- 学术相关
- 业界动态
- 技术技巧
- 娱乐
学术相关
Coggle数据科学推荐系统系列1:深入理解YouTube推荐系统算法
作者梳理了2008年~2016年YouTube发表的四篇推荐系统论文,重点对2016年的YouTube深度神经网络推荐模型进行了简要介绍。
- 2008:《Video Suggestion and Discovery for YouTube》1
- 吸附算法(ADSORPTION):解决视频标签的扩散
- 2010:《The YouTube Video Recommendation System》2
- 当时YouTube推荐系统的核心是基于Item-CF的协同过滤算法
- 通过当前和历史兴趣中喜欢的视频找出相关视频
- 视频相关性:共同点击个数描述
- 当时YouTube推荐系统的核心是基于Item-CF的协同过滤算法
- 2013:《Label Partitioning For Sublinear Ranking》3
- 将推荐问题变成多分类问题
- 2016:《Deep Neural Networks for YouTube Recommendations》4
- YouTube迈向了以深度学习算法为主导的推荐系统
2016年的论文中认为YouTube构建推荐系统面临的三大难点是:
- 数据规模庞大:用户和视频量级都是Billion级别,需要分布式学习算法和高效部署
- 即时响应:推荐系统需要实时对新视频和用户新行为做出响应
- 数据噪声强:大部分视频只有隐式反馈(用户对视频的观看行为),缺少显示反馈(评价);视频meta信息结构化程度有限;数据稀疏;易受外部因素影响
系统框架
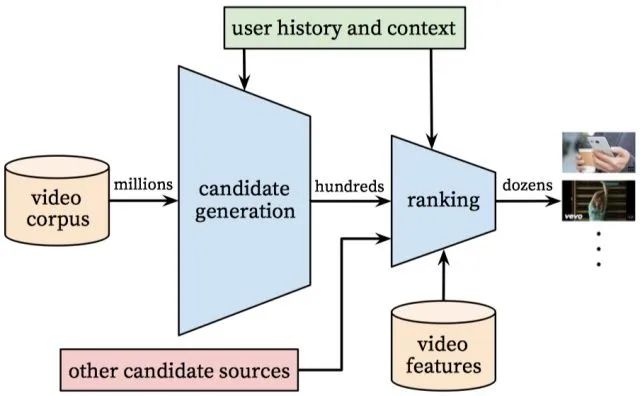
- 第一部分 召回网络
- 从百万级数据库中检索少量候选视频
- 快速处理:模型和特征不能过于复杂
- 依据用户的历史信息召回
- 用户相似度通过粗略特征表示
- 从百万级数据库中检索少量候选视频
- 第二部分 排序网络
- 丰富和精细用户/视频特征
- 预测用户对召回视频的评分,排序
- 需要精准推送视频,采用复杂模型和特征提升推荐效果
- 第三部分 线下评估
- 评价指标:precision、recall、ranking loss
- 线下A/B Test:点击率、观看时间等
召回网络
传统召回思路
- 离线计算商品的Embedding和用户的Embedding
- 线上召回:用户Embedding和商品Embedding内积,找出TOP N
存在问题:性能问题、计算问题等
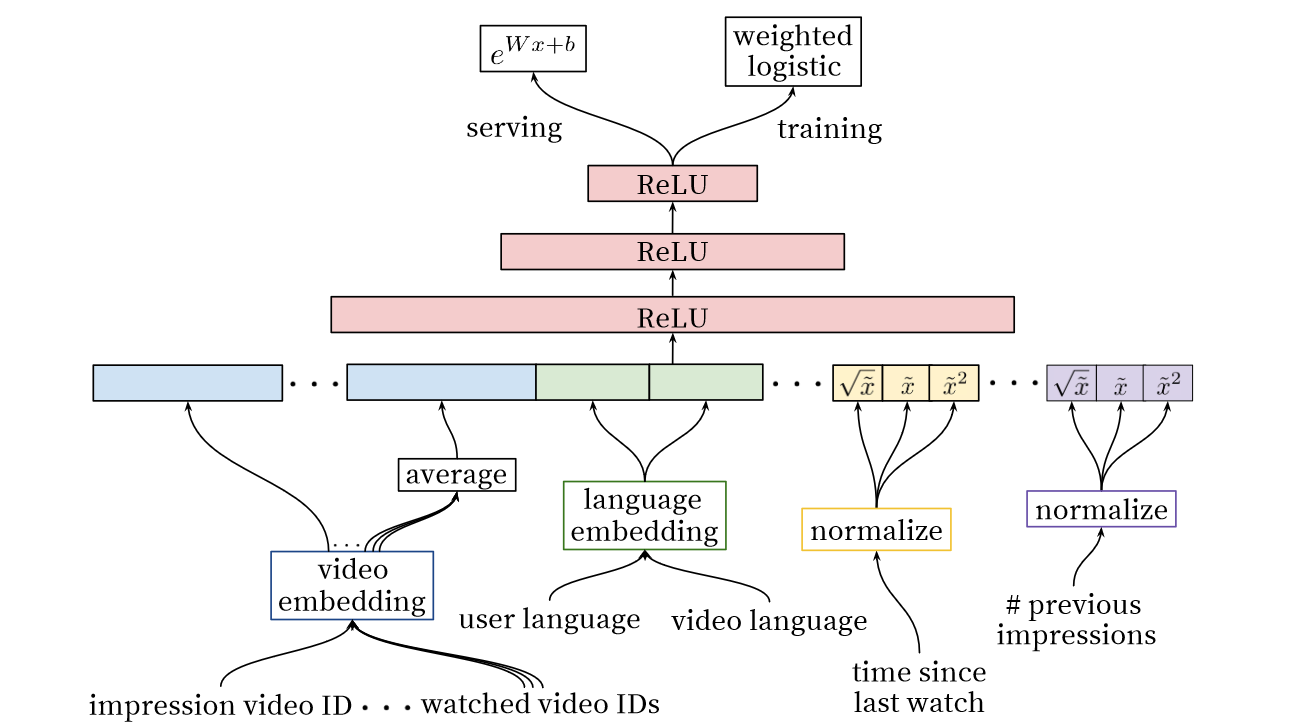
YouTube召回模型
召回阶段,YouTube将推荐问题视作超大规模多分类问题(Softmax分类)
即基于特定用户$U$及其上下文$C$,在时间$t$被观看的特定视频$w_t$为视频库$V$中的数百万视频$i$(类)的概率:$P(w_t=i|U,C)=\frac{e^{v_iu}}{\sum\limits_{j\in V}e^{v_ju}}$
其中$u\in\mathbb{R}^N$表示(用户,上下文)对的高维嵌入Embedding向量,$v_j\in \mathbb{R}^N$表示每个候选视频的Embedding向量。在这里Embedding只是简单的将稀疏实体映射到稠密向量之中。
学习器的任务是学习(用户历史信息,上下文)的函数user embeddings向量$u$,使之能够作为$w_t$的Softmax有效分类。
为提高训练效率,YouTube采用了负采样算法(“候选人抽样”)提升训练速度,并用重要性加权方式校正采样。之后为每个样本,对其真实标签和负类最小化交叉熵损失函数。根据测试,该方式比经典Softmax速度提升超过100倍。
YouTube召回模型网络结构
受NLP任务采用word2vec将文本表示成计算机可理解的结构启发,采用了word embedding的技巧将视频嵌入到固定长度的高维向量中并喂给前馈神经网络。用户的观看历史表示为由稀疏的视频ID通过Embedding映射到稠密向量的变长序列。DNN网络需要固定大小的稠密输入所有对几个嵌入表现最好的策略(求和、Component-wise max等)简单求平均。
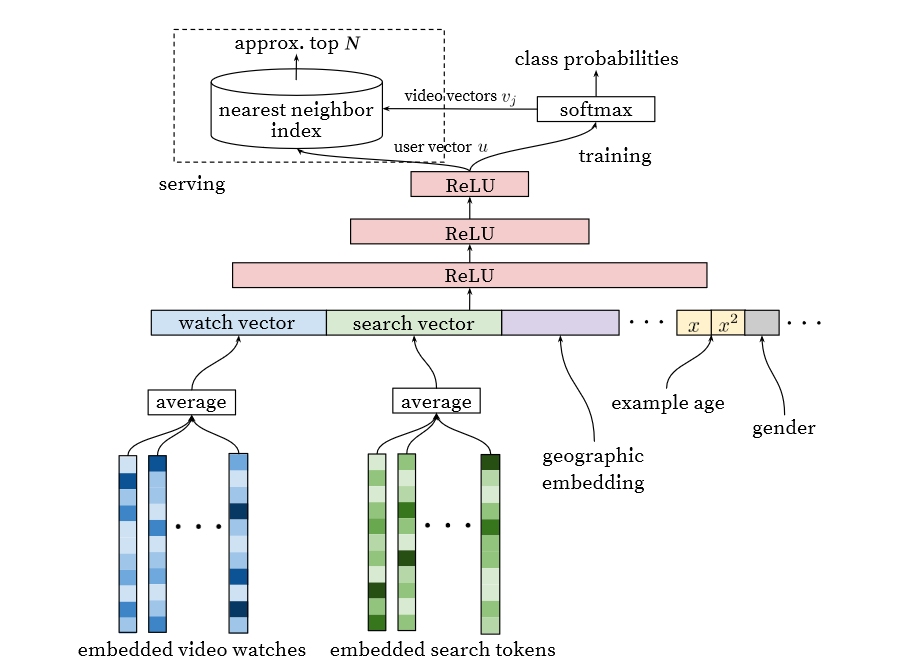
使用DNN的重要原因是模型可以轻松输入连续型变量和分类变量,如用户地理信息、设别、性别、年龄等,其中登录状态和年龄进行了归一化。
特征工程
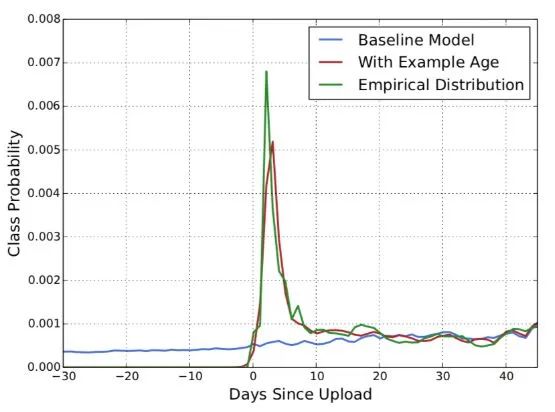
这篇论文中的一项重要特征工程是样本年龄Example Age,即用户倾向于观看新的视频(即便会牺牲一些相关性),而传统的模型都是基于历史观看记录计算的,这违背了现实。实验表明,Example Age对模型拟合提升效果十分明显。
一个十分经典、明晰的消费者行为
MLP层是常见的塔状设计,底层最宽,往上每层神经元数据减半,及至Softmax层是256维,激活函数采用ReLU。
召回优化
目前,我们获取了所有视频的Embedding $k$维向量$v_j, j\in V$,维度是$pool\ size\times k$,用户$k$维输出向量$u$。
在线服务阶段,系统通过对视频向量$v_j$和用户向量$u$进行相似度计算。此处,为满足时延要求,实际采用的是最近邻查询方式提取TOP N视频作为召回结果。
样本选择和上下文选择
-
使用更广的数据源:推荐场景数据+搜索场景数据等
-
为每个用户生成固定数量训练样本:平等对待每个用户,避免loss被少数活跃用户掌控
-
抛弃序列信息:对Embedding向量进行加权平均,这有些反直觉,可能是模型对负反馈没有很好建模
-
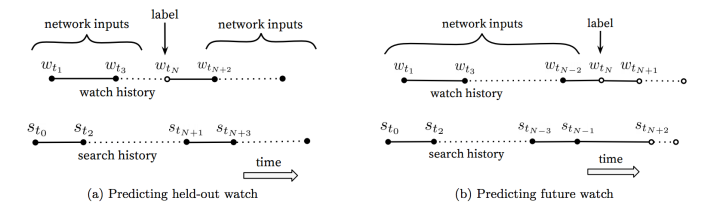
不对称的共同浏览问题(asymmetric co-watch):传统协同过滤算法采用上下文信息的held-out模式,而A/B测试中使用上文信息的predicting next watch模式更佳
排序网络
在排序阶段,主要目的是对候选集进行细化和校准,同时还涉及多种不同召回源视频的有效集成。此外,由于候选集规模较小,所以排序阶段可以进行更精细化的建模。
特征工程
虽然深度学习中隐含了特征工程,但YouTube认为数据的类型不适合前馈神经网络的输入, 所以还是进行了特征工程。
- 用户历史行为:与哪些items有过交互或和相似的items有过交互
- 上次观看时间:自上次观看同channel视频的时间
- 视频曝光次数:若视频已经曝光给该用户且没有观看,则下次曝光被观看的概率降低
- 视频提名来源、得分
对于分类特征,使用Embedding将稀疏的特征映射到适合神经网络的稠密矩阵形式。每个独特视频ID对应一个单独学习的Embedding向量,它的维度和ID个数的对数成正比。我们将大的候选集裁剪为仅包含点击印象最高的TOP N个视频,其他视频被嵌入为0。视频ID的分类特征底层Embedding是共享的,对提升泛化能力、加速训练、减小内存非常重要。
