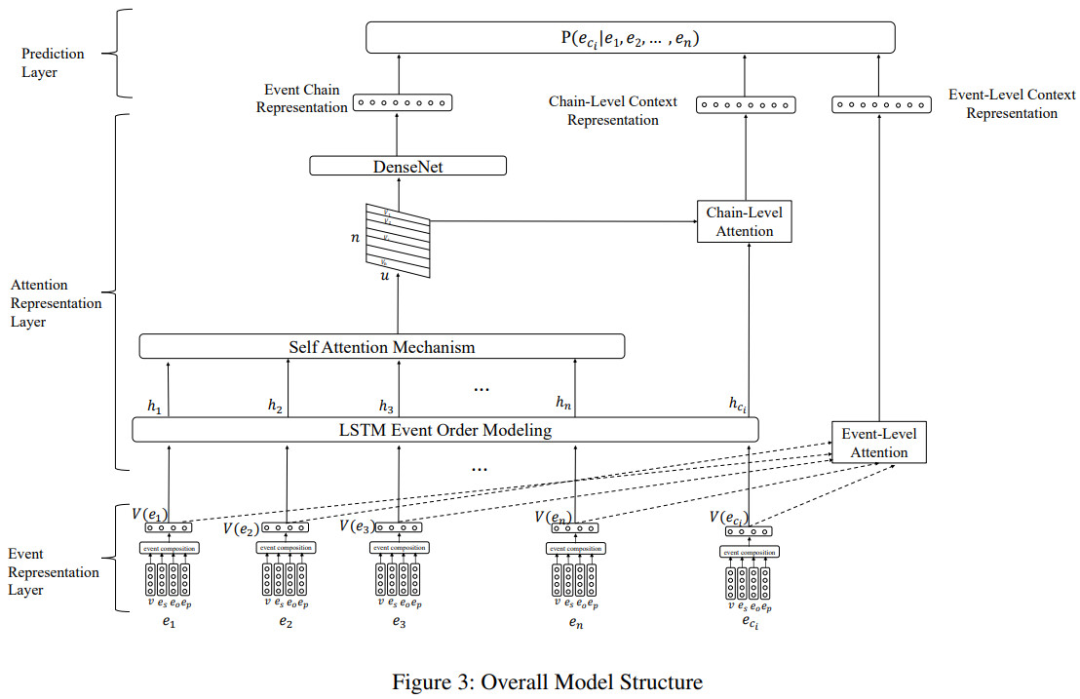
论元级别建模:WWW20214
早期方法只停留在粗粒度的事件级别建模,忽略了事件要素所呈现的复杂语义特征
同时建模事件要素级别、事件级别和事件序列级别的多粒度特征进行事件预测
- 事件表示模块
- 以整个事件序列为输入,通过带掩码的多头自注意机制学习事件要素间的隐式关联——细粒度的事件要素级别表示
- 将事件要素向量拼接,通过全连接层和激活函数的特征变换输出——事件级特征表示
- 事件特征抽取模块
- 将事件序列转化为图结构上,通过图神经网络学习事件序列层面上的事件特征表示
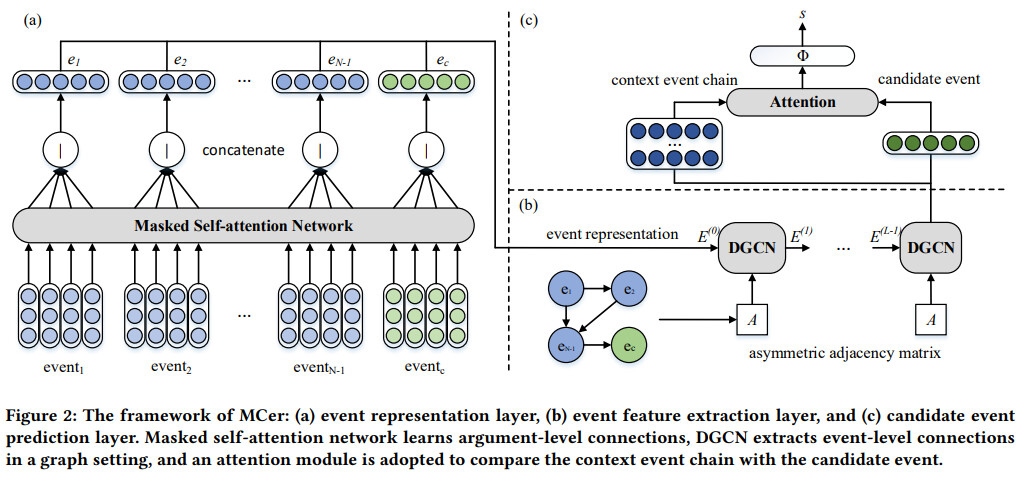
多粒度级别建模:IJIS20225
同时建模事件级别、事件序列级别和事件片段级别
基于图结构建模的时间预测
IJCAI2018: 叙事事件演化图NEEG6
图结构能够刻画一种更为复杂的事件间演化关系
节点为具体事件,有向边表示事件间的演化关系,权重表示演化关系出现的频率
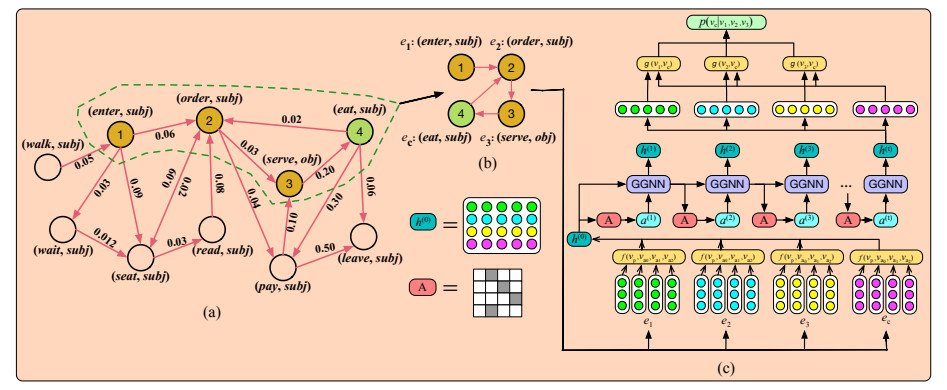
语义关系增强的事件预测
ACL20197
若给定了每步事件之间的关系(原因、时序、转折等),则事件预测的把握大大增加
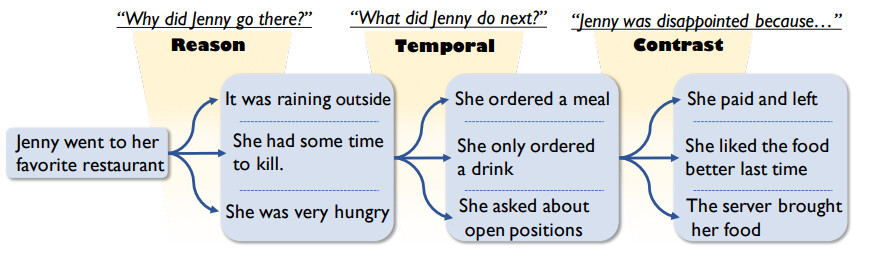
