学术相关
10个用于可解释AI的Python库
XAI(Explainable AI)通常采用特征重要性度量、可视化技术或构建固有的可解释模型进行解释生成,之后还需要通过验证模型生成的解释的准确性和完整性验证解释是可信的。
SHAP
最常用的模型解释库了,简单回顾一下。
SHAP是在合作博弈论Shapley值的启发下,构建的一个加性解释模型。SHAP将所有特征都视作贡献者,对于每个预测样本,模型都产生一个预测值,SHAP value就是样本中每个特征分配到的数值。
LIME
它是一种与模型本身无关的方法,LIME利用可解释的模型(线性模型、决策树等)在局部近似目标黑箱模型的预测,而不进入黑箱模型的内部。
$explanation(x)=\mathop{\arg\max}\limits_{g\in G}\ L(f,g,\pi_x)+\Omega(g)$
对于实例$x$,LIME通过最小化解释模型$g$和原模型$f$的近似度,找到最优的解释模型。其中,$G$代表所有候选解释模型,$\pi_x$限定了$x$的邻域,$\Omega(g)$表示解释模型$g$的复杂度。其中解释模型$g$、邻域大小$\pi_x$和模型复杂度均需定义。
LIME首先从全局进行采样,再从样本中选取兴趣点$x$邻域内的样本进行拟合可解释性模型。
LIME的几个缺点:
- 全样本集采样采用的是高斯分布采样,忽略了特征之间的关系,可能导致一些离群点被用于解释模型
- 解释模型的复杂度需要预设,邻域范围对解释影响很大
- 解释不稳定(抽样导致)
Anchors
与LIME类似,也是基于扰动策略生成局部解释的模型无关方法,但Anchors生成结果基于IF-THEN规则,解释是稳定的,说明解释的边界。Anchors的基本思想是在特征中找到一个最小子集,对该子集中的任意实例,模型的结果均相同,与其他特征无关,因此该子集可被用于可解释性,充当黑箱模型的锚点。
给定一个实例$x$,目的是寻找特征子集$A$作为锚点。对于$x$的同类别空间内,要求$A$至少满足$x$邻域内$\tau \%$实例的解释。锚点的搜索通过满足精度要求的候选锚点中,选择覆盖范围$cov(A)=\mathbb{E}_{D(z)}[A(z)]$最大的。
Anchors的缺点:
- 参数众多
- 连续数据边界模糊,对解释可能造成未知影响
- 需要多次调用黑箱模型,依赖模型效率
- 覆盖率定义难以表示,通常不具有普遍含义
Shapash
主打浏览器运行交互界面的python库,可视化比较好。支持SHAP、LIME等。
Attention is all your need1
偷懒一直没有看这篇文章,但课总是要补的。
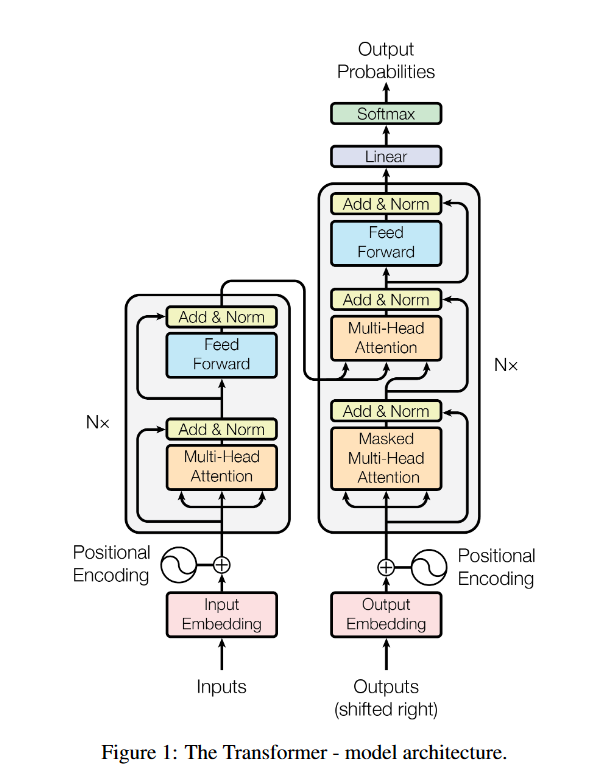
位置编码
通过位置编码,在文本数据建模时考虑词与词之间的顺序。
当使用位置不敏感的模型,如Attention,需要额外使用位置编码;位置敏感的模型,如RNN等不需要。
- 绝对位置编码
- Learned Positional Embedding
- 相对位置编码
- Sinusoidal Position Encode
- $PE_{(pos,2i)}=sin(\frac{pos}{10000^{\frac{2i}{d_{modle}}}})$
- $PE_{(pos,2i+1)}=cos(\frac{pos}{10000^{\frac{2i}{d_{modle}}}})$
- $pos$为位置;$i$为维度
- Complex Embedding
- Sinusoidal Position Encode
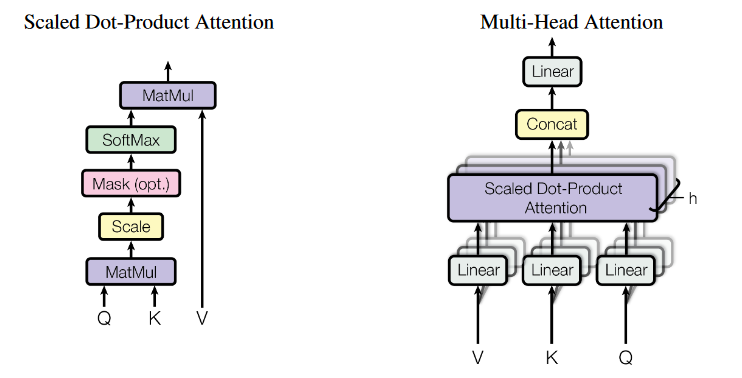
Attention
$Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})V$
点积注意比加性注意效率更高,且通过维度$\sqrt{d_k}$调节,避免softmax梯度消失后点积注意在大数值上表现与加性注意接近
$\begin{aligned}MultiHead(Q,K,V)=Concat(head_1,…,head_h)W^o\\ where\ head_i = Attention(QW_i^Q,KW_i^K,vW_i^v)\end{aligned}$
Position-wise Feed-Forward Networks
$FFN(x)=max(0,xW_1+b_1)W_2+b_2$
机器学习技术:多任务学习综述!