对连续特征,YouTube团队使用了归一化减少神经网络对输入的缩放和分布敏感问题的影响。连续型特征的分布$f$被转化为[0,1)均匀分布。此外,作者还输入了这些特征的超线性($\bar{x}^2$等)和亚线性($\sqrt{\bar{x}}$等),使非线性关系更容易在神经网络中被表达,增强了拟合效果。
排序模型
排序模型的训练目标是预测正例(点击)和负例(未点击)的用户观看时长,这样可以排除用户点击但不愿意看这类情况的噪声。模型采用加权logistic回归,损失函数为交叉熵损失。其中正例采用观看时长作为权重,负例使用单位权重,这样logistic回归学得的odds为$\frac{\sum T_i}{N-k}$,其中$N$为训练样本数,$k$为正例数,$T_i$为第$i$个视频的观看时长。假设正例在样本中很小(实际中,推荐的视频是相对多的,而用户只能点击一个),则odds就近似为$E(T)$,之后使用指数函数作为最终的激活函数产生观看时长的近似值。
隐藏层设计

YouTube借助次日测试数据在实际环境中测试了不同隐藏层配置。其中weighted, per-user loss是通过向用户展示的同一页面推荐视频的模型打分里负例得分高于正例的比例计算获得的。结果表示隐藏层网络宽度和深度增加都能提升模型效果,但也增大了CPU时间开销,权衡后最底层为1024 ReLU。
机器学习百道面经
关于聚类、正则化、损失函数等问题的面试题,转存
本地存储位置:’’./My_job/机器学习百道面经.md’
高效整数规划求解,快手提出多元因果森林模型,智能营销效果显著
快手为了实施细粒度的营销决策,在因果森林的基础上提出了多元因果模型,使单一模型可以同时处理多种干预手段,而不是仅仅是二元因果。
首先归回到目前业界希望借助因果推断解决的核心问题之一——异质性因果效应HTE。HTE是指由于样本个体特征不同,干预在个体上产生不同效果的现象。在精准营销之中,精确地区分不同干预的目标受众和影响是一项至关重要的工作。
近年来学界业界比较认可的HTE方法是Stanford经济学教授Susan Athey et al.提出的因果森林模型GRF5(代码)。GRF引入了得分函数$\Psi(O_i)$,待拟合函数$\theta(x)$和辅助函数$v(x)$,其中$o_i$是$(Y_i,W_i)$。算法的核心是寻求满足局部估计等式$E[\Psi_{\theta(x),v(x)(O_i)|X_i=x}]=0, for\ all\ x\in X$,对因果效应估计$\Psi_{\theta(x),v(x)(o_i)}=Y_i-\theta(x)W_i-v(x)$,对应$Y=\theta(x)W_i+v(x)$通过学习$\theta(x)$使得实验组和空白组数据预估值和真实值差异最小。在无混淆假设下$\theta(x)=\frac{Cov[W_i,Y_i|X_i=x]}{var[W_i|X_i=x]}$。6
GRF本质是基于CART树的随机森林。最大化分裂标准$\bigtriangleup(C1,c2)=\frac{n_{c1}n_{c2}}{n_p^2}(\hat{\theta}{c1}(J)-\hat{\theta}{c2}(J))^2$。后边暂时没看明白,以后拿原始论文再看一下。
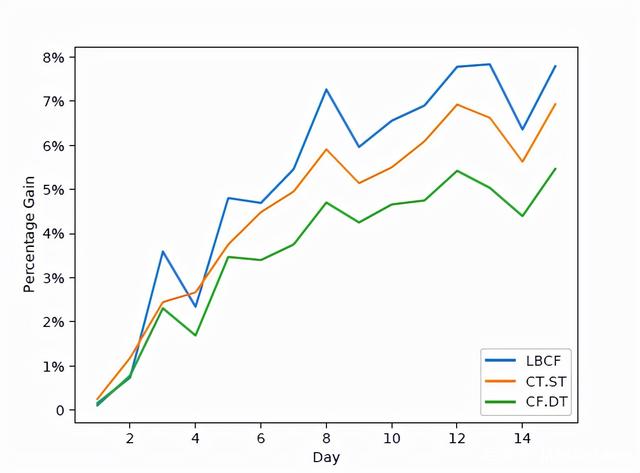
快手的多元因果森林模型7(代码)重新设计了因果森林的分裂准则,每次分裂时不但强调不同节点间的异质性,即节点间分裂,同时也强调节点内不同干预手段的异质性,即节点内分裂。
为平衡算法的效率和效果,该模型首先通过节点间选择TOP N个备选特征分裂点;之后通过节点内分裂从N个备选中选择最终的特征分裂点。此外,在快手亿级别的用户量导致决策变量数极大的环境下,使用现存的开源求解器会出现内存溢出等问题,所以快手团队设计了可并行的Dual Gradient Bisection(DGB)算法,运用了松弛、KKT和对偶等方法对问题进行转换。
在多元因果模型评估上团队没有很好的解决思路。目前在二元因果模型中,常用的评估方法是AUUC、Qini Curve等,若使用其评估多元因果模型需要把模型拆分为二元因果,而这样就丧失了多元因果的价值了。
目前团队使用的一个评估方法是利用随机控制实验数据构建可以观测真实结果的匹配样本。这些匹配样本的均值是各列期望的良好估计,所以可以计算多元因果模型的整体收益。
最后,团队通过WWW 2021的公开仿真数据集与业界主流树基因果模型进行对比,多元因果森林效果优于CT.ST和CF.DT。实际部署在快手智能营销的AB实验的效果也比较好。
风笑天:读懂一篇文献需要回答的20个问题
文章从风笑天老师的《社会研究方法(第五版)》中整理了20个论文阅读/写作相关的关键问题,覆盖了从问题提出、研究设计、数据收集、数据分析到结论发现的全部环节,可以作为思考、分析论文的提示卡。
Transformer 统治的时代,为什么 LSTM 并没有被完全替代?
这篇文章的写作有些混乱,事实上作者并没有回答他提出的问题,但是对Transformer、LSTM和CNN做了一些比较,可以看看。
- RNN优势
- 天然适配序列数据
- 接受不定长的线性序列
- 可引入门控结构
- 捕获长距离特征
- 通过Attention加持经常出现在SOTA模型中
- 叠加网络和引入Encoder-Decoder框架扩展了RNN能力
- 天然适配序列数据
- RNN劣势
- 训练效率低
- 序列依赖结构对大规模并行计算而言不友好
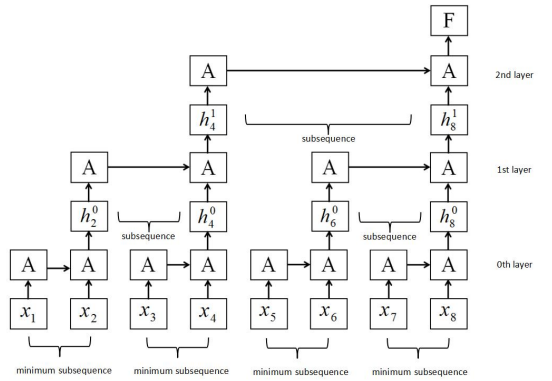
- RNN改进
Google NMT
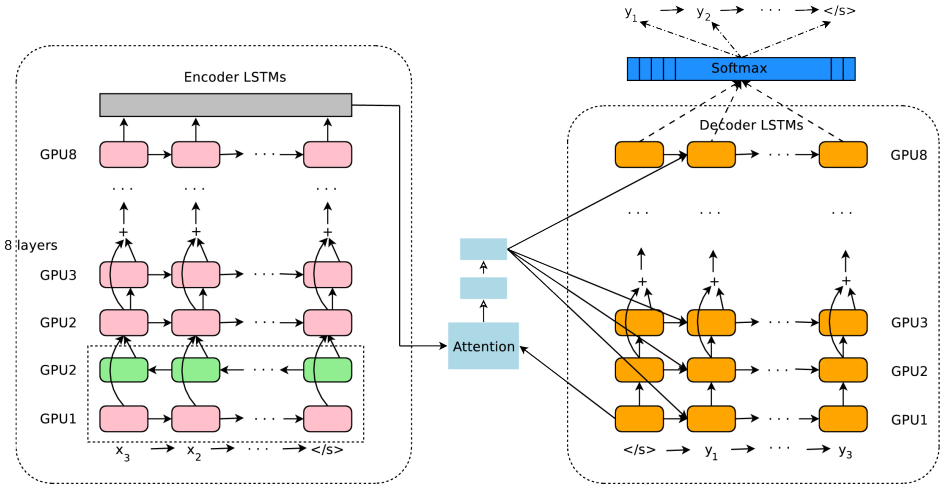
NMT结构包含了双向RNN、多层单向RNN、注意力机制、Encoder-Decoder结构
- Transformer
- Self-attention
- Multi-head Self-attention
模型效果比对
作者借助论文《Why Self-Attention? A Targeted Evaluation of Neural Machine Translation Architectures》10数据比较了RNNs(RNNS2S)、CNNS(ConvS2S)和self-attention models(Transformer)的语义特征提取能力和长距离特征捕获能力。此外,由于数据的多种因素和参数会影响模型效果,所以很难公平地比较各模型,因此作者统一采用了亚马逊的NMT框架Sockeye和固定的超参数、训练方法。评价标准为BLEU。
语义特征提取能力(WSD任务)
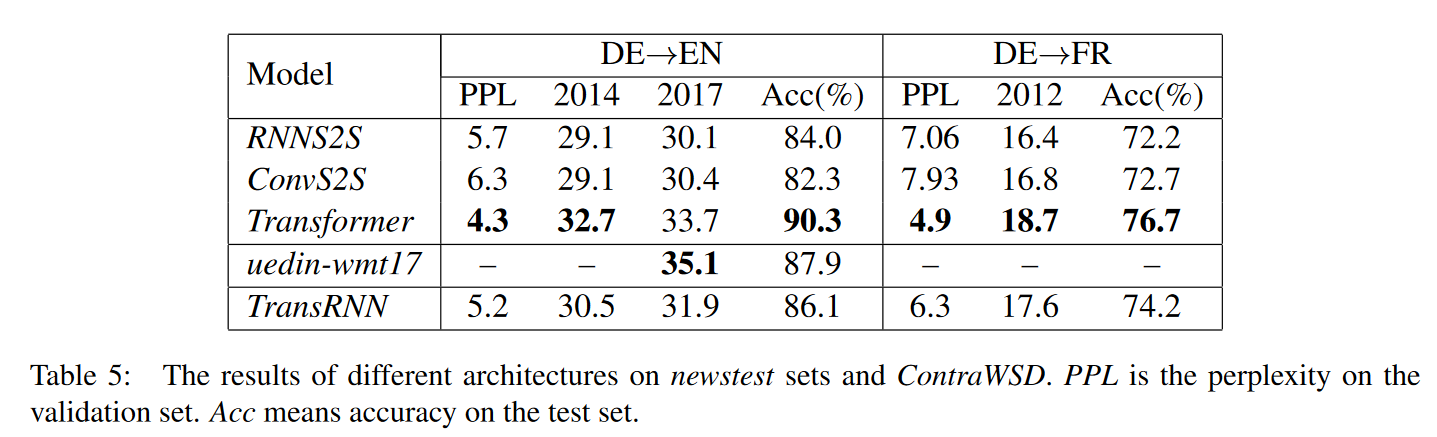
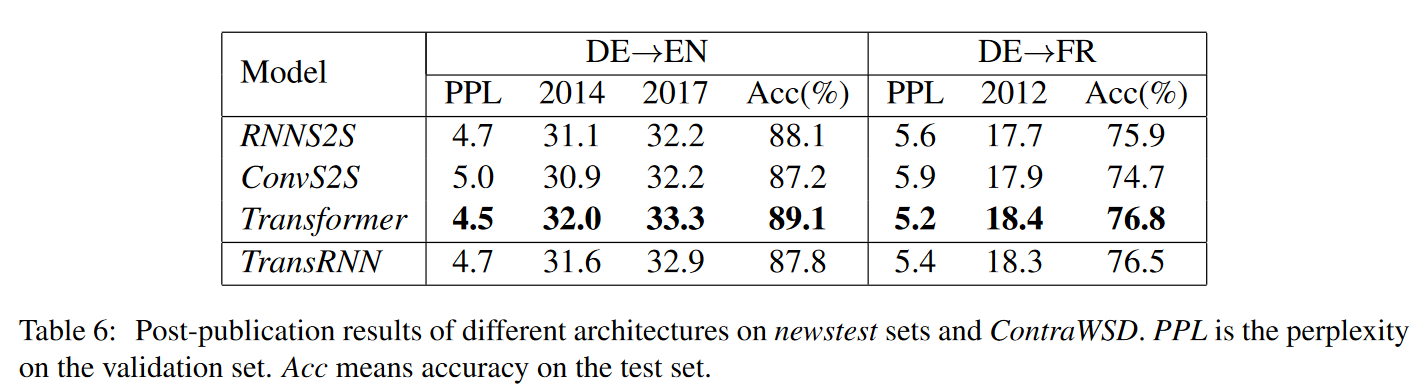
$Transformer>RNN\approx CNN$
通过实验,作者认为encoder和decoder两个组件的差异是使Transformer优于RNN的主因。因此,作者将Transformer的多重注意力层、多头注意力和残差前馈层等技术应用到了RNN和CNN上,发现在不改变其他参数的情况下能极大地改善RNN和CNN的BLEU和困惑度,只是在长距离的subject-verb-agreement上改善相对较小。