引入话语数据库PDTB中的话语关系(三类11种)
- COREF_NEXT:同一代链上的事件序列关系
- NEXT:特定大小上下文窗口之间同时发生的时间
- Discourse Relations: 9种话语关系
基于事件知识库的语义增强事件预测
融合外部的事件知识来帮助解决脚本事件预测问题
COLING20208
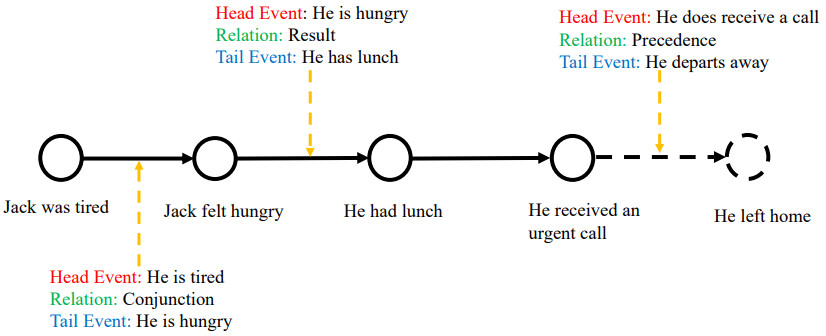
- 知识抽取阶段
- 以脚本序列中的事件作为查询,在事件知识库中检索对应的事件和时间三元组
- 知识融合阶段
- 融入尾实体(Tail only)
- 事件模板转换(Event Template)
- 关系嵌入便是(Relation Embedding)
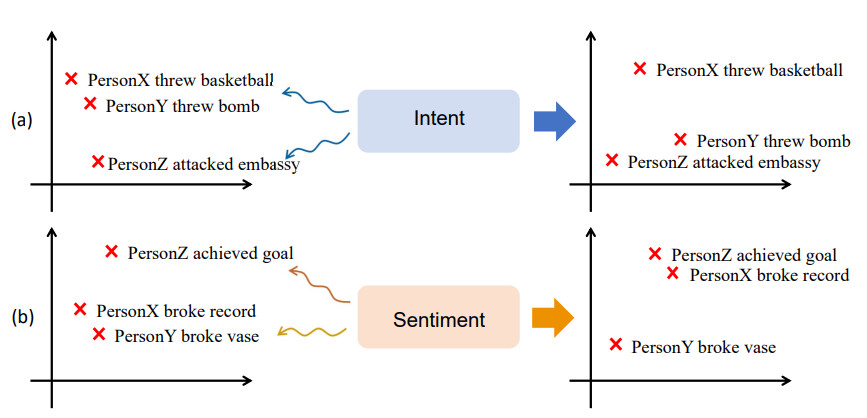
基于常识知识库的语义增强
EMNLP20199
客观事件的发生会被人类的主观情感所影响
通过EventMind和ATOMIC两个常识知识库引入情感和意图知识来增强事件表示的语义信息
原始文本增强的时间预测
AAAI202310
通过 Abstract Meaning Representation (AMR) 对事件原属文本进行解析,从而获取 rich event prediction,并通过Transformer编码器来捕捉事件论元间的关联关系
业界动态
现代数据栈中的消费层 BI+AI 产品的演进