我希望通过多任务学习的技术结合Marketing理论研究构建数智化营销系统,不知道目前该领域是否能够满足我的设想,所以通过一些文章作简要了解。
多任务学习multi-task learning (MTL)
给定$m$个学习任务,这$m$个任务或它们的一个子集彼此相关但不完全相同。通过使用所有$m$个任务中包含的知识,改善特定模型的学习。
- 特点
- 关联任务效果互相提升
- 正则化
- 共享部分结构,降低内存占用,提升推理速度
负迁移
MTL处理的任务不相关或冲突的时候,模型表现会受到损害,出现跷跷板现象,即一个模型效果提升时,另一个模型效果变差。
- 多任务梯度方向不一致
- 同一组参数,不同任务更新方向不一致,导致模型参数震荡
- 一般出现在多任务差异较大的场景
- 多任务收敛速度不一致
- 有的任务已经过拟合,而其他任务还是欠拟合状态
- 多任务loss取值量级差异大
- 模型被loss较大的任务主导
- 出现在两个任务使用不同损失函数或拟合值取值差异大的情况
目前,多任务学习主要聚焦于网络结构和损失函数两个角度。模型网络结构创新希望解决的是多任务之间高效实现参数共享与分离,使多模型融合共性,又提供独立空间防干扰;优化损失函数致力于改善多任务学习的训练过程。
MTL网络结构
根据模型处理不同任务时网络参数的共享程度,MTL可以分为硬参数共享和软参数共享。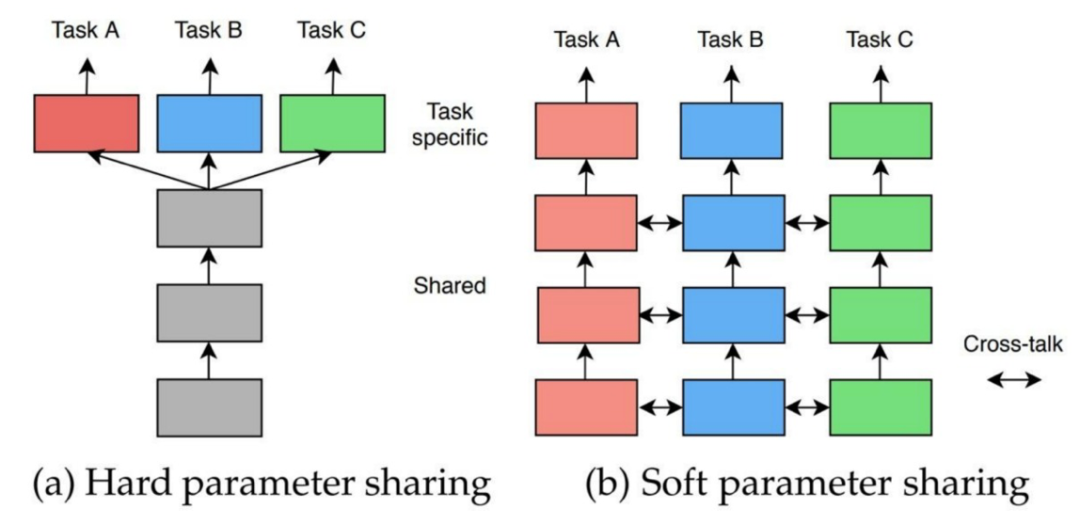
硬参数共享
硬参数共享将模型的主体部分共享参数,输出结构任务独立。
MT-DNN框架
Microsoft针对自然语言理解问题,集成MTL和BERT语言模型预训练二者的优势,在众多NLU任务上表现出色。
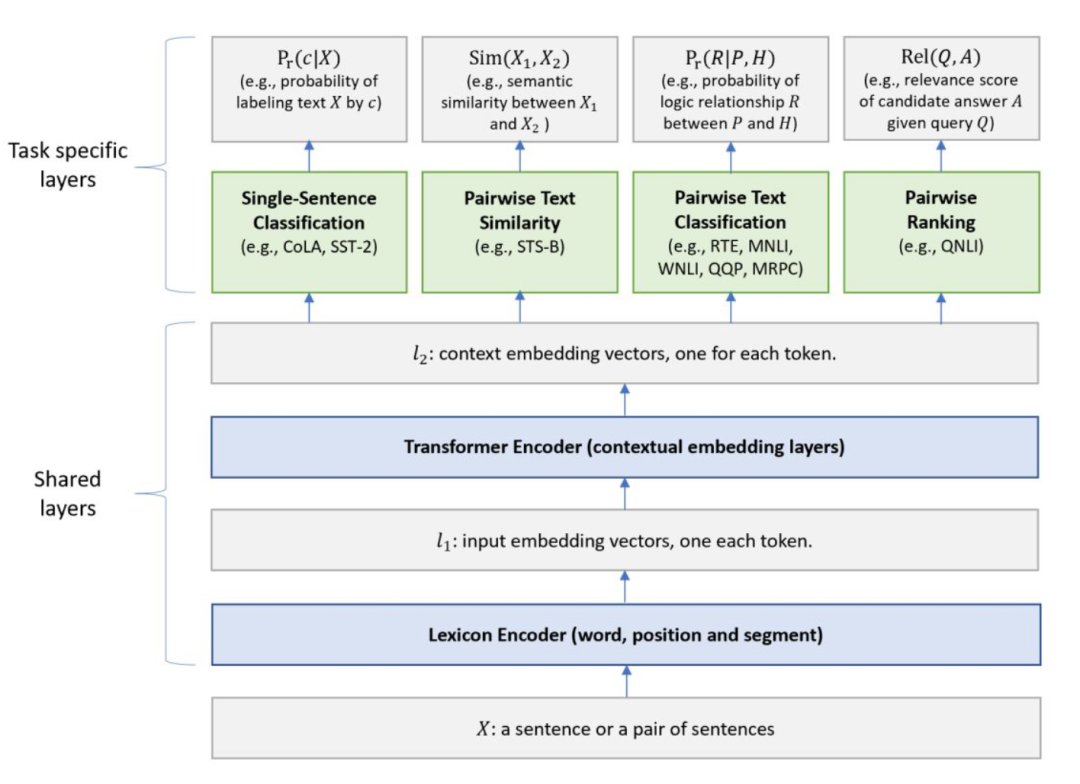
- 训练数据:将所有任务的batch训练数据混合成数据集D,每次从D中拿出一个任务batch进行训练
- 共享部分
- Lexicon Encoder
- BERT输入
- Transformer Encoder
- 多层Transformer模型
- Lexicon Encoder
- 特定任务部分
- Single-Sentence Classification单一文本分类任务
- Text Similarity文本相似度
- Pairwise Text Classification匹配样本分类
- Relevance Ranking相关性排序
Multi-Task-NLP
共享Encoder部分的向量信息,在输出部分通过Header区分不同任务。
软参数共享
不同任务采用独立模型,模型参数彼此约束。软参数共享模型底层共享部分参数,各任务保有部分参数不共享,各任务顶层有自己的参数。研究的重点是如何将底层共享和不共享的参数融合一起送到顶层。
MMOE结构
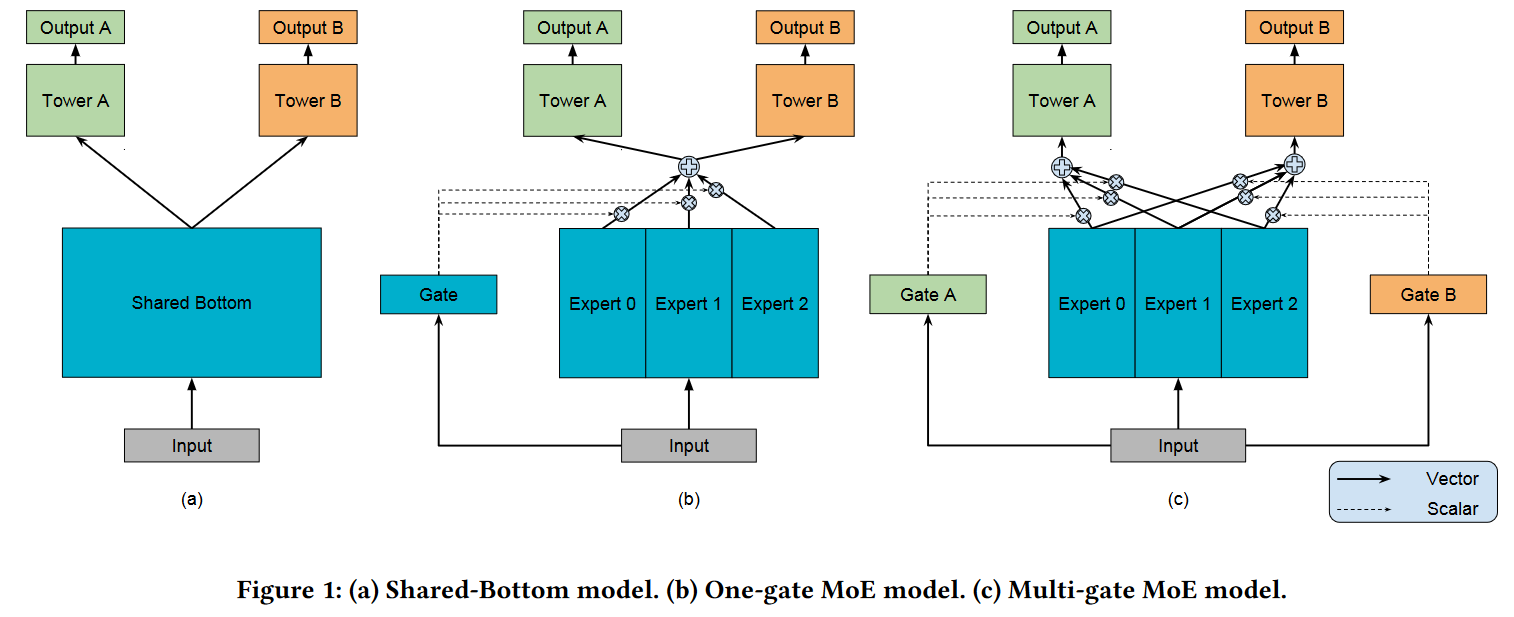
作者说MOE先对Expert 0-2进行加权求和,再送入Tower A和B,加权权重通过Gate学习。MMOE在MOE的基础上又多了一个GATE,意味着多个任务既有共性,又有独特性。
这段我没有看得很懂。
- MMOE缺点
- 所有Expert被所有任务共享,可能无法捕捉任务间复杂关系,带来噪声
- 不同Expert之间没有交互,联合优化效用存在问题
腾讯PLE模型
CGC模型针对MMOE的第一个缺点,为每个任务保留了独有Expert。
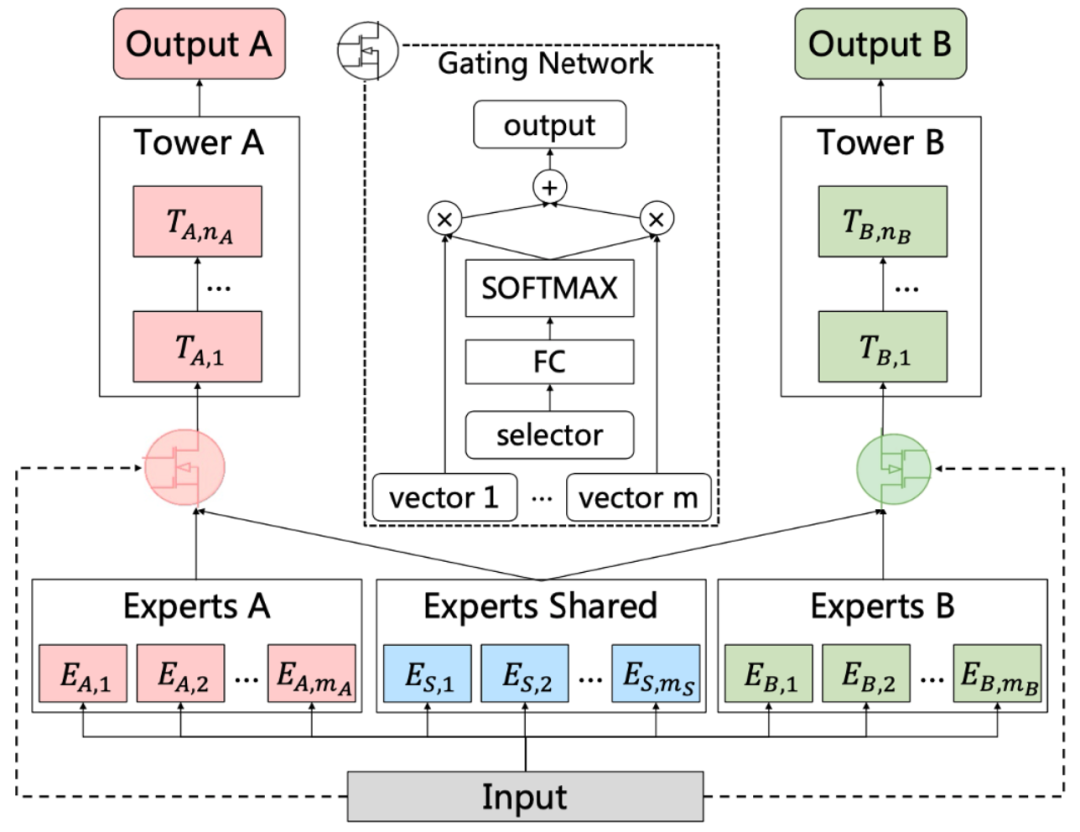
PLE模型针对MMOE第二个缺点,在CGC模型的基础上进行优化。
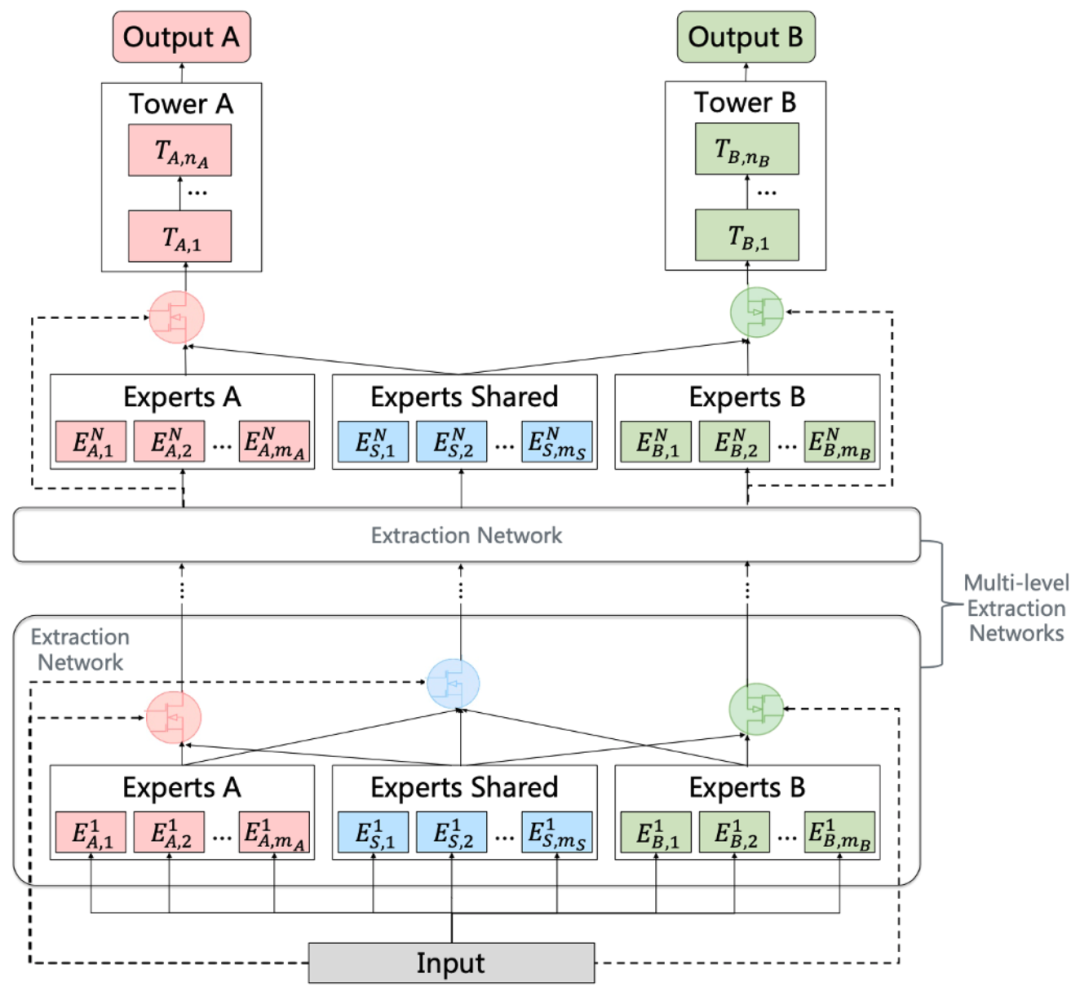
百度UFO模型