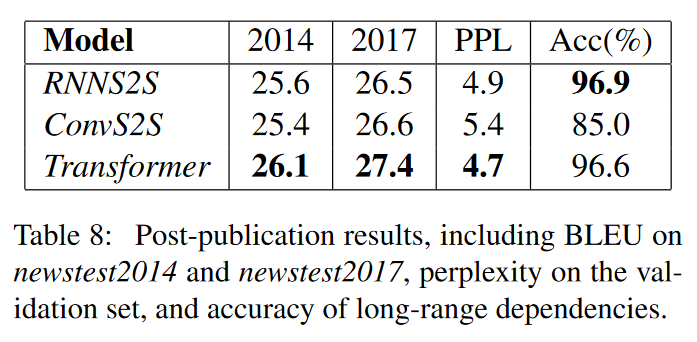
长距离特征捕获能力
- 短距离特征捕获
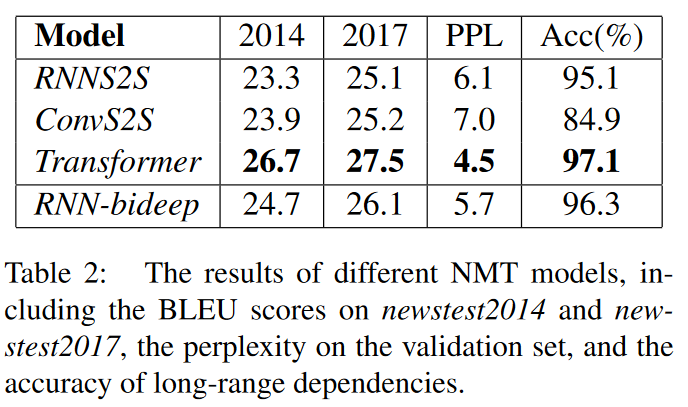
$Transformer> RNN > CNN$
- 长距离特征捕获
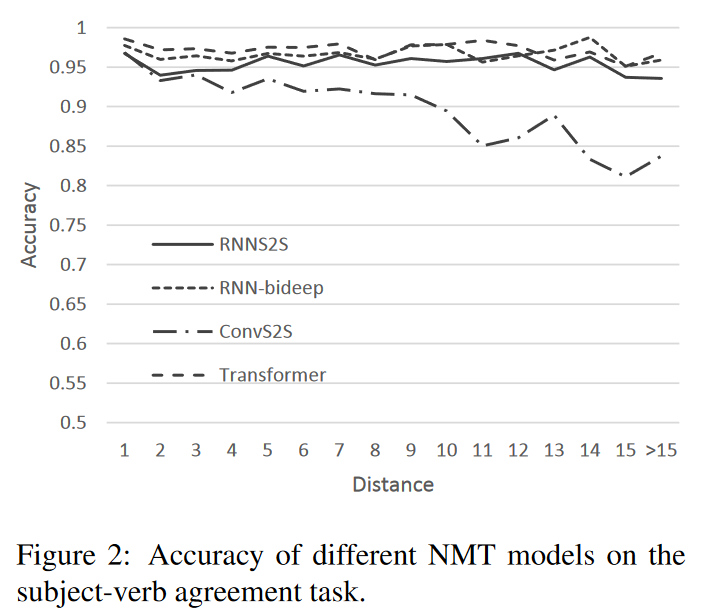
$RNN \geq Transformer > CNN$
作者经测试认为CNN表现差的一个主要原因是大小的上下文,其他原因主要由“CNN的Scale-invariance相对较差,但这点在NLP中十分重要”一假设解释。
任务综合特征抽取能力
作者提及这一结论源自某篇GPT论文,但没有提供具体信息,也没对“任务综合特征抽取”予以解释。
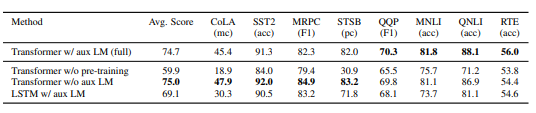
$Transformer>CNN>RNN$
运算效率
Transformer的Self-Attention层的时间复杂度为$O(n^2\cdot d)$,平方项为序列长度,而RNN和CNN的平方项为Embedding size,所以在大多数任务里Transformer的Self-Attention计算效率都高于RNN和CNN。
快手精排模型实践
这篇文章主要介绍了快手推荐系统在排序网络上进行的一些工作。
快手推荐系统
快手的推荐系统是一种类似于信息检索的方式呈现的,但是没有显示的查询。训练数据主要基于用户的行为日志和用户反馈,如之前提到的快手开源数据集。
推荐系统结构:
- 候选集
- 召回
- 排序
- 粗排
- 重排
- 精排
- 重排
快手的系统提供了多种交互体验,如主站发现页、主站精选、竞速版发现页、关注页、同城页、直播场景等。
CTR模型(个性化预估排序模型)& PPNet算法
主要应用场景:主站的双列交互
预测目标:用户点击概率
精排模型的主体普遍采用全连接网络,参数全局共享,能够捕捉全局用户和短视频的喜好模式,但显著问题是没有个性化。
- 失败的解决方案
- 全局网络+个性化局部网络
- 受ResNet启发
- 用stacking方法给每个用户一个specific网络
- 用户个性化偏置
- 受LHUC算法启发
- 每个用户都用user bias vector向量
- 问题
- 相当于给每个用户添加了非常宽的user ID特征,需要用户非常多的行为才会收敛
- 不稳定的网络会导致Embedding效果变差
- 短视频业务的冷启动问题严重,Embedding质量至关重要
- 缺少动态表达表征能力
- 全局网络+个性化局部网络
- 最终方案:PPNet(parameter Personalized Net 参数个性化网络)
- 在新活跃用户上取得了公司全年最大的留存提升
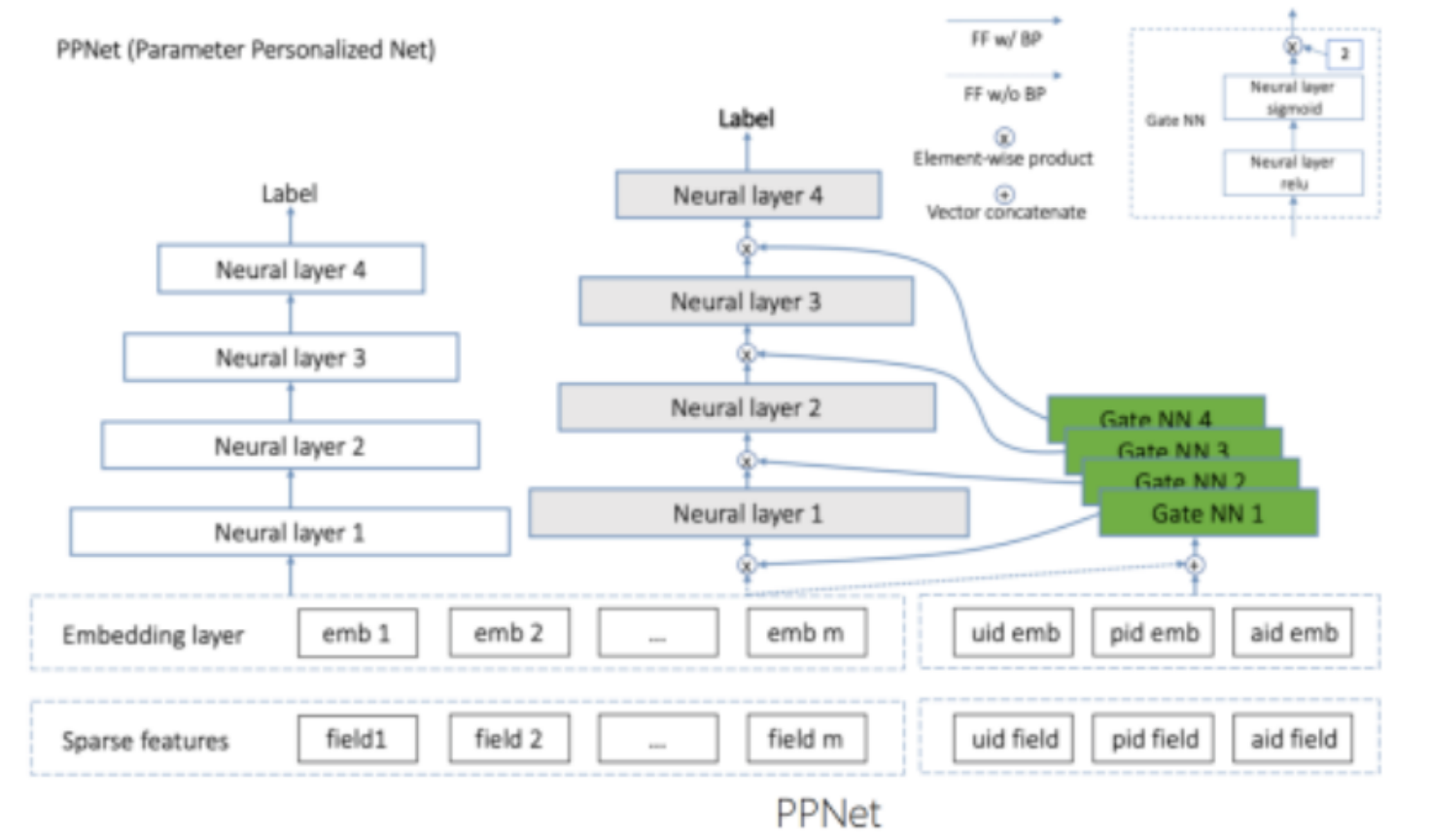
- 左边白色部分为base模型
- 保证Embedding收敛
- 右侧为PPNet部分
- 灰色部分:全局共享
- 绿色部分:gate网络
- 灰色部分包含输入层在内的每一层设计一个与用户和短视频相关的gate网络
- gate网络输入包括embedding layer和表征ID
- 对每条样本都可以产生不同的DNN网络
- 这部分作者并没有讲解具体的算法设计
- 在新活跃用户上取得了公司全年最大的留存提升
跨领域多任务学习框架
若每个业务或细分消费者单独占据一个模型,则模型数量会非常高,导致训练效率低、迭代效率低,不同业务数据不能互相提升。
特征语义对齐
- 删除无用特征
- 改正语义不一致特征
- 添加单列播放列表类特征,交叉特征
Embedding空间对齐
设计了一个gate网络直接学习映射关系,把当前用户来自不同业务的差异作为特征学习一个映射网络,之后直接对输入层进行映射,使Embedding的空间分布一致。
特征重要性对齐
不同特征在不同业务上的重要性不一致,针对不同业务用户视频学习特征级别的重要性。
个性化目标MMoE
在MMoE的基础上动态建模目标之间的关系,在task tower针对不同业务不同用户添加个性化偏置。
短期行为序列建模
业务背景:单双列业务下的用户行为序列差异
传统实践问题:用户行为特征比例高;序列建模历史相关性大于时序性;RNN表现不如sum pool
算法改进:EVA model
- A new Evolution of Video recommendAtion model
- encoder
- 对用户的(短期)历史序列进行表征
- 用户播放历史序列
- 用户交互label
- 对用户的(短期)历史序列进行表征
- 使用Target Attention替换transformer self attention部分
- self attention相对target attention没有显著效益,但计算量极大
- 降低计算复杂度
- 使用视频观看时间戳取代position embedding
- 模型更关注近期的观看历史行为
- encoder
长期行为序列建模
仅有短期行为序列的推荐系统存在信息茧房、缺乏推荐多样性的问题。快手团队在阿里巴巴SIM方案上提出了短视频推荐落地的建模方案。
我质疑信息茧房这一点(不仅是理论是否正确,也质疑在业界“信息茧房”能否给企业、消费者带来正收益),而且我认为这两个问题不能通过长期行为序列建模解决
挑战:不同目标的稀疏程度不同;超长序列建模困难
- Transformer方法
- 结构限制:过长的list上收敛性不好
- 复杂度高
- 阿里巴巴SIM方法
- 存储用户长期交互历史行为;双阶段检索
- GSU模块
- 返回用户TOP K的长期兴趣
- 检索方法:Target item检索
- 第一阶检索:user
- 第二阶检索:类目
- 检索方法:Target item检索
- 返回用户TOP K的长期兴趣
- ESU模块
- 基于GSU结果做MTA
- 快手场景下的问题
- 扩展性差:索引对后续迭代不友好
- 类目问题:短视频类目精准度和覆盖率问题
- 快手长期行为序列建模V1.0——基于tag检索
- 构建独立存储方法:依托AEP高密度存储设别直接存储用户超长行为历史
- 完善类目体系
- GSU检索采用回溯补全算法
- 使用最大路径匹配算法衡量相似度
- ESU采用短时Transformer方案
- 问题
- 路径长度不一致:检索的视频粒度差异大
- 节点距离:粒度过大
- 快手长期行为序列建模V2.0——基于Embedding距离检索
- 优先基于Embedding做一次聚类,同时计算距离
最后,通过优化该方案特征量扩展到千亿规模,参数达到万亿规模。
2022年深度学习在时间序列预测和分类中的研究进展综述
-
Are Transformers Really Effective for Time Series Forecasting?11
对比了Autoformer、Pyraformer、Fedformer、Earthformer、Non-Stationary Transformer在电力、交通、金融和天气数据集上的MSE和MAE
Autoformer:扩展并改进了Informer模型,具有自动关联机制更好地学习时间依赖性,旨在准确分解时态数据的趋势和季节成分
Pyraformer:引入了金字塔注意模块PAM