之前看到的数仓和数据湖的文章少有描述决策相关的内容,看到这篇文章强调“智能决策”环节就重点关注了一下。但感觉目前数仓中的所谓智能决策更偏向于分析辅助工具箱。
概括来说,分享者提出的智能决策在手段上主要为数仓系统加载了回归、聚类等算法的图形视窗,当然有一些异常值自动侦测的脚本可以和回归系数、因子载荷相结合,初步报告一些异常情况分析。我认为这是一个很好的开始,但是目前来看,从消费者的角度分析,产品“智能决策”部分的使用价值并不高,因为这些数据并不比肉眼观察提供更多的关于如何改善经营的信息,且提供的数据可靠性缺乏保证,可能误导消费者决策。事实上,这套智能决策设计,我认为其象征价值要远远高于使用价值,对于实用主义的消费者而言,收不抵支。我认为我有理由怀疑目前环境下,对于大多数应用了数仓、BI和AI智能决策的企业,这些系统还没有为之带来实质利润。
当然,我们都无比坚信随着模型的不断优化、数据积累和训练成本降低,未来人工智能在辅助分析(与分析辅助有所差别)上大有作为空间。但从目前的趋势来看,我认为AI算法在可解释问题、可靠性评估等方面有所突破之前还不能进行智能决策,更有可行性的发展空间是在常规化问题上进行日常分析,目标消费者是没有数据分析基础的一般商业经营者。