针对预训练大模型落地问题,百度提出统一特征表示优化技术UFO,综合了硬参数共享和软参数共享。
还是没看懂。
MTL损失函数
多任务学习的损失函数通常采用多个任务加权求和形式$L_{total}=\sum\limits_kw_kL_k$
基于初始状态设置权重
缺乏先验知识的情况下,通常想法是将总损失设置为所有任务损失的算数平均值。但是,由于每个任务损失函数的数量级和物理量纲都不同,因此使用损失函数初始值的倒数进行无量纲化:$w_k=\frac{1}{L_k^{prior}}$
基于先验状态设置权重
根据预先获取数据集的标签信息统计值构造损失函数先验状态$L_k^{prior}$作为权重,$w_k=\frac{1}{L_k^{prior}}$
根据实时状态设置权重
$w_k^t=\frac{1}{sg(L_k^t)}$,其中$sg(\cdot)$为stop gradient。
根据梯度状态设置权重
之前几种权重设置具有缩放不变性,但不具有平移不变性。根据梯度状态设置的权重同时具有缩放和平移不变性。
根据梯度量级和训练速度更新权重
根据损失相对下降率设置权重
根据损失变化设置权重
根据动态任务优先级设置权重2
论文为每个任务制定了KPI,记为$K\in[0,1]$,用于衡量每个任务的学习难度(通常用任务评估指标计算)。KPI越大表明任务学习难度越小。
作者任务优先学习困难的任务能够提高多任务的表现,通过KPI指标可以设置不同任务的优先级。
多任务学习经典品读:MMoE模型篇3
Multi-gate Mixture-of-Experts多门混合专家模型MMoE
对于推荐系统而言,通常需要同时优化多个目标,如企业希望用户不仅能够购买电影,同时能够在观后喜欢电影进而持续使用企业的平台,多任务学习就是实现这一效果的关键技术。相较于前人研究,MMoE能够不对任务相关性进行限制或添加额外的参数,实现自动化捕捉共享任务信息和特定任务信息,进而清晰地建模任务间关系,并通过共享表示学习特定任务功能。这赋予了MMoE模型相较于前人研究更适合真实环境工业化应用。
MMoE的骨架基于Shared-Bottom模型架构,Shared-Bottom在输入层后添加了一个所有任务共享多个底层的网络结构,之后赋予每个任务一个独立的“Tower”网络。在Shared-Bottom基础上,MMoE架构将一个共享网络结构修改为一组底层网络结构,每个底层网络结构称之为“专家Expert”,在本文中每个专家是一个前馈神经网络。之后,MMoE架构为每个任务引入了一个控制网络Gate,借助输入特征和输出的softmax门控将不同专家以不同权重组装在一起,实现不同任务使用不同的专家组合。专家组合的结果会被传送到任务特定的塔网络。这样,不同任务的控制网络就可以学习不同的专家混合结构,实现捕获任务间关系。
文献综述
Multi-task Learning in DNNs
采用底部隐藏层多任务共享的Shared-Bottom模型架构。该结构减少了过拟合的风险,但是由于任务间的差异,容易出现跷跷板现象。
子网集成&专家混合
DNNs证实了模型集成和子网集成可以提升模型表现。Eigen et al 和 Shazeer et al将混合专家模型转化为基本建模单元MoE层,堆叠在DNN中,提升了模型的建模效果并降低计算开销。为人工生成智能设计的PathNet采用并行选择和训练多个通路的方式适应大规模模型。
建模准备
共享底层的多任务模型Shared-Bottom Multi-task Model
给定$K$个任务,该模型包括一个共享底层网络$f$和$K$个塔网络$h^k$。共享底层网络搭建在输入层之上,塔网络建立在共享底层网络的输出之上。对于每个任务的输出$y_k$有$y_k=h^k(f(x))$
合成数据生成
通过合成数据,作者Pearson相关控制多任务之间的关联程度,进而测试模型在不同多任务相关度之下的表现。