Fedformer:提出季节性趋势分解模块,旨在捕捉时间序列的全局特征
Earthformer:专注于预测地球系统,如天气、气候、农业等,提取了cuboid注意力架构
Non-Stationary Transformer:调整Transformer以处理非平稳时间序列,去平稳注意力和一系列平稳化机制,可用于上述模型的提升
但公众号作者提出的问题:仅对比了Transformer相关的模型,没有比对简单模型;仅测试了标准数据集
虽然有人认为前人已经知悉Transformer有着优异表现,所以没必要与其他模型对比,但作者认为这在很多现实应用中实际不成立,有些论文甚至认为很多情况下简单模型(如简单线性回归)效果能胜过Transformer 。未来Transformer在时序预测方面的前途仍然有很大的不确定性。【o(╥﹏╥)o】
-
Anomaly Transformer12
一篇将(无监督)Transformer应用于异常检测的文章,文章采用了5个真实世界的数据集进行评估,它在很多异常检测数据集上表现良好。
-
WaveBound: Dynamic Error Bounds for Stable Time Series Forecasting13
一种新的正则化形式,可以改进深度时间序列预测模型(特别是Transformer)
-
数据集Monash Time Series Forecasting Archive
包括维基百科流量、COVID-19、拼车、墨尔本行人等几个数据集。
-
可用于模型代码学习
AB实验知识大全
DataFun旗下智库设计的A/B Test的实验流程图,里面有好几个概念我不了解或有些模糊,以后找机会补习一下,而且我觉得里面很多东西都是具有极大地发展空间的。

基于沉淀数据的尾部流量建模方法
这篇文章主要是以风控为背景的,作者是360数科的资深风控模型专家郑伟东,是金融工程专业背景的。通读下来感觉讲的比较基础,不过有些实践的经历倒值得简单一看。
风控建模的四板斧:特征挖掘;样本分群;标签优化;算法提升。
目前信贷市场进入存量阶段,流量价格日益昂贵,各家机构从专注于头部客户及中部客户的经营转向尝试对尾部流量进行经营和捞回。但是尾部客户经营存在着风险过高、依赖市场上多头借贷数据构建的策略容易拒绝尾部客户、尾部客户的征信数据和其他数据缺失严重等多项重要问题,因此构建建模策略存在一定的困难。
尾部客户的主要来源包括:其他场频上管制禁申户、低额新户、授信的拒量、睡眠户、资金方的交易拒绝户、策略评判高风险客群等。
沉淀数据是产品在运营中积累的历史存量数据,它相比于三方资信在调查尾部客户上优势在于数据成本更低。(尾部客户的通过率低,所以数据成本高于头部客户)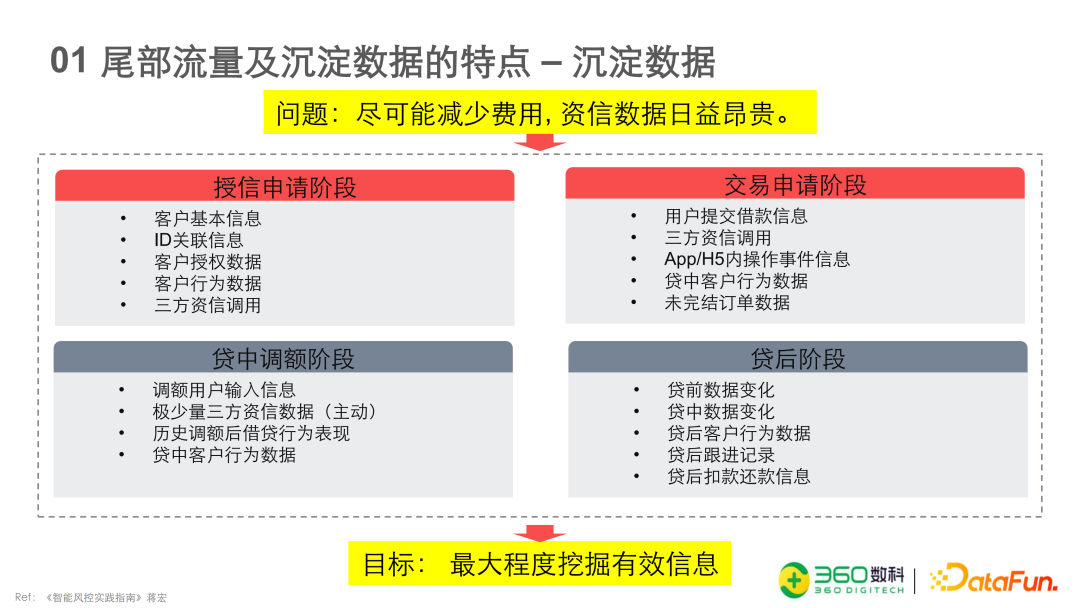
低通过率下的样本扩容
尾部数据捞回通过较低,所以样本量偏小,需要样本扩容。
- 使用共生融合标签
- 获取同一用户在本公司其他产品上的风险表现,将同期风险融合
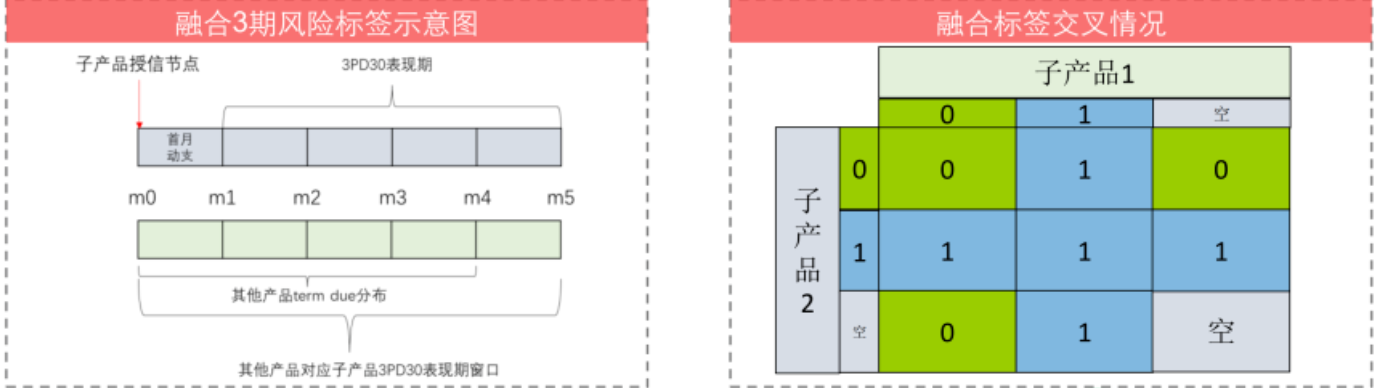
- 用户在本产品和其他产品授信后的行为存在风险命中即为风险命中
- 选择共生产品时要分析两产品的风险相关性大小
- 获取同一用户在本公司其他产品上的风险表现,将同期风险融合
- 放松坏人定义
- 长短期指标
- 建模时常用的Y指标是一期、三期、六期的风险指标
- 实践中发现六期的模型在三期的标签上识别度会高于三期的模型(目测主因就是数据量大,因为数据集是同期的)
- 数据时效性分群,Trade1为授信前30天在其他产品上有授信或交易申请操作
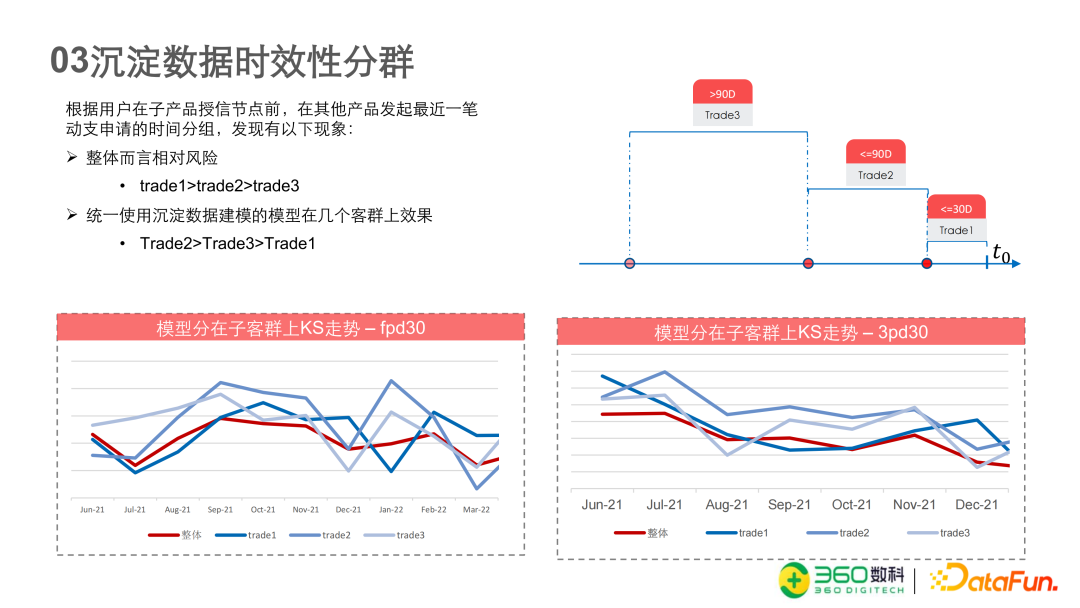
后面模型改进的方法很基础,没什么可看的。
阿里前端消费者体验优化实践
- 体验优化需求场景
- 跳失预测
- 交互偏好
- 智能(个性化)UI
- 鲸幕——UICook
- 淘宝前端内部智能UI平台:千人千面、个性化UI、推荐方案
- 鲸幕——UICook
淘宝内部营销(推广)频道
实践框架案例
-
问题定义
消费者进入频道后,对频道内容的访问是否有一定的偏好或者规律?
目的:若成立,则可依据消费者访问模式实现个性化设计,提高满意度
-
数据采集
单次用户行为:每个用户一次页面访问(PV)
-
数据分析
聚类
-
数据验证
将训练结果与线上数据对比验证
-
数据应用
承接策略&A/B Test
阿里智慧供应链实践:从“数字孪生”到“智能决策”
- 供应链决策的主要难题
- 数据层
- 数据来源复杂
- 分析层
- 解读困难
- 专业人员不足
- 决策层
- 科学决策(智慧化)
- 自动化决策(规模化)
- 数据层
阿里智慧供应链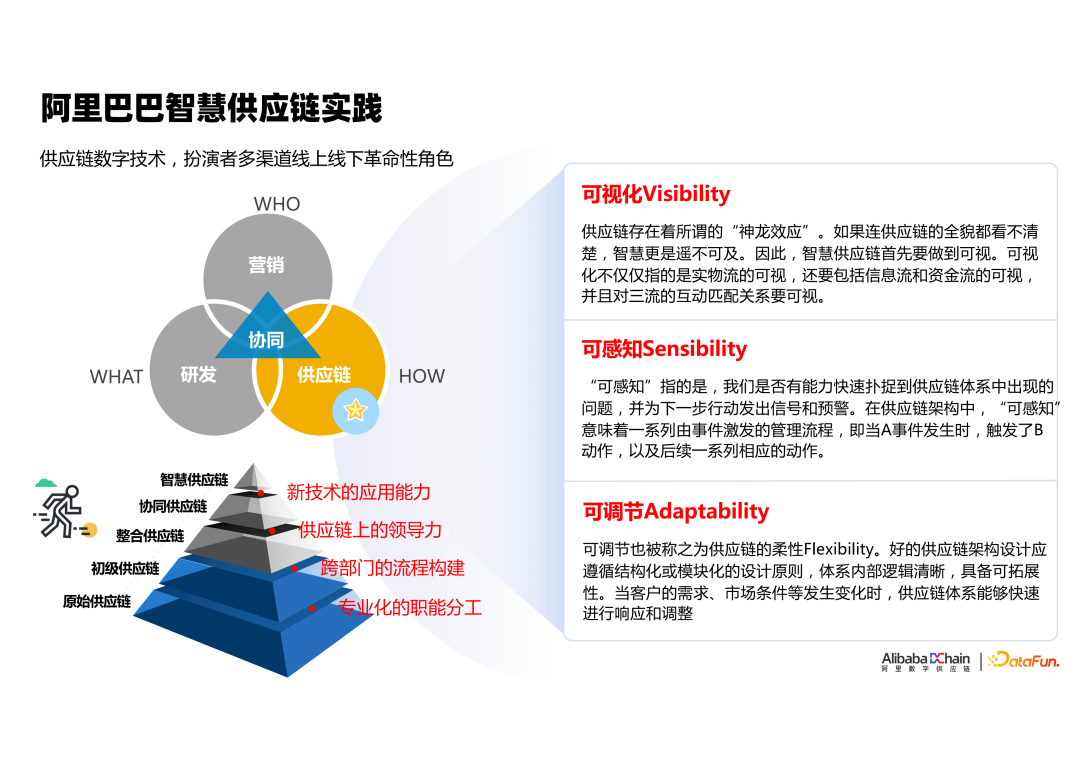
- 发展阶段
- 全渠道数字化(可视)
- 全链路数字化(可感)
- 包括采购、库存变动、履约、消费者旅程
- 异常识别、自动报警
- 智能决策(可调节)
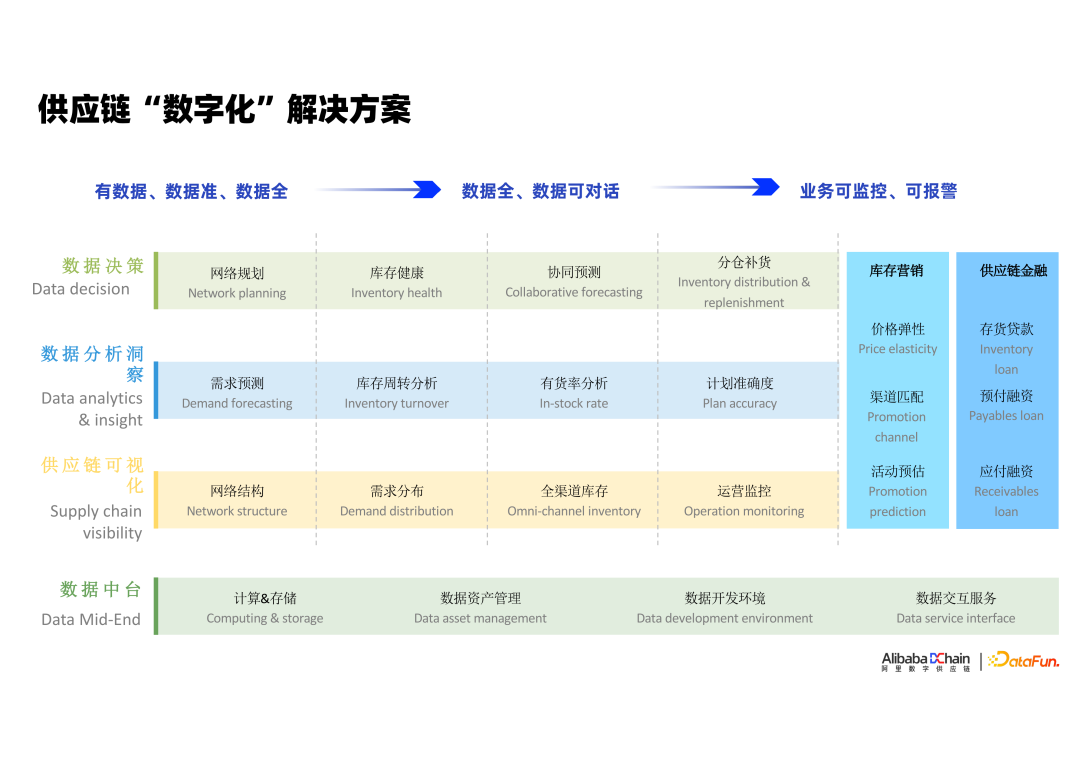
阿里数字化至智能化
阿里巴巴团队奖供应链智慧化进程划分为5个阶段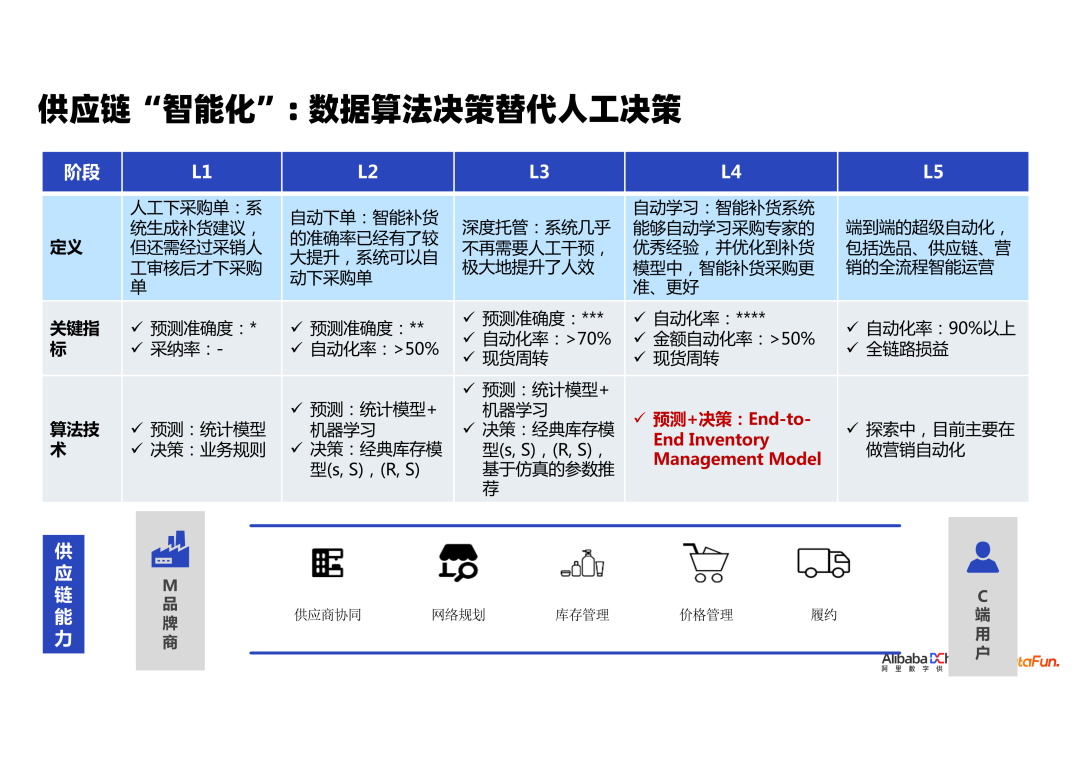
自动预测技术Falcon
- 传统数理统计预测方法
- EMA、ARIMA、Holt-winters
- 机器学习方法
- 深度学习方法
- 可解释要求
- 执行效率要求
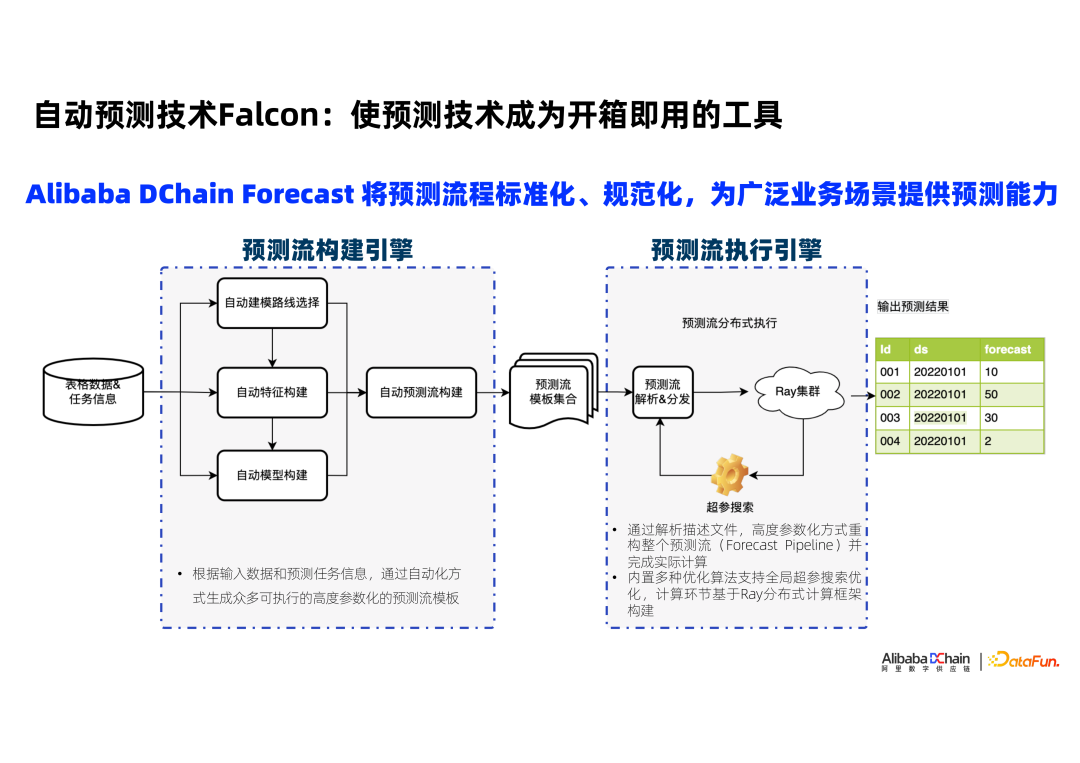

京东降本实践:供应链超级自动化探索与应用
京东的中小件供应链网络采用二层的拓扑网络
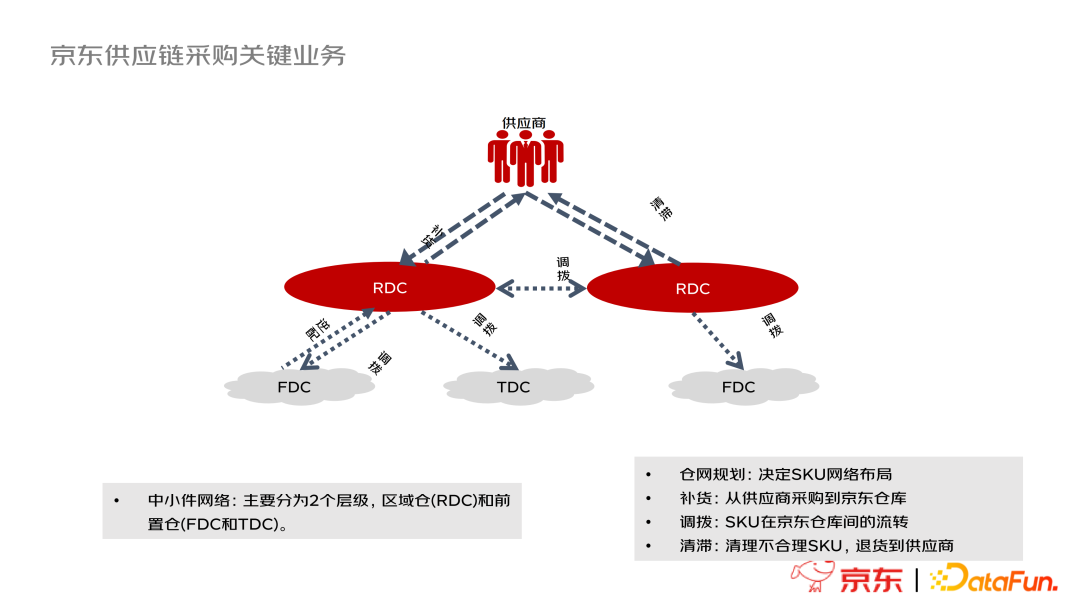
需求管理是整个供应链管理的核心和基石,包括需求智能预测和库存计划两个部分
需求智能预测
- 自动化最佳模型匹配问题

- 信息不对称问题
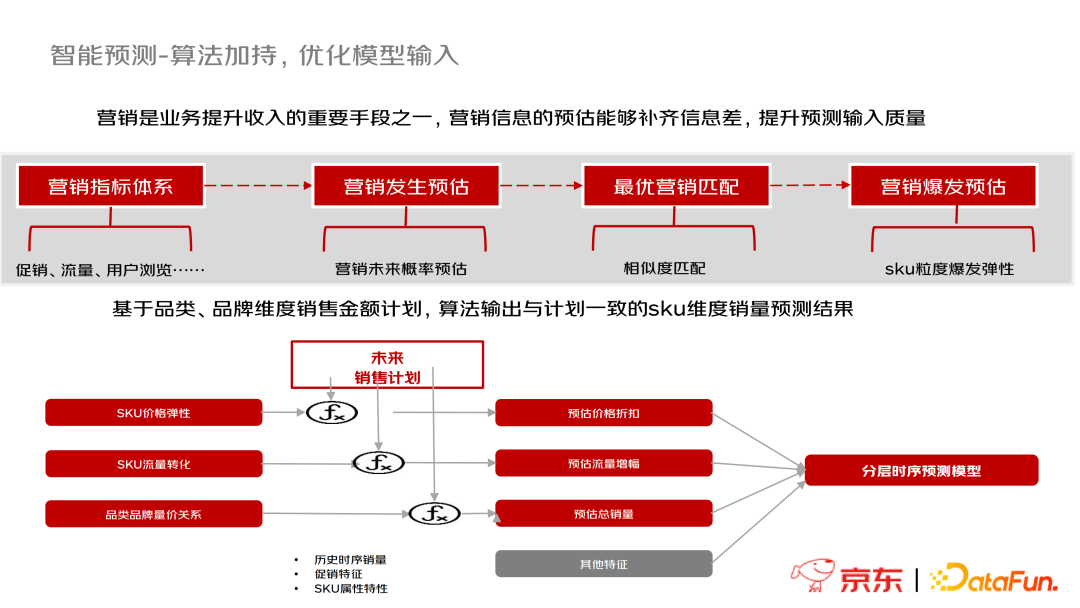
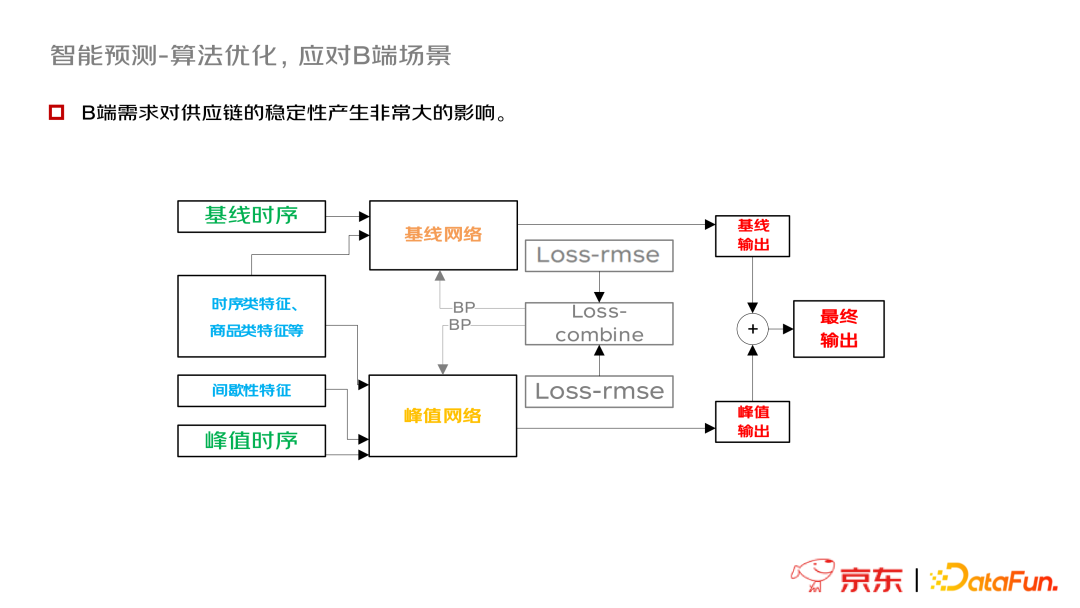
- 算法优化问题
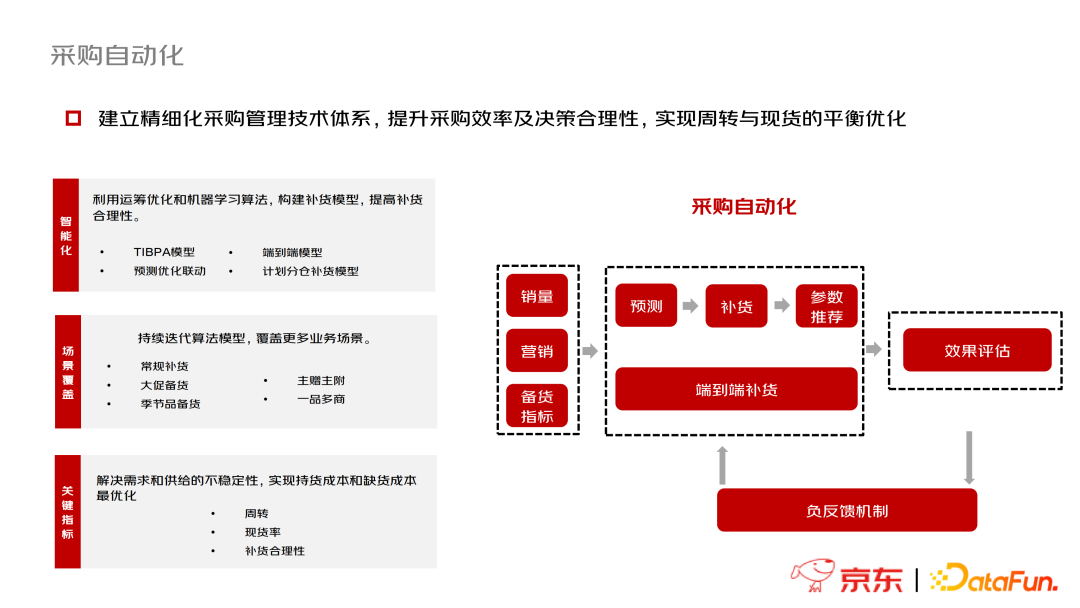
采购自动化
智能调拨
京东拥有8个一级仓——区域配送中心RDC,以及前置仓FDC和城市仓TDC两类二级仓。
R-F涉及调拨选品和模型计算。由于仓储成本,京东不会把所有商品都投放在二级仓,所以需要选品且考虑物流的稳定性;模型计算需要保证下游FDC的需求被充分满足且RDC的货没有被掏空。
R-R目的是全国库存平衡和缺货紧急支援,需要考虑被调入仓的需求、成本和履约时效。
F-R目的是考虑区域的库存平衡和低效库存清理。主要包括长库龄场景逆配、滞慢销场景逆配和库存平衡场景逆配。
清滞自动化
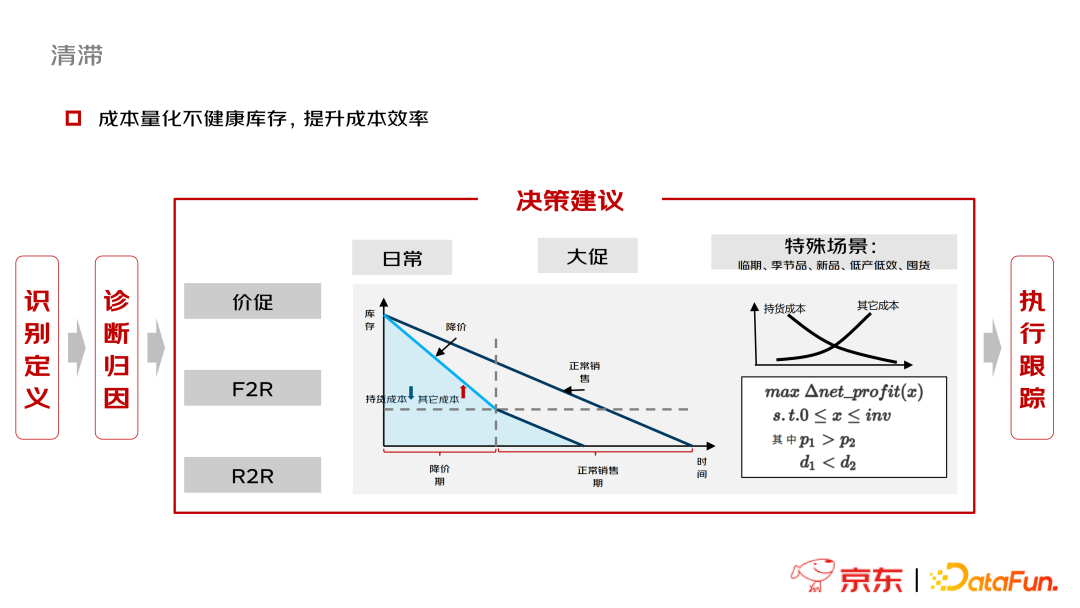
京东在清滞自动化方面的工作流程主要包括4个环节:识别定义(不健康库存)-诊断归因-决策建议-执行跟踪。决策建议是以场景划分的,包括日常、大促及特殊场景(临期、季节品、新品、低产低效、囤货)三类情境,给出的解决手段尚且比较简单,即促销、F2R和R2R,利用运筹优化技术最终实现收益最大化。
综合一体自动化决策
从各个业务环节寻求局部最优解变为寻找全局最优解。