具体而言,产品可以注重于降低使用门槛,减少编程接口等专业化功能,使消费者能够通过非专业的描述构建模型,令普通消费者可以以低学习成本体验产品,以对应目标用户下沉的目的。在分析方法上,毫无疑问描述性分析、可视化和异常报告等功能是必备的,同时企业应该以消费者希望借助数据化实现经营改进的目标为使命,为用户集成常用数据指标的分析模型和商业分析常用的思维模型,并必须为用户清晰明确地解释模型结果且提供对应的解决方案或相关案例。一言蔽之,面向大众消费者的智能数仓系统要降低使用门槛,实现用户下沉,进而赢得市场份额,并在这一过程中不断积累商业分析模型、产业案例、用户行为等数据,进而为未来辅助决策、深度分析等方向发展提供基础。
在技术上,近期有突破的大预言模型LLM可以实现自然语言的分析需求描述,通过云计算能够降低产品的运行成本,而初步构建一个面对日常经营问题的监控、分析和识别的专家系统应该具有一定的可行性,最后通过问题识别、分类通过案例库和专业知识库以知识图谱等形式为消费者提供管理建议。
当然,上述内容多是闭门造车的臆想罢了,但无论是强化智能分析系统的算法还是面向非专业分析人员的辅助分析系统,仅凭借算法上的突破成本和难度都是极大的,最重要的是商业分析的数据库建设,DATA。
数仓发展历程
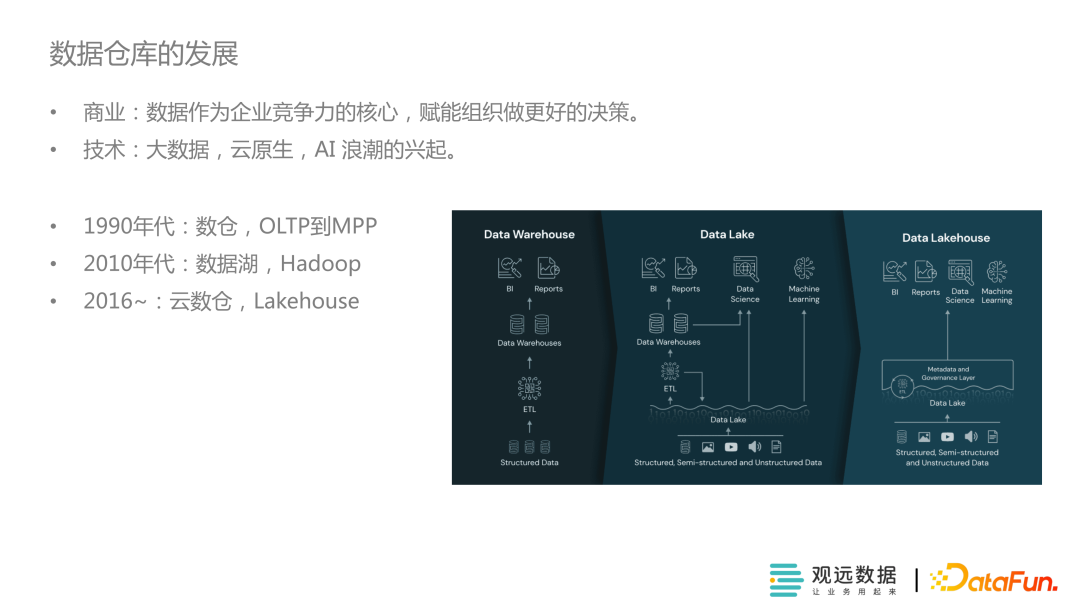
传统数据栈最大的问题是性能受限、成本高
在ETL层(Extract-Transform-Load)和BI层的使用门槛都很高,公司内部流程通常需要分析人员向IT部门提申请、排期后才能看到数据,处理分析流程长