作者通过正弦曲线组合生成了两个回归任务,并通过两个任务标签的Pearson相关作为量化指标控制任务相关度。
$\begin{aligned}给定&特征维度d,生成两个正交单位向量u_1,u_2 \\ &u_1^Tu_2 = 0,||u_1||_2=1,||u_2||_2 = 1\\ 给定&规模常数c和相关性得分p\in [-1,1],生成两个权重向量w_1,w_2\\ &w_1 = cu_1, w_2 = c(pu_1+\sqrt{(1-p^2)}u_2)\\ N(0&,1)分布中随机抽取一个输入数据样本点x\\ 生成&两个回归任务的标签y_1,y_2\\ &y_1 = w_1^Tx+\sum\limits_{i=1}^msin(\alpha_iw_1^Tx+\beta_i)+\epsilon_1\\ &y_2 = w_2^Tx+\sum\limits_{i=1}^msin(\alpha_iw_2^Tx+\beta_i)+\epsilon_2\\ &\alpha,\beta为超参数,\epsilon_1,\epsilon_2\mathop{\sim}\limits^{i.i.d}N(0,0.01)\\ 重复&前两步,直至生成足够多的样本数据\end{aligned}$
该非线性数据通过$cos(w_1,w_2)=p$控制权重相关性,并通过结果标签的Pearson相关性进行测量任务数据相关性。
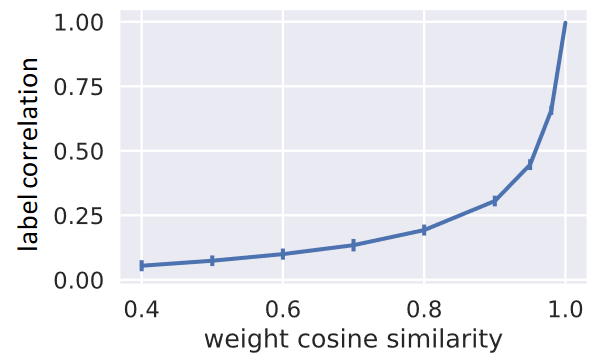
分析任务相关性的影响
- 给定一系列任务相关性得分,并为每个得分生成合成数据集
- 设定相同的超参数,为每个数据集训练共享底层多任务模型
- 在保持任务相关性得分列表和超参数相同的前提下,重新生成数据多次并训练
- 计算每个任务相关性得分的平均表现
本案例中,作者在每个塔网络中使用8个隐藏单元的单层神经网络,在共享底层网络中使用大小为16的单层网络。模型使用TensorFlow构建,使用Adam优化,所有未提及的超参数使用默认超参数。
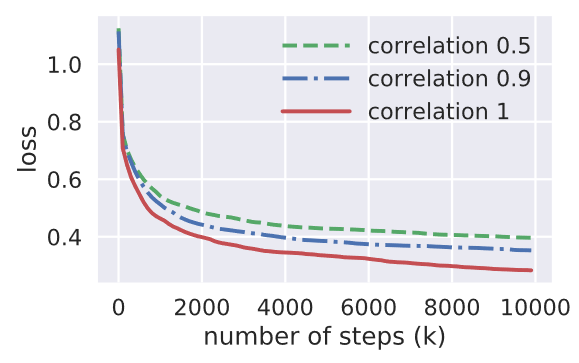
证明了传统的多任务在低任务相关度下不能有良好表现。
模型构建
Mixture-of-Experts (MoE) 模型
$y=\sum\limits_{i=1}^n g(x)_{i} f_i(x)$,其中$\sum\limits_{i=1}^n g(x)_{i} =1,g(x)$为第$i$个$logit$输出
$f_i$为$n$个专家网络,$g$代表控制网络基于输入产生的权重。
MoE层
MoE层与MoE模型基本一致,但接收的是前一层的输出,并将输出传递给下一层。Eigen et al和Shazeer et al提出MoE层的主要目的是只激活部分网络的有条件计算。
MMoE
作者提出新的MoE模型(MMoE)的目的是在不引入大量额外参数的前提下,设计能够捕捉任务之间差别的模型。在Shared-Bottom模型的基础上,作者使用MoE层替代共享底层网络$f$,并为每个任务$k$添加独立的控制网络$g^k$,即对每个任务$k$,$y_k=h^k(f^k(x))$,其中$f^k(x)=\sum\limits_{i=1}^ng^k(x)_if_i(x)$。
在实践中,作者使用ReLU激活的相同的多重感知机。控制网络使用简单的带有softmax层线性变化$g^k(x)=softmax(W_{gk}x)$,其中$W_{gk}\in\mathbb{R}^{n\times d}$。
若任务不相关,那么控制网络就会令不同任务利用不同的专家,
作者还测试了所有任务共享一个门控的单门控混合专家模型OMoE模型。
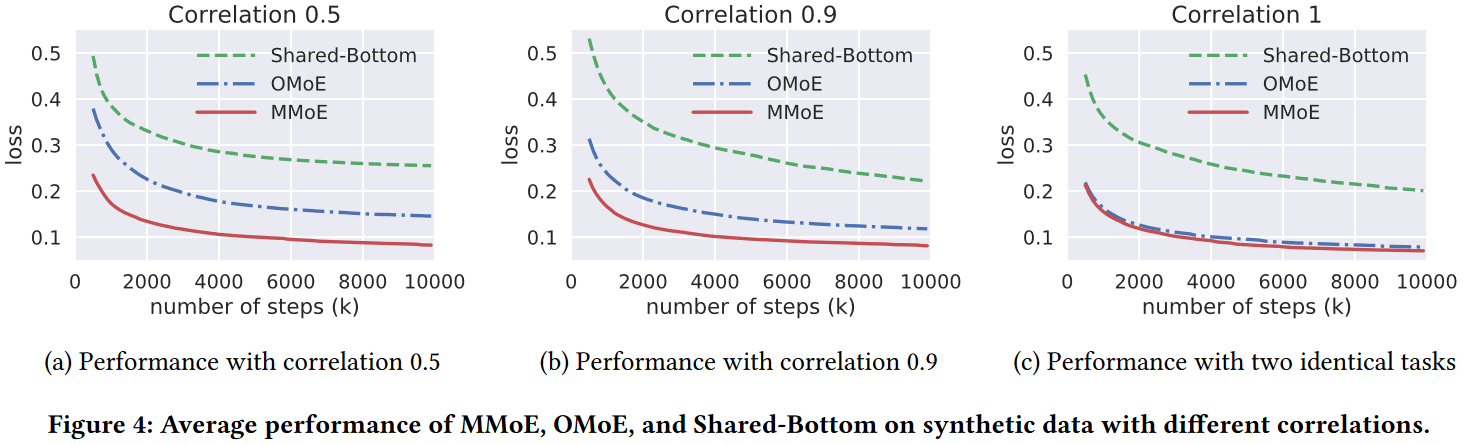