供应链自动化发展阶段
和阿里巴巴一样,京东也设计了供应链自动化的发展阶段设想,但区别是阿里主要从模型效果提升角度出发,而京东则更关注业务整合程度的提升。从我个人的观感上,我认为即使阿里提出了量化指标和一些技术路径,但可能在实际构建中会发现一些过于理想化的想当然,相较而言我觉得京东的路线更务实一些。
Jina-AI:从神经搜索到多模态应用
此处神经搜索特指搜索系统中使用的神经网络模型。而神经网络相比于传统搜索方式,其最大的优势就是可以方便地对不同模态的数据进行融合。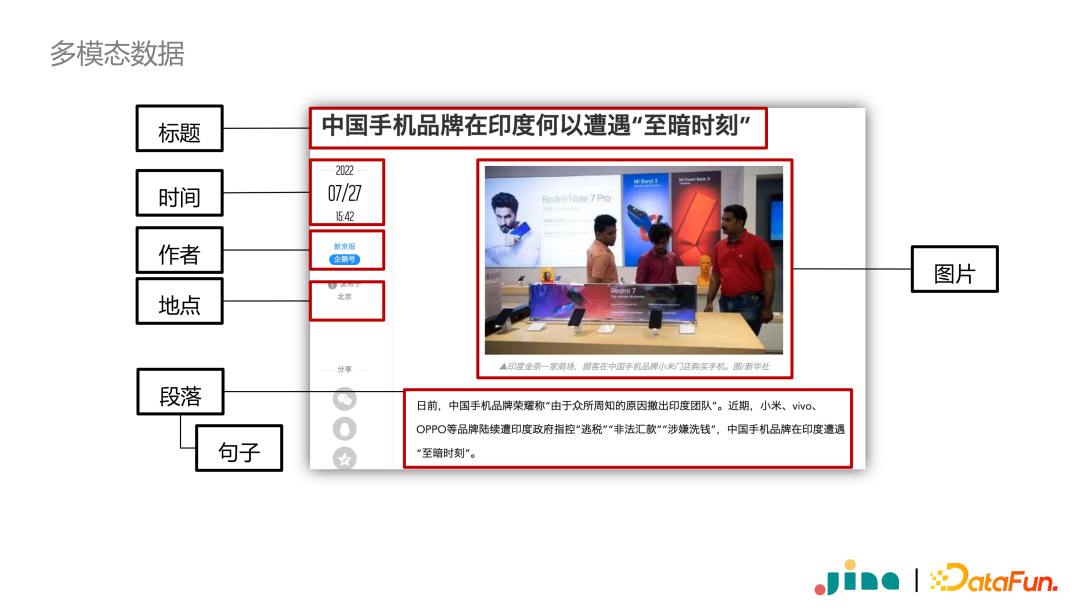
多模态数据两个重要特征:包含多个模态;嵌套结果
- 多模态研究厂商
- OpenAi
- DALL·E (DALL·E2)
- CLIP
- 微软
- 谷歌
- 百度
- 悟道
- OpenAi
多模态数据存储
利用python dataclass可以简单实现。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
from dataclasses import dataclass
from typing import list
@dataclass
class NewsArticle:
content_picture: str
title: str
paragraph: list[str]
meta: dict
article = NewsArticle(
content_picture='https://xxx',
title='title',
paragraph=[
'目前,。。。',
'近期,...'],
meta={
'author':'作者',
'ip_info': 'bj'
}
)
实际中,以CLIP模型为例,第一步是将图片下载本地,再进行加载等。多模态数据的预览功能通常需要自己实现。
《管理世界》丨樊纲:比较优势与后发优势
这篇论文我只是当做日常读物看待,寻找有趣点,不是论文研读
落后国家处处落后,想要发展必须发挥相对优势或把劣势转化为成本竞争的优势,从而实现增长。相对优势主要指“比较优势”和“后发优势”。
“比较优势”主要指要素丰裕度比较优势利用(H-O模型)。落后国家和发达国家的差别就在于“要素结构”,落后国家拥有“初级要素”,缺乏“优质要素”。落后国家可以通过初级要素比较优势发展劳动密集型产业,获取经济增长。但这并不一定能够使落后国家拥有比发达国家更高的增长率,实现发展经济上的收敛。一方面,初级要素的初始价格决定了比较优势能够带来多大的比较利益——即在给定生产技术条件下,按现行价格水平使用要素在国际比较中成本优势的大小,而落后国家的初级要素的初始价格未必足够低。另一方面,初级要素的丰裕程度决定了比较优势的可持续时间,落后国家可能难以持续充足的时间。
“后发优势”指后发国家在工业化进程中可以直接利用发达国家已经发展的技术、知识和商业模式,从而节省大量的研发成本和试错成本,实现快速增长。后发国家通过吸收发达国家技术扩散,通过知识溢入增加知识存量,提升要素结构发挥后发优势。
业界动态
Hanover Research: The State of Market Research
以数据为依据的慎重投资获得了回报:依赖市场研究的公司比那些不依赖市场研究的公司更有可能增加销售额、扩大市场并提高客户保留率,多数商业领袖预计增加市场调研预算
利益关联:该报告由美国市场调研公司撰写
调研问题:美国商业领袖如何使用市场研究增加销售额,留存客户并扩大市场份额,进而实现投资回报率ROI的增长?
调研背景:在三年疫情的冲击下,美国商业领袖们经历了劳动力短缺、供应链反应迟钝等问题,这些要求企业必须快速适应环境并及时做出反应。如今,在冲击的余波下,具有前瞻性的企业已经从救火模式转变成扩张性的增长策略。因此,如何选择正确扩张领域,获取ROI是这些企业目前面临的棘手问题
调研对象:399家美国商业领袖企业的管理层员工,其中322家采取了市场调研行动(79%),77家没有
调研方法:线上问卷(质性)+第三方卖方专家小组+受访者资质审查
调研发现:95%的企业(n=255)通过市场调研获取正的ROI;91%的企业(n=118)认为市场调研增加了销售额;89%的企业(n=122)认为市场调研增加了客户留存率;69%的企业(n=399)计划在2023年追加市场调研预算
调研人员没有解释样本大小不一问题
调研结论:使用数据导向市场调研的企业比其他企业更可能增加销售额、扩大市场份额并提高客户留存率
-
市场调研有助于解决企业目前面临的主要挑战
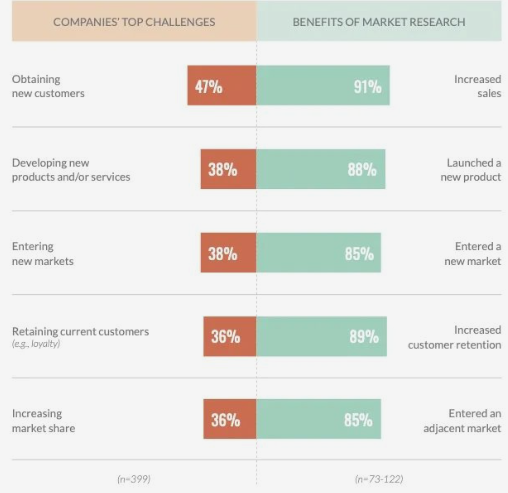
未解释两边样本不平衡问题,有操纵数据嫌疑
-
相比没有采取市场调研问题的企业,采取市场调研的企业在销售额增长、增加客户留存、新产品/服务发售、进入新市场、进入临近市场的表现都更优
相关关系不是因果关系,可能存在严重内生性问题,结论不可靠
-
总的来说,多数企业认可市场调研具有三项好处
- 深入理解市场
- 识别机会
- 揭露风险
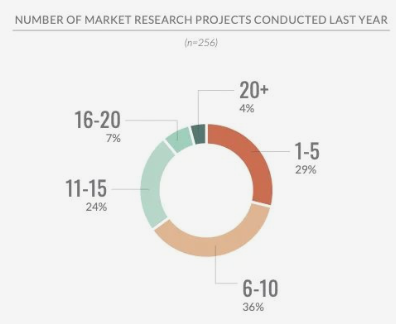
256家企业分享了它们在2022年的市场调研频率,其中多数开展了1~10项市场调研。
同样,研究人员没有说明剩余的66家企业的情况,但对结论影响有限
| 61%的企业开展了市场调研 | 59%的企业开展了产品生命周期调研 |
|---|---|
| 市场进入策略 市场份额识别 竞争分析 市场细分 市场趋势分析 并购机会 |
产品生命周期管理 产品研发 产品组合评审 包装设计 定价策略 渠道战略 销量预测 |
| 58%的企业开展了消费者体验调研 | 55%的企业开展了品牌战略调研 |
| 用户画像 消费者细分 消费者旅程 购买路径 消费者决策过程 消费者需求评估 消费者聆听 |
品牌资产 品牌知名度 品牌感知 品牌跟踪 品牌发展与定位 品牌重塑 内容营销开发 |
被调查企业采用的调研手段
- 数据分析和建模——68%
- 问卷调查——63%
- 二手数据研究——55%
- 焦点小组——51%
- 购买辛迪加数据——48%
- 深度访谈——40%
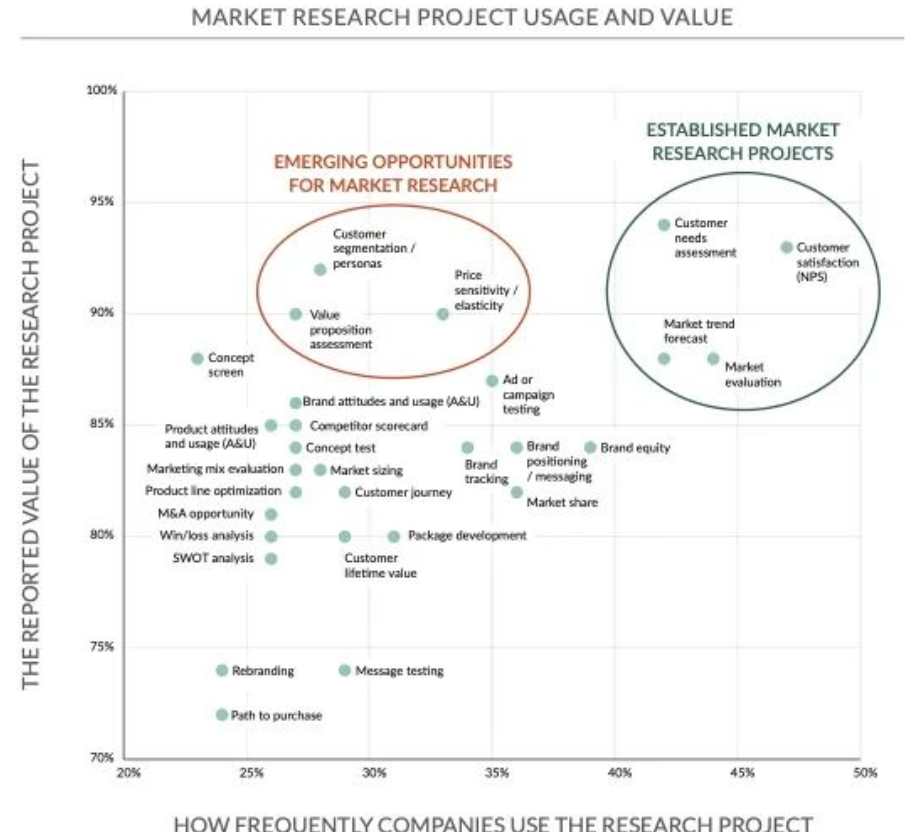
现有企业调研项目频率与调研项目价值的关系图
Deloitte:2023中国消费者洞察与市场展望
调研问题:后疫情时代,消费品与零售行业的消费者消费理念和行为习惯变化
调研日期:2022年11月
调研对象:根据七普人口结构数据设置配额,收集有效样本2000份,覆盖中国301个城市/自治州,受访者年龄18-73岁
如何配额?通过线上问卷实现配额?73岁为何能参与线上问卷?在我的问卷经历中,线上问卷受访者一般不会超过60岁
从附录上看,样本明显有偏
调研方法:线上问卷
调研结论:消费者回归消费理性;追求悦己体验;拥抱多元创新;绿色可持续消费;追逐技术跃升
-
2021年城镇居民人均可支配收入为47412元,实际增长7.1%;农村居民人均可支配收入18931元,实际增长9.3%
-
2022年中国居民人均储蓄提升至35%以上
-
2022年1月-11月实物线上零售额占社零比重27.1%