最终的应用上也难以形成决策闭环
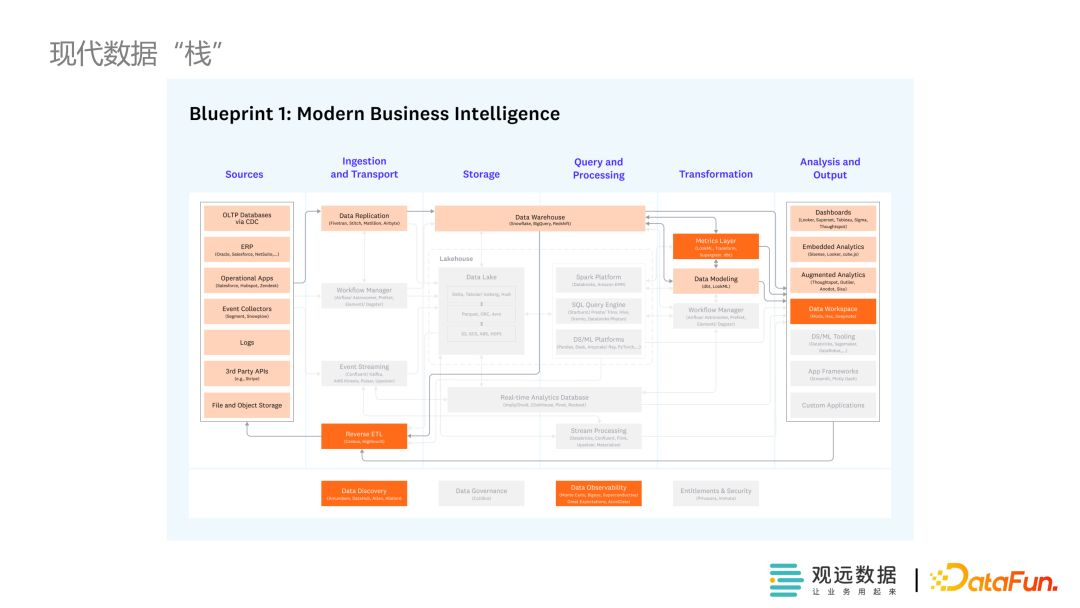
现代数据栈存算分离(storage、Query&Processing),Ingestion&Transport为EI层,transform与之分开
需要单独的组件跨组件协调工作,源数据分散在各处,需要专门的组件检测
企业可以按自身的发展阶段和需求加载、调整组件
- 业务中心——服务业务产生价值
- 云——降低成本
- 模块化产品
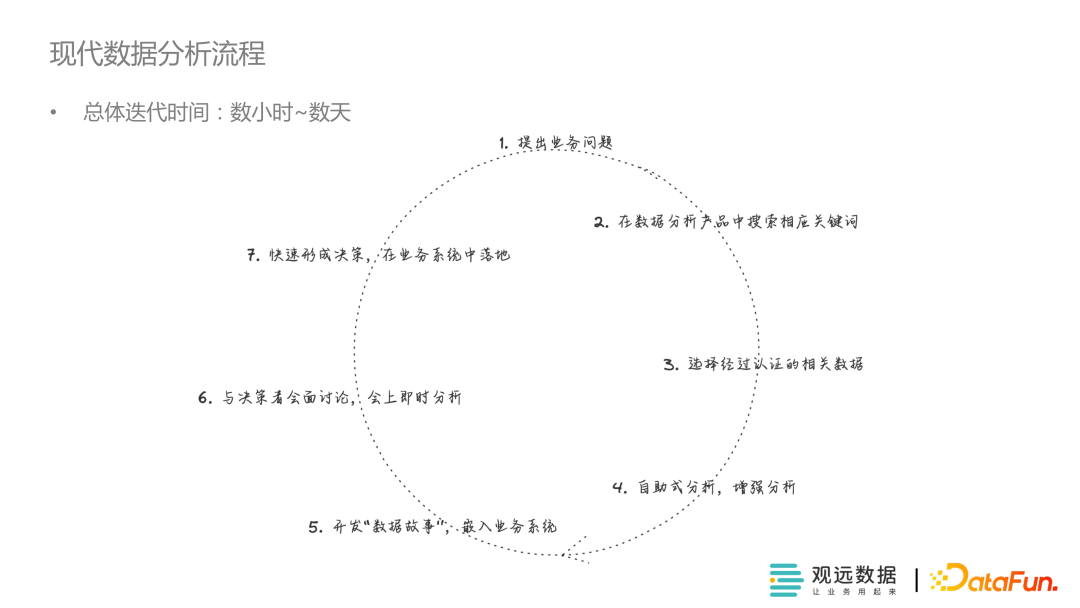
分享者提出的一个所谓现代数据栈的分析流程,有一点是我不明白经过认证的关键词是什么意思。更重要的是从一个分析人员的角度来说,这个流程更偏向与解决常规性的日常化数据分析,而不能解决复杂多变的重要管理决策,分析人员的使用体验会被IT人员的业务理解限制。退一步说,即使该系统致力于解决日常化的数据检测,那么一个简单的脚本库会更好的处理这个问题。所以我认为该流程图更偏向于编写自动化脚步的指导方案,而非分析流程。
后续的智能决策内容主要内容前文基本概括了,不再重复。遗憾的是分享者并未对智能决策进行深入探讨,只是表述了他所提出的数据栈方案在这方面具有很强的延展性,未来可以通过API接口等形式引入场景化、定制化的算法和知识库。
技术技巧
从零开发一个Python项目,手势识别!