- 合成数据表现
作者对比了Shared-Bottom model、OMoE和MMoE模型在合成数据集上的表现。输入的维度为100,所有的MoE基模型设计8个单层网络的专家,每个专家网络的隐藏层大小为16,塔网络仍使用大小为8的单层网络。由于MoE基模型在共享专家网络和塔网络共使用$100\times16\times8+16\times8\times2=13056$个参数,所以将单层Shared-Bottom网络的大小设置为$13056/(100+8\times2)\approx113$。
所有的模型采用Adam优化,学习率通过$[0.0001,.001,0.01]$的网格搜索调整。对每个模型设置进行200轮独立随机数据生成和模型初始化,最终结果取均值。
- 所有模型在高任务相关度的数据上表现优于低任务相关度数据
- MMoE在任务相关度变化时,模型表现变化的最小
- MoE基模型在所有情境的平均表现优于Shared-Bottom模型
模型训练
模型鲁棒性
作者通过调整生成数据的随机种子和模型初始化设定检验模型鲁棒性。
- 在所有情境下,Shared-Bottom模型平均比MoE基模型捕获更差的局部最小值
- OMoE和MMoE在高任务相关度时,表现基本一致
- 当任务相关度下降时,OMoE的鲁棒性明显降低
- 三个模型的最差loss表现接近(神经网络万能近似),但大规模模型只借助神经网络学习正确的模型的可能性很低
真实数据实验
- 基准模型
- L2约束模型
- 十字绣模型(Cross-Stitch)
- 张量分解模型
- 塔克分解
为确保各模型间公平,作者通过设置每层隐藏单元的上限为2048限制各模型的最大规模。
- UCI人口收入调查数据集
- 多任务1:绝对Pearson相关:0.1768
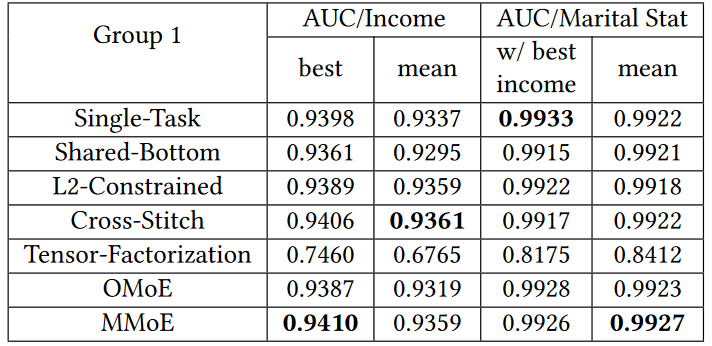
- Task 1:预测收入是否超过$50K
- Task 2:预测个人婚姻状态是否从未结婚(辅助任务)
- 多任务2:绝对Pearson相关:0.2373
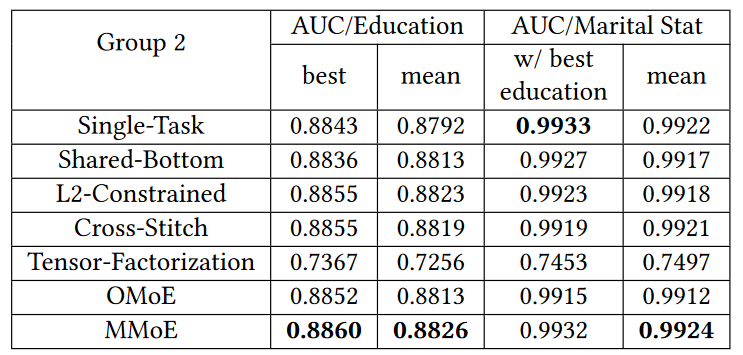
- Task 1:预测教育水平是否至少为college
- Task 2:预测个人婚姻状态是否从未结婚(辅助任务)
- 训练样本:199523;测试样本99762
- 其中测试样本按1:1划分为验证集和测试集
- 评价指标:AUC
- 使用主任务AUC进行调参
- 多任务1:绝对Pearson相关:0.1768
大规模内容推荐实验
深度排序模型试图优化两个排序问题
- 优化卷入度相关目标(卷入度子任务)
- 点击率
- 参与时间
- 优化满意度相关目标(满意度子任务)
- 喜欢程度评分
Shared-Bottom模型:使用一个前向神经网络和多个ReLU激活的全连接层构建共享底层网络,每个任务使用一个全连接层建筑在共享底层网络之上作为塔网络。
MMoE模型:将共享底层网络的最高层转换为MMoE层,并保持输出隐藏单元维度不变。(目的是节省计算资源)
模型使用小批量SGD优化,batch-size=1024。
- 线下评估结果
在 300亿用户隐式反馈的数据集上训练模型,并通过100万数据集评估模型。
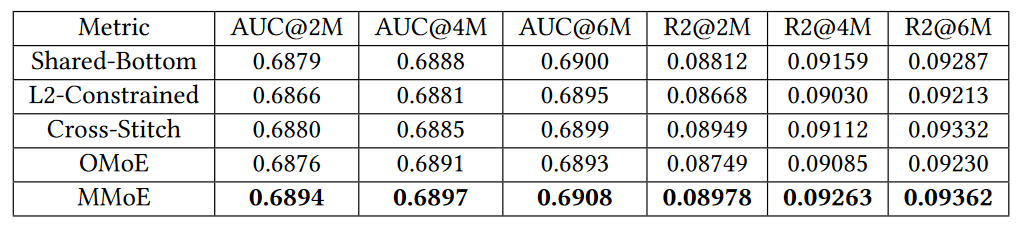
MMoE模型表现最佳,L2约束模型和十字绣模型由于有太多参数被限制,所以表现不佳。
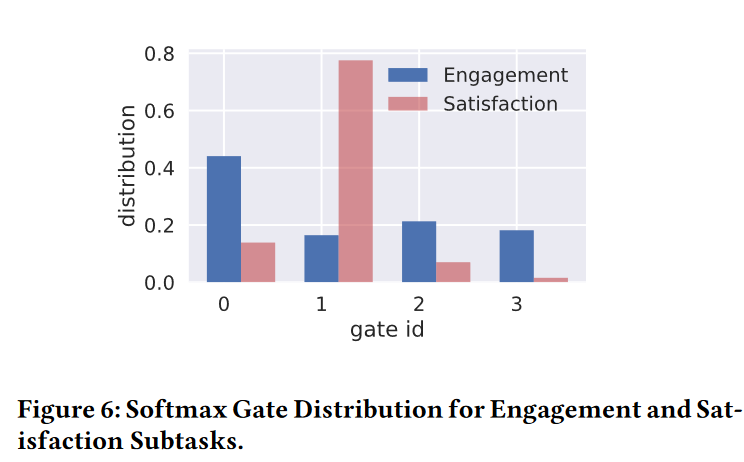
通过观察MMoE模型softmax门控赋予卷入度任务和满意度任务的权重,可以发现MMoE学习到了两个任务之间的差异,并自动的平衡了共享和非共享参数。 由于满意度任务的标签远比卷入度标签稀疏,所以满意度子任务的门控权重更聚焦于单一的专家网络。