- 这个增速优点超乎想象,疫情前有美国学者认为比重存在天花板8%,虽然我们都不认可这个数值,但天花板的存在还是有一定理由的。然而目前看数据中国的比重持续快速上升,还没有减速的趋势,而美国在疫情后也跃升至20%左右,很难说这个天花板到底是多少,甚至不知道到底有没有天花板
-
-
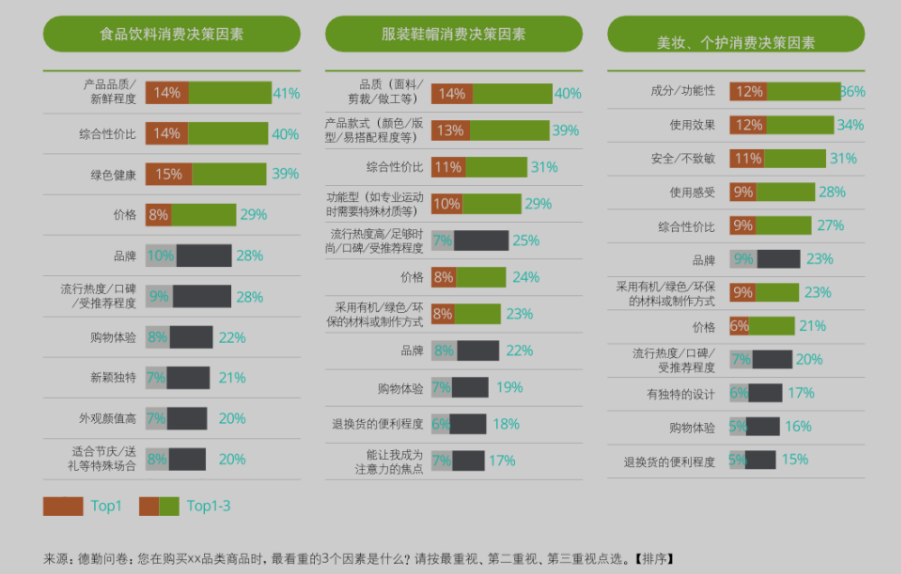
61%消费者汇报会进行比价(比较成本降低);59%的消费者会主动寻找优惠券
-
-
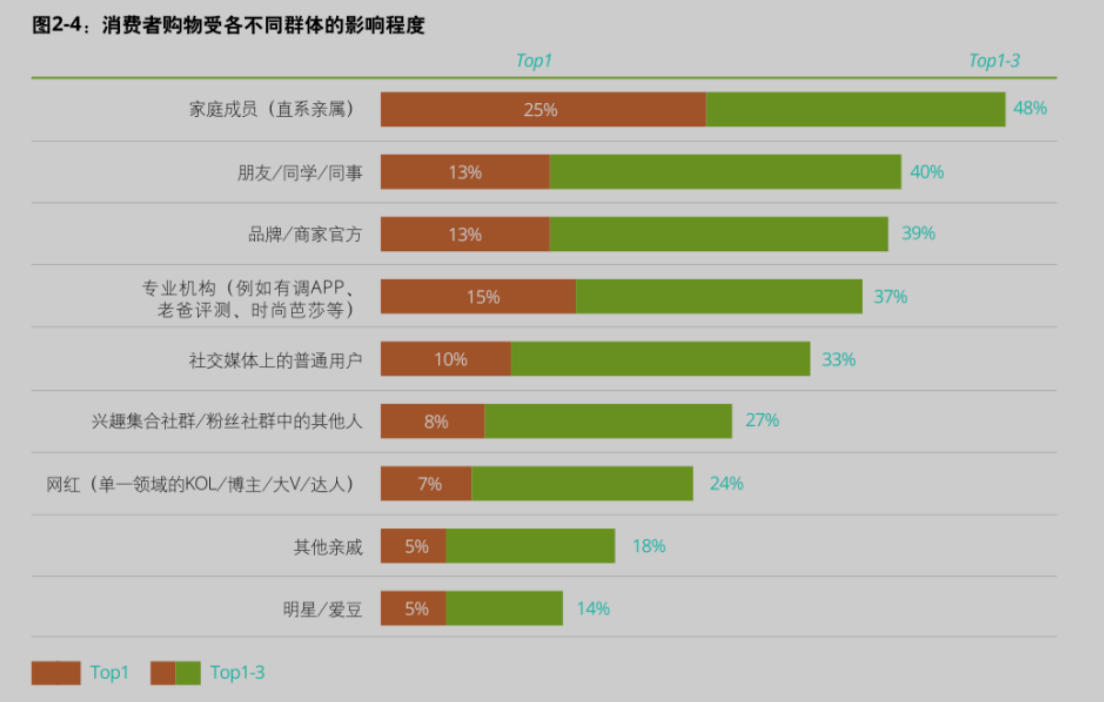
消费者信息主要获取来源以此为搜索引擎、直播间、公众号&短视频等社交平台、电商平台、品牌官网、亲友推荐等;其中13%认为对决策影响最大的信息渠道是实体门店体验,13%为短视频,12%电商平台,11%品牌官网,10%社交媒体
这题选项不符合MECE原则,有一些混乱
-
51%的消费者会在社交媒体分享购物体验,仅13%消费者不会分享
-
过半消费者比较积极地希望用个人信息换取个性化服务,但同时大部分消费者也会注重保护个人隐私
AARP: 2023年技术趋势和50岁以上群体
AARP美国退休人员协会是美国规模最大、历史最久的为老年人呼吁倡议的非盈利组织。
- 过去四年,78%的老年人将技术作为生活的一部分
- 71%的老人在2022年进行了科技产品购买,用于替代、升级和家用
- 老年人在2022年平均花费$912用于科技消费,较去年增长11%
- 提升和监控健康是美国50+群体使用科技的主要目的之一
- 42% 50+群体认为科技可以帮助他们获得健康生活
- 约20%对使用科技辅助减少焦虑、悲伤、修正坏习惯、获取更好睡眠感兴趣
- 过半的照料者对科技辅助感兴趣
- 68%的50+群体不相信目前的科技产品设计考虑了他们
- 50+群体(n=2095)在常用的科技如智能手机、智能电视、写字板上使用率与19-49岁群体(n=884)相差不大,但在可穿戴设备、家庭助手等方面有较大提升空间
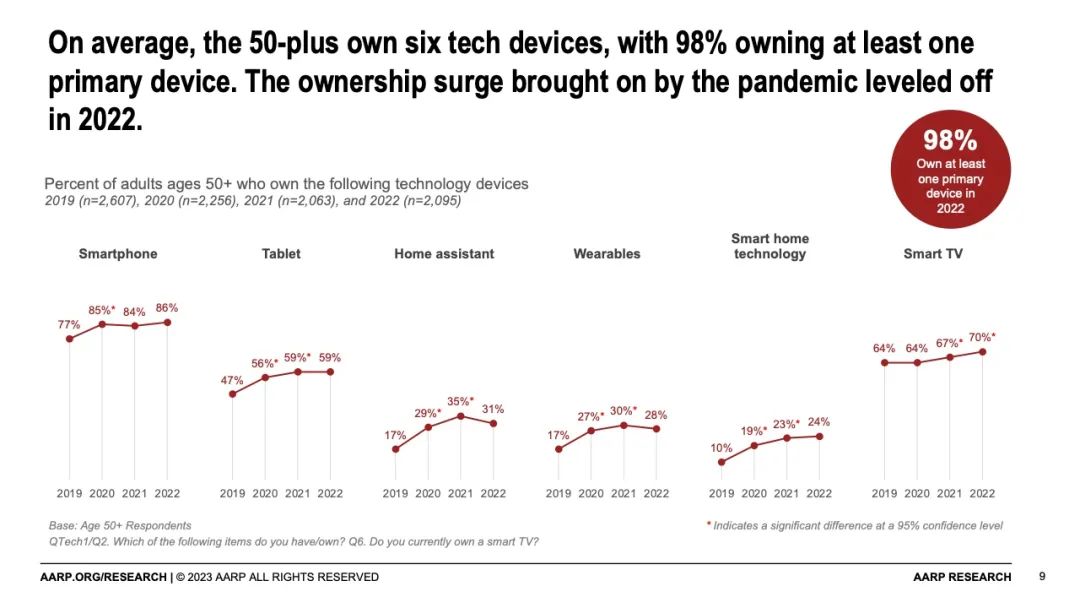
- 50+群体为自己购买科技产品比例逐步提升
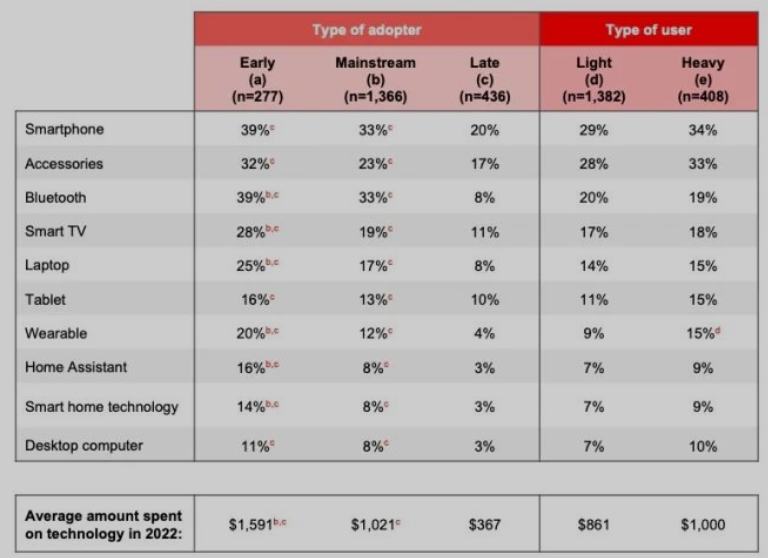
- 50+群体的购买动机是以新换旧,家用添新和赠礼也是重要动机
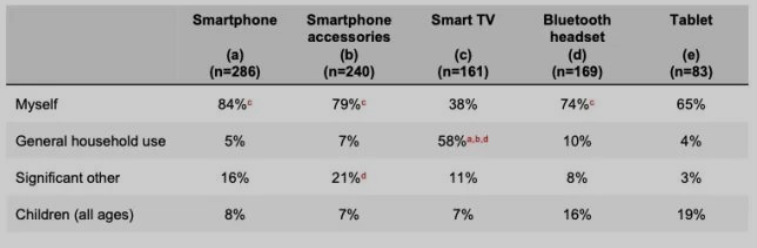
- 疫情之后,50+群体对部分类型产品使用率下降,但报告未予以解释
研究报告丨复旦管院:每家公司都是一个媒体?企业媒体化趋势研判
复旦管院与弯弓研究院组成项目组对12个行业头部企业的企业媒体化进行研究,出品《2023企业媒体化发展研究白皮书》。
21世纪,随社会化媒体兴起,Tom Foremski提出“每家公司都是一个媒体公司”的观点。
调研方法:文献研究、访谈、场景体验
调研对象:餐饮、零售连锁、快消品、地产文旅、耐消品、化妆品、母婴/大健康、鞋服、企业、酒水茶叶10个行业100家代表性企业
企业媒体化有不同的分类和布局;CBR(沟通、交易、关系)是企业媒体化的通用价值模型;技术和内容是提升价值感知的重要手段;用户和平台是重构后链路价值的根本
- 企业媒体化三种模式
- 全域均衡
- 企业特征:受众广大;高频消费(反复触及);利润高
- 触点构建与维护会增加运营成本
- 需要有效协同的触点、流畅的链路和高效衔接
- 一主多从
- 企业特征:细分市场;技术特征明显;用户人群精准组合
- 微信主导
- 53%企业媒体化矩阵以微信为核心
- 企业特征:行业规模不限;成本低;营销链路完整;营销路径单一
- 全域均衡
模式选择的影响因素:行业消费特征、市场竞争度、消费者偏好、上下游伙伴相对力量、企业生命周期阶段、资源与能力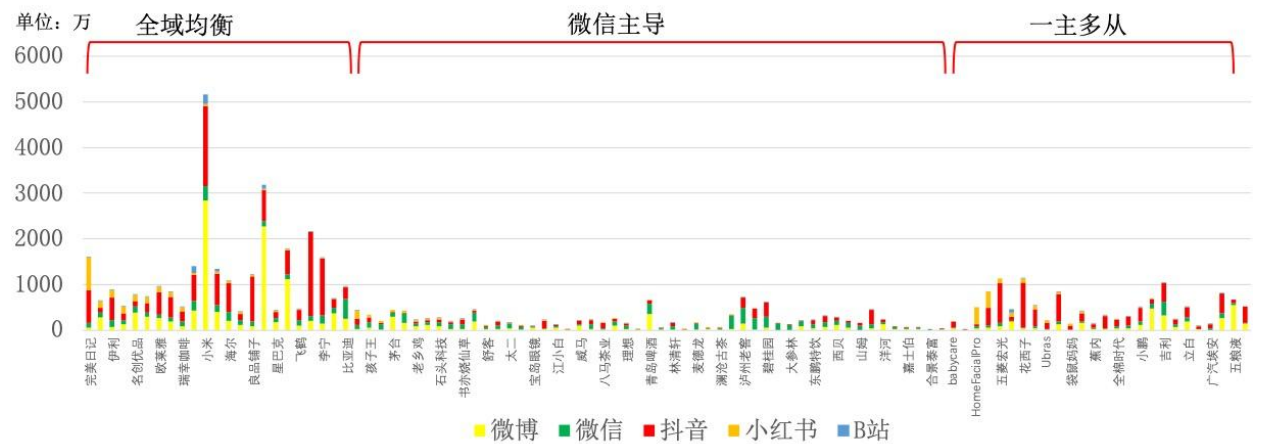
纵轴是投入资金,我认为统计方式和类型划分还有待商榷
目前消费者都是“流动消费者”,消费者旅程变为“无限的体验”过程,消费者兴趣变化加速
七大社交媒体平台
- 微信
- 私域营销闭环
- 抖音
- 全域兴趣电商——推荐算法
- 新浪微博
- 话题发酵快;内容传播广;内容多元
- 小红书
- 女性占比70%;用户特质鲜明
- 内容输出模型:明星官宣-多头KOL造势-KOC铺量-素人自发跟帖
- 快手
- 社交、社区的半熟人分发模式
- B站
- PUGC;人群圈层明确
- 垂类发展迅猛
- 知乎
- 精准链接;品牌可有效缩短、简化用户消费决策链路
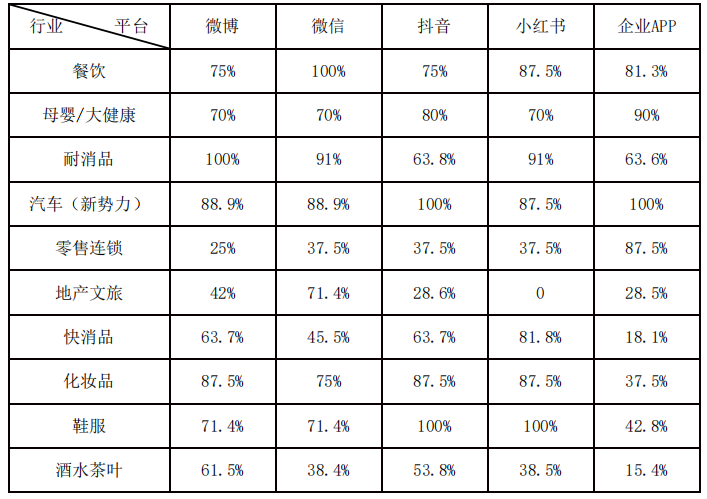
没有看明白计算规则,大致是粉丝用户数比重之类的
企业媒体化CBR价值模型
阿里巴巴AIPL(认知、兴趣、购买、忠诚)消费者运营理论
AIDMA模式向AISAS模式转变
2015年麦肯锡对消费者决策旅程CDJ模型进行升级,构成包含“购买环”、“品牌忠诚环”两部分,考虑-评估-购买-体验-崇拜-联结6阶段的模型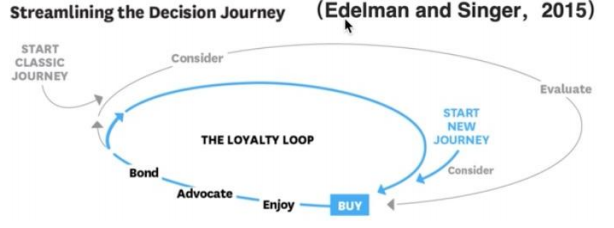
在CDJ模型基础上,调研组构建了沟通-交易-关系CBR价值模型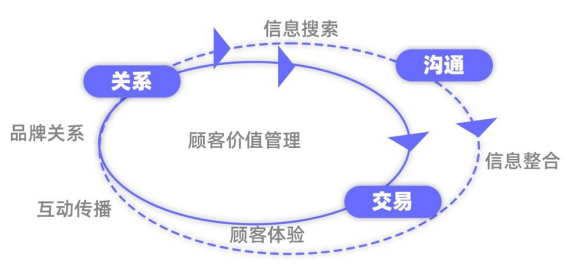
《财富》发表:ChatGPT的内幕故事
OpenAI公司成立于2015年,在其成立了七周年之后,其CEO Altman在Twitter上发文:“今天我们推出了ChatGPT,尝试在这里与它交谈。”并附上了免费注册连接。让我很感慨地是如今越来越多的产品引爆是从社交媒体上一则简短的推文或视频开始的,传统的新产品导入路径已经完全被颠覆。
Netscape Navigator时刻
网络浏览器出现于1990年,但直到1994年Netscape Navigator的出现,大多数人才了解到互联网;MP3播放器出现的时间同样很早,在直到2001年iPod问世才引发数字音乐革命;在2007年Apple推出iPhone之前也有智能手机,但没有人关注智能手机APP。
2022年11月30日,LLMs迎来Netscape Navigator时刻,ChatGPT达到了引爆点。事实上,ChatGPT并非是第一个对话类型的机器人,如微软小冰等早已被人们熟知。但与之相比,ChatGPT最突出的特点是它首次为大众用户提供了可以长时间、流畅地对话,完成要求任务的智能应用场景,因此即便它的答案并非完美也不准确,也能形成了强大的社交货币。
商业模式一波三折
这篇文章最让我感到惊讶的是ChatGPT的发展历程中一波三折的阶段并不是发生在技术环节,而是商业模式的调整上。
首先,从公司层面上,最早OpenAI是一家致力于学术研究的小型非营利性实验室,就如它的名字一样,OpenAI致力于开发开源的人工智能模型,但如今通过内部转型,OpenAI的首要目标已经从纯科学项目转向了商业项目。这里不得不提到其联合创始人兼CEO Sam Altman,一位以商业头脑而非工程能力知名的连续创业科技企业家。他痴迷于开发被称之为人工通用智能的计算机超级智能这一宏大理想,并将以ChatGPT为代表的LLMs视作这一使命的第一步。虽然Altman从一开始就参与了 OpenAI,但他直到 2019 年5 月才成为 CEO,并推动了OpenAI的商业化转型。Altman利用他的商业本能和对科学推动的大想法为实验室筹集了数十亿美元的资金,并将曾经广泛的研究议程缩小到以NLP为核心的产品导向开发。此外,Altman也彻底推翻了OpenAI做开源AI的初衷,放弃发布所有研究成果和开源代码的承诺,如今OpenAI的高级模型只能通过API接口获取,从而保障了OpenAI的知识产权和收入来源。在这一场内部变革中,超过十名OpenAI的研究人员与公司决裂。