之前只使用opencv库处理过图像,从来没有玩过摄像头,正好这个小案例体验一下
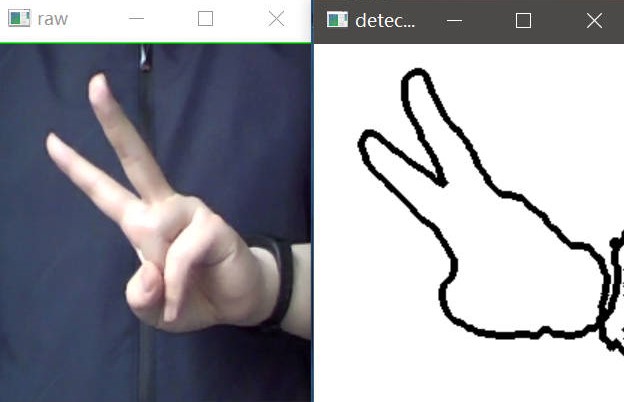
程序基本架构
- 图像获取cv2.VideoCapture
- 肤色检测cv2.COLOR_BGR2YCR_CB & cv2.threshold
- 轮廓检测cv2.findContours & cv2.drawContours
摄像头相关代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
import cv2
# 打开摄像头(摄像头自0依次编号)
cap = cv2.VideoCapture(0)
# 读取文件
# cap = cv2.VideoCapture("C:/Users/lenovo/Videos/...")
while True:
# 读取摄像头数据
success, frame = cap.read()
# 显示在创建的窗口上,命名为Video
cv2.imshow('Video', frame)
# 持续间隔50ms等待按键,特定按键q跳出循环
# & 0xFF为和运算,0xFF确保小键盘也是读取的ASCII码的后八位
key = cv2.waitKey(50) & 0xFF
if key == ord('q'):
break
# 断开摄像头
cap.release()
# 释放所有窗口wqq
cv2.destroyAllWindows()
不平衡数据集的建模的技巧和策略
以前我只知道使用欠采样、过采样的方法处理不平衡数据,这篇文章还提到了SMOTE和一些小技巧。本文提供了一个简单的示例,简单过一下就好,没有太多可说的。
不平衡数据常用评价指标为F1分数和AUC-ROC
SMOTE过采样11
- 对于少数类中每个样本$x$,计算$x$到少数类样本集中所有样本的距离,获取$k$近邻
- 根据样本不平衡比例设置采样倍率$N$,对于每个少数类样本$x$,从$k$近邻中随机选择$XN$个样本
- 对每个随机选出的近邻$XN$,分别与原样本$x_{new} = x + rand(0,1)×(\tilde{x}-x)$
缺点
- 近邻$K$值难以确定
- 无法克服非平衡数据集的数据分布问题,容易产生分布边缘化问题
Borderline-SMOTE1213
仅使用边界上的少数类样本来合成新样本,从而改善样本的类别分布
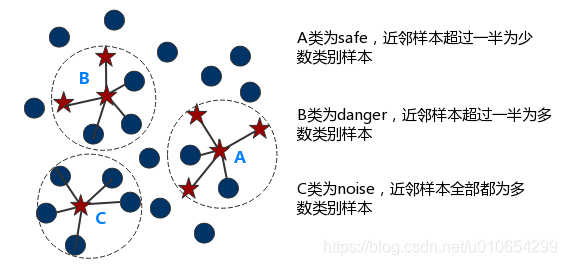
仅对Danger类别进行过采样
- Borderline-SMOTE1
- 以$k$近邻随机选择少数类样本
- Borderline-SMOTE2
- 在$k$近邻中随机选择任意样本,无关类别
ADASYN14
自适应合成抽样
对不同的少数类样本赋予不同的权重,生成不同数量的样本
-
计算合成的样本数量$G=(m_1 - m_2 )\times \beta$
$m_1$为多数类样本数量;$m_2$为少数类样本数量;$\beta \in [0,1]$
若$\beta=1$采样后正负类比例为1:1
-
计算$K$近邻中多数类占比$r_i=\bigtriangleup_i / K$
$\bigtriangleup_i$为$K$近邻中多数类样本数
-
对$r_i$标准化$\hat{r}i = r_i/\sum\limits{i=1}^{m_2}r_i$
-
计算每个少数类样本需要生成新样本的数目$g=\hat{r}_i\times G$
-
生成样本$s_i =x_i + \lambda(\tilde{x}_i-x_i)$
用Python实现一个A/B测试!