- 线上实验
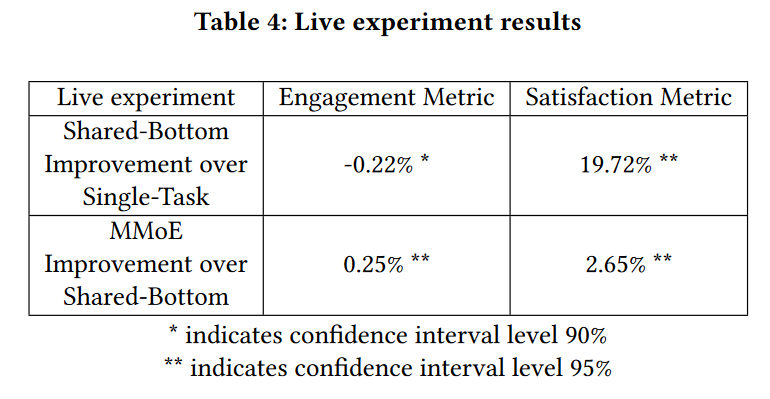
- 相较于单一任务模型,Shared-Bottom模型提高满意度实时指标19.72%,而卷入度实时指标只有0.22%的下降
- MMoE模型比Shared-Bottom模型在两维度上均有提升
预测网络内容的演化的一种模型和算法4
一篇早年(2016年)的网络内容演化顶刊论文,看完最大的体会是近些年计算机领域的发展真的很快,六七年前的文章已经落后很多了。
作者将网络内容演进的流行性分为两种模式。
第一种模式是稳态随机动力过程(即接受速率遵循固定模型),该阶段概率法则驱动内容传播,因此平均接受速率为常数且与实践独立,仅包含小的波动。该阶段网络内容流行性增长遵从线性模式。该模式出现在一个在线社交网络函数作为封闭系统的情境,即一批同质性的用户搜索信息并向其邻居分享连接的行为中。该模式涉及的事件大多是独立的,并且可以通过连续模型向常数接受速率中引入小的波动,进而刻画在该统计平衡稳态的内容扩散过程。
第二种模式是由在线社交网络与其周围环境产生关联导致的扰动过程。这种关联发生在通过干预活动显著地通过获取个体回应信息流的形式影响了内容接受模式。该外生刺激改变了具有异构激活阈值的用户族群的敏感性,从而生成有利于传播在线内容的环境。实证数据表明,扰动过程的流行性演化模式呈现由logistic增长动力学描述的单一类别,即非平稳扩散阶段的在线内容类似于创新接收模型。
因此,作者认为可以通过稳态随机动力过程和扰动过程的组合构建流行性增长动力学模型。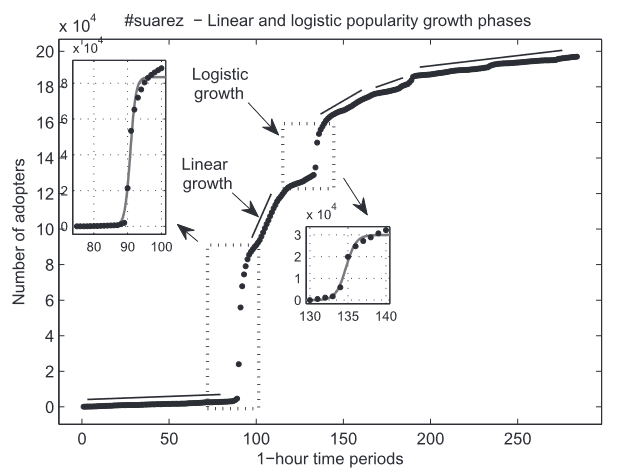
过去,主流的研究集中在使用在线内容的属性估计其未来的流行性。另外的一个研究趋势是强调社交网络的拓补结构、用户特征及其行为模式。许多研究从时间角度识别了流行性趋势的通用模式,使其支持流行性预测。
在线内容流行性增长建模
建模框架
在一个较长的时间窗口(日、周、月)内,接受速率的均值保持稳定,使内容流行性线性增长。线性趋势可以通过一阶多项式模型$N(t)=P\cdot t+N(t_0)$,$P$为稳态接受速率。
稳态流行性增长趋势是长期存在的,因为它捕捉了低阈值用户之间的在线内容传播动力学。一个干预时间引起的扰乱过程使那些平时不会接受信息传播的高阈值用户被激活,它的本质上是干预事件增加了阈值接近的异质性用户的敏感性,使其接受传播,它不会改变事件的传播性。
用户接受阈值的单峰分布产生了一个sigmoid流行性演化模式,用logistic函数模式刻画的$t$时间接受用户总数$N(t)$的数学表示为:$N(t)=\frac{C}{1+e^{(-\alpha(t-t_{infl}))}}$,其中$C$为sigmoid曲线的饱和度,表示环境的承载能力(被内容影响的个体总数);$\alpha$为sigmoid曲线的陡度,sigmoid曲线的斜率与用户接受阈值分布的方差有关,方差越小,斜率越大;$t_{infl}$表示sigmoid曲线的拐点,该时间节点流行性增长在快速增长阶段后开始放缓。
任何在线内容无论是否有趣,都必须经历线性和非线性阶段。然而,相比于被长久欢迎的在线内容,稍纵即逝的内容的稳态接受阶段显著要短,因为即逝内容的趣味性更不稳定且短暂。一个即逝且不受欢迎的内容在稳态阶段和扰动连续阶段的数值上都会明显小于受欢迎的持久内容。而作者的模型可以捕获任一一种寿命长度和受欢迎度的内容流行性演变,其中稍纵即逝且不受欢迎的内容具有一个斜率为0的稳态阶段。
流行性增长模式的统计刻画