在产品层面上,或许几乎没有人能想到目前如日中天的ChatGPT曾几乎被扼杀。当ChatGPT准备就绪后,OpenAI 让 Beta 测试人员使用ChatGPT,但结果并不是想大家想象的那样被接受,测试人员不知道他们应该与ChatGPT说些什么。这样的一个调研问题或许是源于技术人员对产品过于熟悉导致的。因此,有一段时间,OpenAI 试图构建专家聊天机器人,以帮助特定领域专业人士,这也是我非常看好的发展方向。但这项努力也遇到了问题,部分原因是 OpenAI 缺乏训练专家机器人的正确数据。实际上,我们今天看到的ChatGPT更像是OpenAI孤注一掷地投放在市场上,并没有人成功预测它的火爆。
资本运营与市场竞争
ChatGPT的开发过程需要大量的资金,而正如上文提及的Sam Altman为OpenAI筹集了大量的资金,其中微软于 2016 年开始与 OpenAI 合作,并与这家初创公司建立了战略合作伙伴关系,投资10 亿美元,后来又不断追加。微软通过将OpenAI的DALL·E、ChatGPT等模型接入自己的Azure框架获取利益。目前,依据OpenAI的设计,第一批投资者在收回初始资本后,微软有权利获得OpenAI 75%的利润,直至它收回投资的130亿美元,之后等到微软赚取920亿美元的利润后微软的股份将将至49%,同时其他投资者和员工也可以获取OpenAI 49%的利润。如果上述的利润全部满足后,OpenAI将回归非盈利基金会。
然而上述的内容更多只是理想的商业设计,这里面巨额的资本投入是真实的,但利润方面却只是预估的。迄今为止,OpenAI收入相对较少,亏损非常严重,仅2022年的净亏损总额预计就高达5.45亿美元。不过好消息是这家公司终于有可以出售的产品了。
但与此同时,我们也不得不考虑引爆了LLMs的ChatGPT能否长期的占领市场。为了应对OpenAI和微软对搜索市场的携手冲击,谷歌宣布了内部“红色代码”,以回应 ChatGPT,而百度一言也即将推出。作为先行者,免费提供 ChatGPT 让 OpenAI 能够收集大量反馈,以帮助改进未来的版本。但伦敦人工智能公司Faculty的创始人兼首席执行官Marc Warner表示:“从历史上看,我们倾向于看到这些非常通用的算法不足以让一家特定的公司获得所有的总体回报。”例如,人脸和图像识别技术最初是由谷歌和英伟达等科技巨头开发的,但现在已无处不在。
正如文章所说:“OpenAI 可能有一天会发现,就像 Netscape 短暂的浏览器统治一样,它的突破打开了一扇通往未来的门,而这扇门并不属于它。”
风险与缺陷
上面这句话并不仅仅可以用作商业竞争上,在社会问题上也同样适用,而且这里存在的阴暗面更为严重,或许用叶文洁的“我点燃了火,却控制不了它”表示更为贴切。
运行产品是发现人们想要如何使用和滥用技术的唯一途径。在实践中, 直到OpenAI看到人们用它编写代码,他们才发现GPT-3 最流行的应用程序之一是编写软件代码。同样,此前OpenAI 最担心的是人们会使用 GPT-3 来制造政治虚假信息,然而事实却是最普遍的恶意使用是制造广告垃圾邮件。通过将制造虚假信息的成本降低到几乎为零,像 GPT-3 和 ChatGPT 这样的系统可能会引发一波虚假信息的浪潮。例如Stack Overflow 已经禁止用户提交由 ChatGPT 编写的答案,因为该网站被看似合理但错误的答案淹没了。与此同时,科技新闻网站 CNET 开始使用 ChatGPT 生成新闻文章,但后来发现许多文章由于事实不准确而不得不更正。
与犯错误相比,ChatGPT编写准确的代码才是真正的风险。因为这意味着网络犯罪的技术门槛急速下降,ChatGPT已经初步可以让一个完全零代码基础的人实现网络犯罪。当人人都有枪的时候,它或许早晚会被打响。未来我们不得不利用越来越快速的技术迭代来减少犯罪的发生。
技术技巧
Python库:plottable高度个性化表格
Python库:pynimate动态条形图
Python库:PySnooper函数级Debug
Slogan: Never use print for debugging again
用于懒得设置带有断点和监控的监视器的场景。
使用方法:在函数前添加@pysnooper.snoop()装饰器即可。
会以日志的形式输出变量值变动和运行时间等信息。
娱乐
行星奇点:规模法则解释为何外星文明隐匿于“黑暗森林”14
文明要么因为过度消耗而崩溃,要么因为重新引导自己优先考虑内稳定
地外文明未必刻意藏匿自身,更可能在发展中要么崩溃,要么更宅
呈现超线性增长的系统(城市、科技文明)会导致“奇点”危机,其最终结果是在有限时间内,(人口、能源)需求趋于无限,系统成员必须越来越频繁地通过创新和“重置”推迟系统的崩溃。
在这个角度,假设一个行星文明发展到几乎全球联通的阶段就会面临“渐进耗竭”的最终危机,即奇点之间的时间尺度变得比创新的时间尺度小。若一个文明了解自身发展轨迹,则它将有一个时间窗口进行干预,即在不限制增长的同时有限考虑长期内稳态和人类福祉。
据此,出现了费米悖论的一个新的解释——文明要么以扩张为目标,最终因过度消耗而崩溃;要么选择重新引导自己优先考虑内稳态,从而难以被远程探测。
超线性规模法则与奇点危机
Bettencourt等人15发现城市的指标必须与经济增长、生产率和总体能源消耗同步增长,遵循幂律指数$\beta>1$的规模法则。$\beta>1$的系统将倾向于出现“奇点”危机,为了长期生存,系统必须通过创新“重置”避免奇点,推迟系统的崩溃。然而不可避免的是“奇点”出现的频率会随时间推移不断增加。
文明耗竭
数据组(dataome)指生命对生物体之外的信息记录和处理,包括书籍、建筑、计算机等,以及在生物有机体集合之上的信息有机体共同演化。由于数据组和人类深刻交织,就会形成信息相变的过程——物理限制不再是交互的只要限制。作者推测,一个技术连接的文明的生产力、增长、资源消耗将同样遵循幂律指数$\beta>1$的规模法则。
因此,与城市类似,行星文明也会行进在通往“起点”的轨道上,最终起点的间隔时间尺度小于创新的时间尺度——即“渐进耗竭”。此外,随着信息处理和利用自由能的增长,一个文明内部波动的幅度也会增加,如战争、人为灾害等。所以,随着时间推移,“奇点”时间尺度会减小,而潜在危害波动也会使创新存在脱轨可能,文明的奔溃或衰退可能不可避免。
内稳态觉醒与重新导向
当一个文明发展出理解自己能力到达渐进耗竭的时间的时候,就拥有了一个时间窗口。在这个时间窗口内,也许一个文明可以影响自身促成根本性变化,优先考虑长期内稳态和福祉——“内稳态觉醒”
作者给出一些现实中的“小型觉醒”案例包括禁止氟氯烃;非扩张的国家政策(不丹最大限度扩大国民幸福总值而非GDP)。
对费米悖论的影响
若耗竭-觉醒假说成立,则行星文明的生命长度可能呈现双峰分布。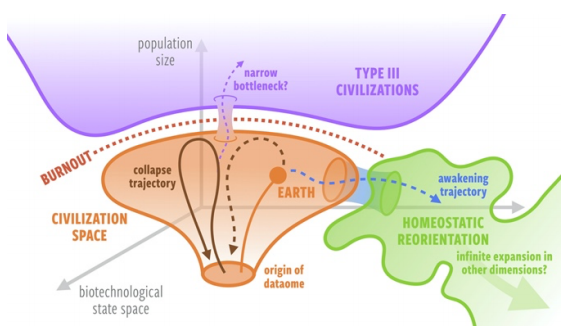