刚好被推送一个A/B test的一个kaggle数据集,简单过一下代码
推送的案例存在比较大的问题,所以又依据kaggle A/B Test 相关数据集找了2个NoteBook作为补充
里面有几个小的处理技巧之前不太熟悉,但挺有意思的,温故知新
【可视化】
本地Jupyter Notebook存储位置:AB-test 2023-02-08.ipynb
数据集:Example Dataset for A/B Test
A/B test example application for an anonymous company
By İLKER YILDIZ · UPDATED A YEAR AGO
另一个高赞NoteBook:A/B testing analysis
By JIALI SONG · 1Y AGO · 1,110 VIEWS
找到另外一个数据集和NoteBook
Analyze an A/B test from the popular mobile puzzle game, Cookie Cats.
NoteBook:A/B Testing: Step by Step & Hypothesis Testing
AB Testing Process¶
- Understanding business problem & data
- Detect and resolve problems in the data (Missing Value, Outliers, Unexpected Value)
- Look summary stats and plots
- Apply hypothesis testing and check assumptions
- Check Normality & Homogeneity
- Apply tests (Shapiro, Levene Test, T-Test, Welch Test, Mann Whitney U Test)
- Evaluate the results
- Make inferences
- Recommend business decision to your customer/director/ceo etc.
-
Schank, R. C., & Abelson, R. P. (2013). Scripts, plans, goals, and understanding: An inquiry into human knowledge structures. Psychology Press. ↩
-
Lv, S., Qian, W., Huang, L., Han, J., & Hu, S. (2019, July). Sam-net: Integrating event-level and chain-level attentions to predict what happens next. In Proceedings of the AAAI conference on artificial intelligence (Vol. 33, No. 01, pp. 6802-6809). ↩ ↩2
-
Granroth-Wilding, M., & Clark, S. (2016, March). What happens next? event prediction using a compositional neural network model. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 30, No. 1). ↩
-
Wang, L., Yue, J., Guo, S., Sheng, J., Mao, Q., Chen, Z., … & Li, C. (2021, April). Multi-level connection enhanced representation learning for script event prediction. In Proceedings of the Web Conference 2021 (pp. 3524-3533). ↩
-
Zhou, P., Wu, B., Wang, C., Peng, H., Yue, J., & Xiao, S. (2022). What happens next? Combining enhanced multilevel script learning and dual fusion strategies for script event prediction. International Journal of Intelligent Systems, 37(11), 10001-10040. ↩
-
Li, Z., Ding, X., & Liu, T. (2018). Constructing narrative event evolutionary graph for script event prediction. arXiv preprint arXiv:1805.05081. ↩
-
Lee, I. T., & Goldwasser, D. (2019, July). Multi-relational script learning for discourse relations. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (pp. 4214-4226). ↩
-
Lv, S., Zhu, F., & Hu, S. (2020, December). Integrating external event knowledge for script learning. In Proceedings of the 28th International Conference on Computational Linguistics (pp. 306-315). ↩
-
Ding, X., Liao, K., Liu, T., Li, Z., & Duan, J. (2019). Event representation learning enhanced with external commonsense knowledge. arXiv preprint arXiv:1909.05190. ↩
-
Bai, L., Guan, S., Li, Z., Guo, J., Jin, X., & Cheng, X. (2022). Rich Event Modeling for Script Event Prediction. arXiv preprint arXiv:2212.08287. ↩
-
Chawla, N. V. , Bowyer, K. W. , Hall, L. O. , & Kegelmeyer, W. P. . (2002). Smote: synthetic minority over-sampling technique. Journal of Artificial Intelligence Research, 16(1), 321-357. ↩
-
Han, H. , Wang, W. Y. , & Mao, B. H. . (2005). Borderline-smote: a new over-sampling method in imbalanced data sets learning. Lecture Notes in Computer Science. ↩
-
https://blog.csdn.net/u010654299/article/details/103980964 ↩
-
He, H., Bai, Y., Garcia, E. A., & Li, S. (2008, June). ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In 2008 IEEE international joint conference on neural networks (IEEE world congress on computational intelligence) (pp. 1322-1328). IEEE. ↩