由于内容可以完全由线性和非线性函数刻画,所以一个由常数项和具有logistic分布概率密度函数数学结构的动态项组成的函数,应该包含多个脉冲叠加在一个稳态接受趋势的在线内容接受率。$n(t)=p+\sum\limits_mb_m\frac{e^{-\frac{t-t_m}{s_m}}}{s_m(1+e^{-\frac{t-t_m}{s_m}})^2}$,其中$p$为稳态接受率,规模因子$b_m$规定在时间节点$t_m$达到的第$m$个接受爆发顶峰的高度,$s_m$调整了接受爆发的宽度。
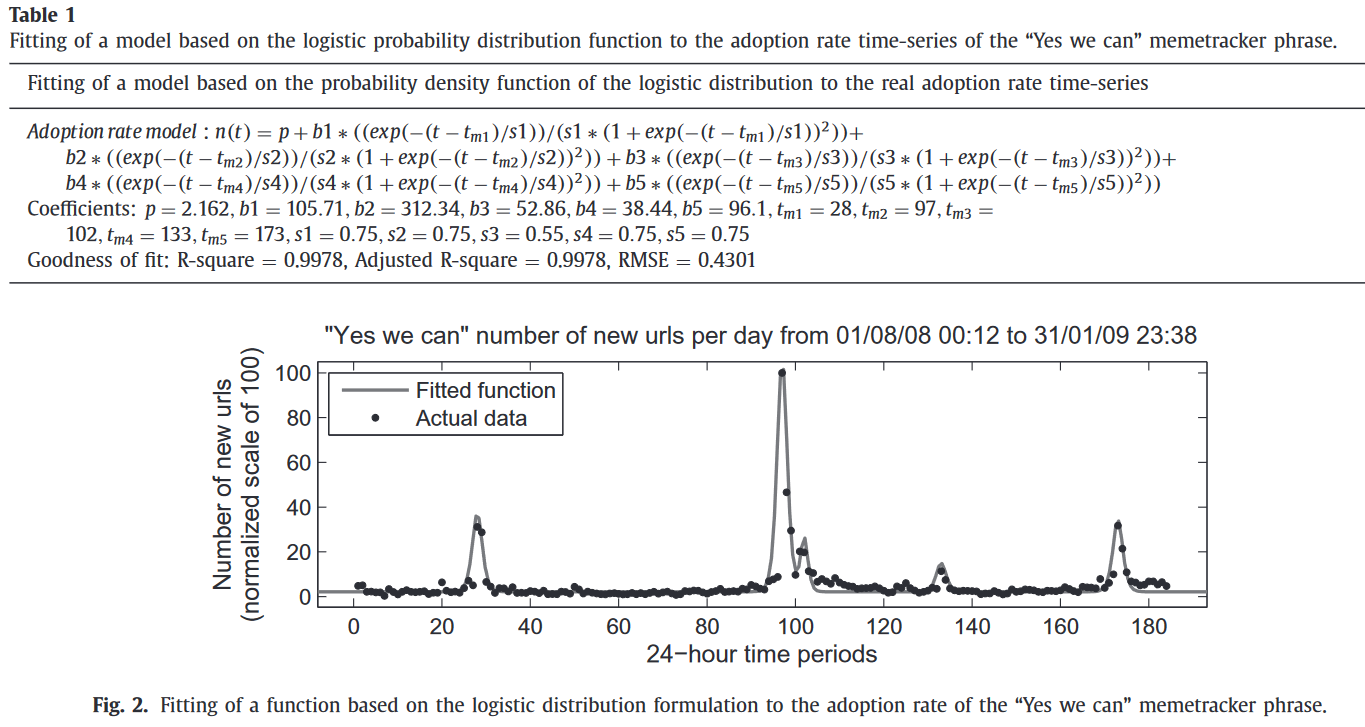
流行性增长模型
假设在线内容的流行性演变包含$k$个线性增长周期和$f$个S形增长周期。将$P_k$定义为第$k$个稳态阶段的接受速率,$t_k^s,t_k^e$为对应起止时点。令$C_f,\alpha_f,t_{infl}^f$为第$f$个S形增长周期的参数。
当$t_0$时,接受者数量为$N(t_0)$,则对于持久性内容$t$时(稳态$k$)的接受者总数$N(t)$刻画为$N(t)=N(t_0)+\sum\limits_{j=1}^{k-1}P_{j}\cdot{(t_j^s-t_j^e)}+P_k\cdot(t-t_k^s)+\sum\limits_{i=1}^f\frac{C_i}{1+e^{(-\alpha_i(t-t_{infl}^i))}}$,对于稍纵即逝的内容仅需令稳态阶段$P_k=0$即可。
流行性预测方法
作者假设接受者一旦接受信息的传播,就会永久性的保持“接受者”状态。因此接受者曲线单调增。定义$出生率=\frac{dN(t)}{dt}$,在线性阶段出生率为常数,在非线性阶段出生率实时变动$\frac{dN(t)}{dt}=f(N(t))=\alpha\cdot N(t)\cdot (1-\frac{N(t)}{C})$。
作者通过检测在线内容$c$的接受速率二阶导$acc$是否在可接受范围$[-\Delta,\Delta]$内,确定流行性增长模式(线性/非线性)并估计模型参数,$\Delta$取值通过实验进行调整。该参数的估计需要二阶导$acc\in [-\Delta,\Delta]$的倒数第二个时间点$t_s$到跨过阈值$\Delta$时点$t_{acc>\Delta}^{first}$之后$acc<0$的第一个时间节点$t_{acc<0}^{first}$的累积接收者数量。$t_{acc<0}^{first}$反映了sigmoid函数的拐点。
实验结果
基准模型
- Szabo&Huberman 模型(S-H)
- Multivariate Linear 模型(ML)
- MRBF 模型
- SEISMIC 模型
- Kong et al. 模型
性能评价指标
- RSE
- 应用于S-H模型、ML模型和MRBF模型
- APE
- 应用于SEISMIC模型
- RMSE
- Kong氏模型
数据集
- Twitter信息(hashtag)
- Weng 1.35m hashtag
- Spain protests 15m
- #Suarez 260k+
- Memetracker dataset 8.5m
- Flickr dataset 11m+
- photos
数据处理
- 在线内容
- Twitter 话题标签
- Memetracker 短语
- Flickr 图片
- 接受速率
- 接受速率一阶导数
- 参数化时间分辨率&时间周期
实验1:“Yes we can” memetracker 短语拟合实验
时间窗口:24h
作者通过前五天的数据观察,确定了模型演化当前采用稳态模式。直至第28天$t_{28}$观察到加速速率超过了稳态边界(令$\Delta=100$),进入扰动增长模式。为估计扰动增长模式的参数,作者拟合了$t_{28}$后的3个时间点。
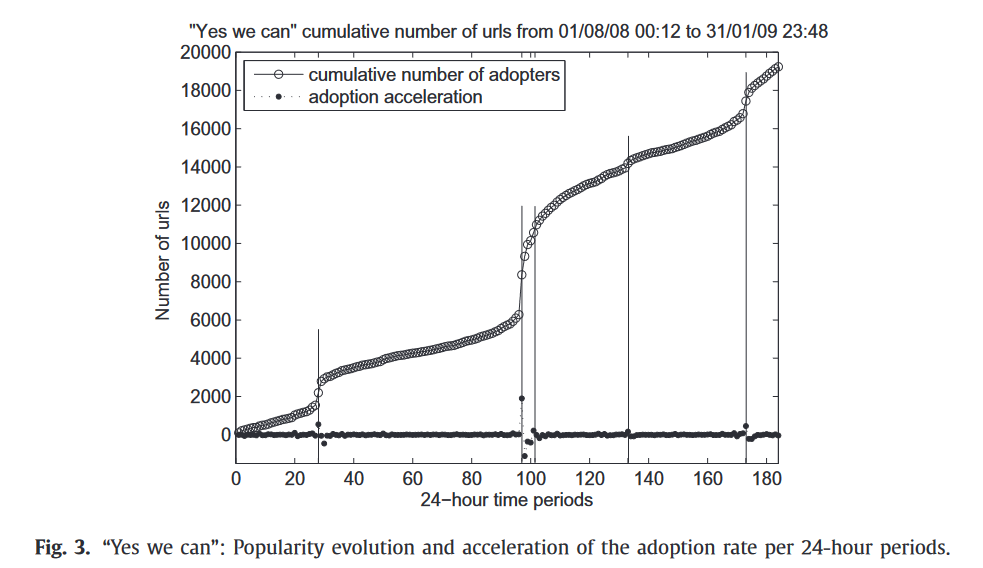