第三级文明存在一个难以进入的发展轨迹限制,长寿的文明会有意识地将发展轨迹重新导向。
若要进行外星文明探测,接近耗竭的文明是最容易被观测到的,而过渡到内稳态觉醒的持久文明可能永远无法远程观测。
-
Baluja, S., Seth, R., Sivakumar, D., Jing, Y., Yagnik, J., Kumar, S., Ravichandran, D., & Aly, M. (2008). Video suggestion and discovery for youtube: Taking random walks through the view graph. Proceedings of the 17th International Conference on World Wide Web, 895–904. https://doi.org/10.1145/1367497.1367618 ↩
-
Davidson, J., Liebald, B., Liu, J., Nandy, P., Van Vleet, T., Gargi, U., Gupta, S., He, Y., Lambert, M., Livingston, B., & Sampath, D. (2010). The YouTube video recommendation system. Proceedings of the Fourth ACM Conference on Recommender Systems, 293–296. https://doi.org/10.1145/1864708.1864770 ↩
-
Weston, J., Makadia, A., & Yee, H. (2013). Label Partitioning For Sublinear Ranking. Proceedings of the 30th International Conference on Machine Learning, 181–189. https://proceedings.mlr.press/v28/weston13.html ↩
-
Covington, P., Adams, J., & Sargin, E. (2016). Deep Neural Networks for YouTube Recommendations. Proceedings of the 10th ACM Conference on Recommender Systems, 191–198. https://doi.org/10.1145/2959100.2959190 ↩
-
Athey, S., Tibshirani, J., & Wager, S. (2019). Generalized random forests. The Annals of Statistics, 47(2). https://doi.org/10.1214/18-AOS1709 ↩
-
https://zhuanlan.zhihu.com/p/397546177 ↩
-
Ai, M., Li, B., Gong, H., Yu, Q., Xue, S., Zhang, Y., Zhang, Y., & Jiang, P. (2022). LBCF: A Large-Scale Budget-Constrained Causal Forest Algorithm. Proceedings of the ACM Web Conference 2022, 2310–2319. https://doi.org/10.1145/3485447.3512103 ↩
-
Lei, T., Zhang, Y., Wang, S. I., Dai, H., & Artzi, Y. (2017). Simple recurrent units for highly parallelizable recurrence. arXiv preprint arXiv:1709.02755. ↩
-
Yu, Z., & Liu, G. (2018). Sliced recurrent neural networks. arXiv preprint arXiv:1807.02291. ↩
-
Tang, G., Müller, M., Rios, A., & Sennrich, R. (2018). Why Self-Attention? A Targeted Evaluation of Neural Machine Translation Architectures (arXiv:1808.08946). arXiv. http://arxiv.org/abs/1808.08946 ↩
-
Zeng, A., Chen, M., Zhang, L., & Xu, Q. (2022). Are Transformers Effective for Time Series Forecasting? (arXiv:2205.13504). arXiv. http://arxiv.org/abs/2205.13504 ↩
-
Xu, J., Wu, H., Wang, J., & Long, M. (2022). Anomaly Transformer: Time Series Anomaly Detection with Association Discrepancy (arXiv:2110.02642). arXiv. http://arxiv.org/abs/2110.02642 ↩
-
Cho, Y., Kim, D., Kim, D., Khan, M. A., & Choo, J. (2022, 十月 31). WaveBound: Dynamic Error Bounds for Stable Time Series Forecasting. Advances in Neural Information Processing Systems. https://openreview.net/forum?id=vsNQkquutZk ↩
-
Wong, M. L., & Bartlett, S. (2022). On the Trajectories of Planetary Civilizations: Asymptotic Burnout vs. Homeostatic Awakening. The 2022 Conference on Artificial Life. The 2022 Conference on Artificial Life, Online. https://doi.org/10.1162/isal_a_00485 ↩
-
Bettencourt, L. M., Lobo, J., Helbing, D., Kühnert, C., & West, G. B. (2007). Growth, innovation, scaling, and the pace of life in cities. Proceedings of the national academy of sciences, 104(17), 7301-7306. ↩