实验4:预知sigmoid增长阶段拐点的提前预测
能否复现?更多推广活动检验?一些高影响力事件会在预热阶段进入sigmoid增长,在事件发生当日达到拐点。那么,当知悉扰动增长的拐点后,作者希望检验该模型能够提前多久预测流行性增长模式。实验结果显示,即使使用进入该阶段后第一个时间点的数据拟合,效果也优于其他模型。
NHPE荐读丨多学科之间的巴别通天塔:如何消除概念的模糊和歧义?
这篇文章源自美国行政学学者Fred W. Riggs,20世纪70年代后,他积极参与国际社会科学理事会的概念与术语分析委员会工作,致力于编撰一套社会科学概念词汇。
巴别Babel指嘈杂混乱之意,此处指各学科术语使用混乱,语义不清。
病因
- 每个词语代表的不是单一概念,而是数量不定而含义交叉的概念
- 逆语义方法:由概念的定义出发而及于用以命名该概念的若干词语
- 由词及义的语义学分析不可行
- 自然科学的术语多为新创词(代码式语言);社会科学多用现有词汇(双关式语言)
- 作者认为外行人对代码式语言不理解,所以少有批判
- 双关式语言让外行人误以为理解,实际不理解,所以对社会科学作品多有指摘
解决方法
- 同义选用法
- 啰嗦重复
- 将歧义词放在前,后面括号生僻词
- ex. 定义(逆语义定义)
- 啰嗦重复
- 保证充分的语义间距
- 多义不再同一领域
- 使用语境修饰
冒充人类作者,ChatGPT等滥用引担忧,一文综述AI生成文本检测方法
简要了解,作为知识储备,短期内没有使用需求。只对文章进行阅读,不回顾原始论文。
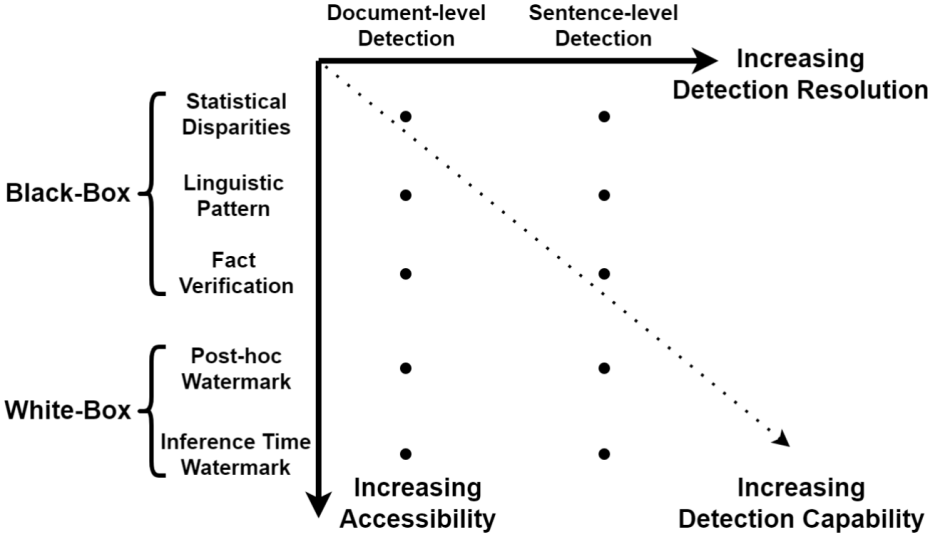
黑盒检测
指对LLMs只有API级别的访问权限,主要依赖收集人类和机器文本样本来训练模型。
在数据收集后,黑盒检测的特征选取通常分为统计特征、语言特征和事实特征。
黑盒检测高度依赖数据收集,但收集过程非常容易引入偏见,从而降低检测的鲁棒性。此外,随着模型能力提升,LLMs生成文本与人类文本差距越来越小,进而导致黑盒检测的准确性越来越低。
白盒检测
指对LLMs拥有所有访问权限,并可以通过控制模型的生成行为或对生成文本添加水印进行生成文本追踪和检测。
- post-hoc 水印
- 在文本完成生成后,向文本中添加隐藏信息用于检测
- inference time 水印
- 改变LLMs对token的采样机制加入水印
LLMs一旦开源,目前没有可行的检测机制。
业界动态
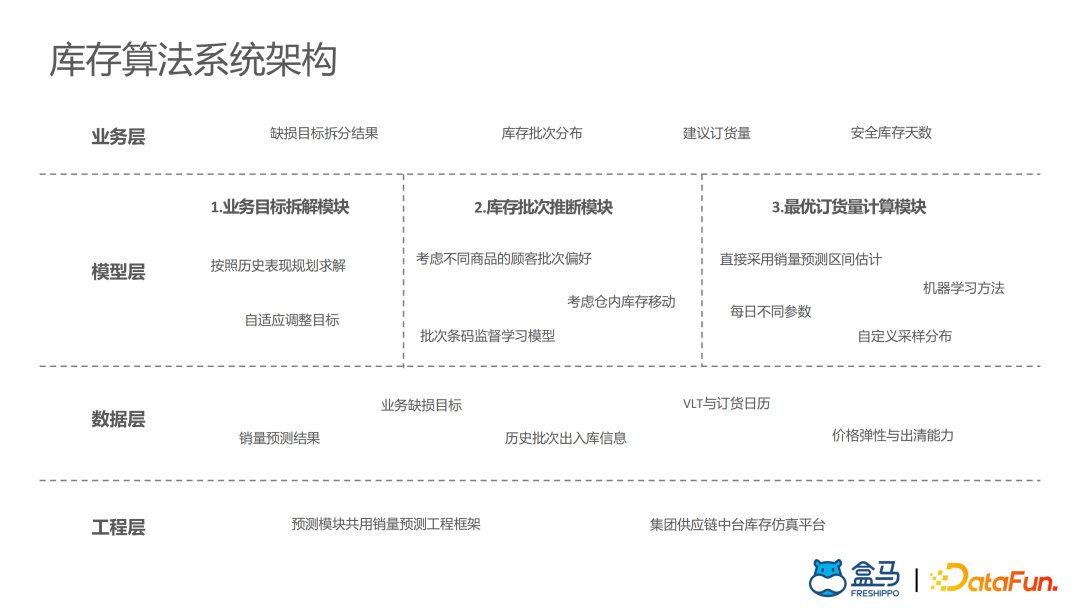
盒马供应链算法实战
盒马生鲜销售额占比达60%~70%,是盒马最核心的品类,对时效性要求非常高。对于冷链物流而言,整件物流成本远低于包裹物流,而且库存越分散,需求不确定性越大,就会产生更高的库存成本。因此,盒马选择多种业务模式后端融合,尽可能共享干线网络和库存,提高资源利用率和供应链效率。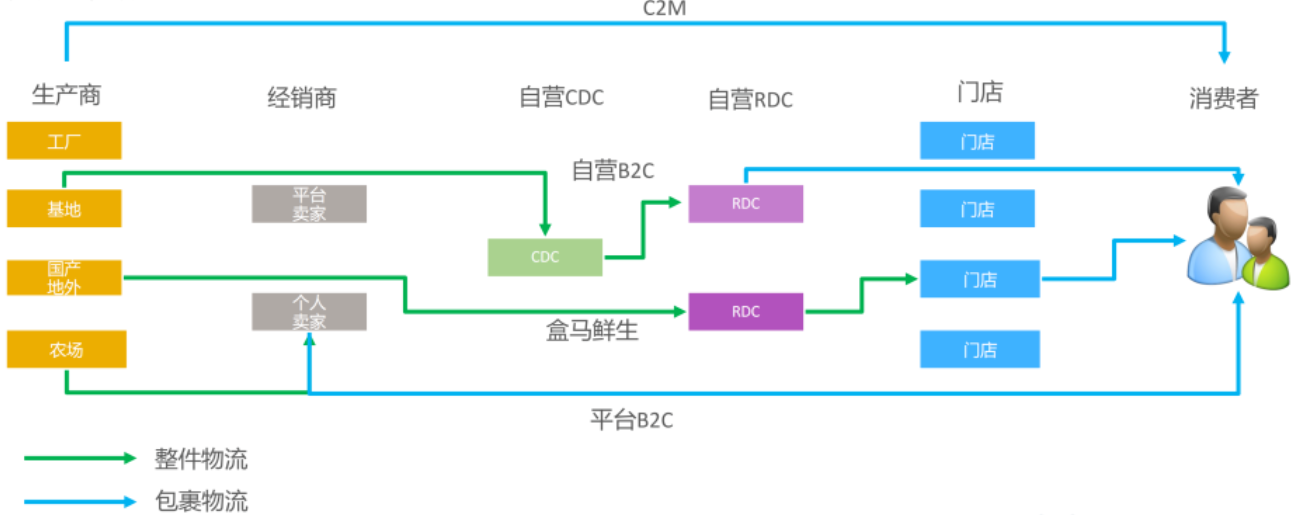
盒马生鲜自动补货系统算法模块
- 盒马生鲜补货系统
- 需求预测
- 库存模型
- 动态调控
盒马销售预测算法迭代路径
- 简单模型
- 单SKU建模
- 贴近业务理解
- 机器学习
- 跨SKU参考信息
- 大量依赖特征工程
- 深度时序模型
- 不依赖特征工程
- 单模型预测未来多天
- 时空图网络模型
- 考虑样本间相互影响
- 表征活动等复杂信息
- 空间多任务学习
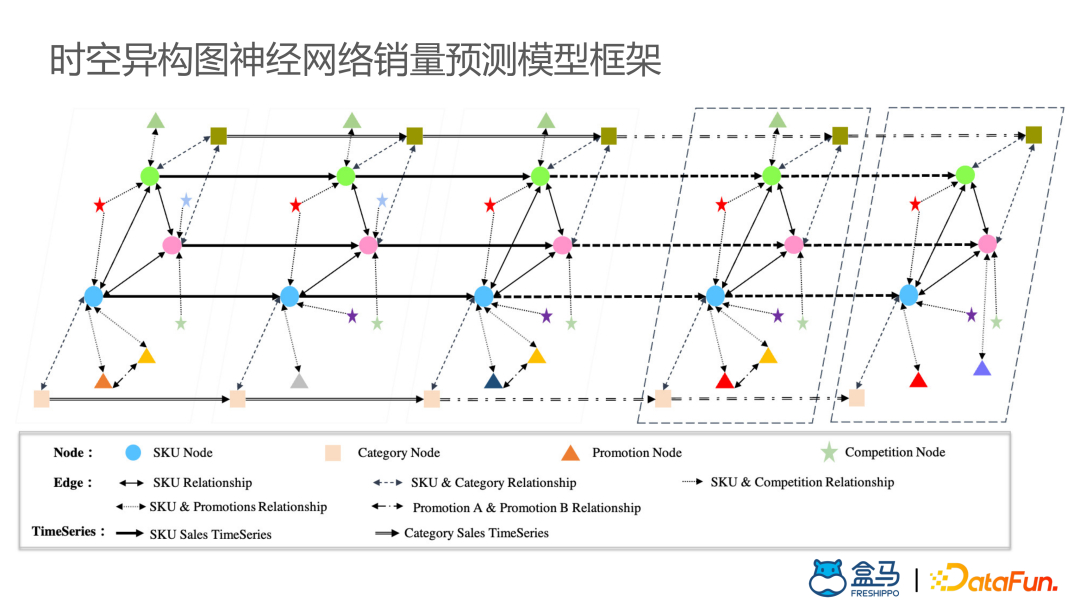
时空异构图神经网络销量预测模型
对于该模型,每个时间窗上构成一张商品销量和各种特征的已构图。在计算中,使用GraphSage、GATNE等算法提取每个时间切片上的图信息,由此获取点的信息更新,往下传递获取整个时序的信息。
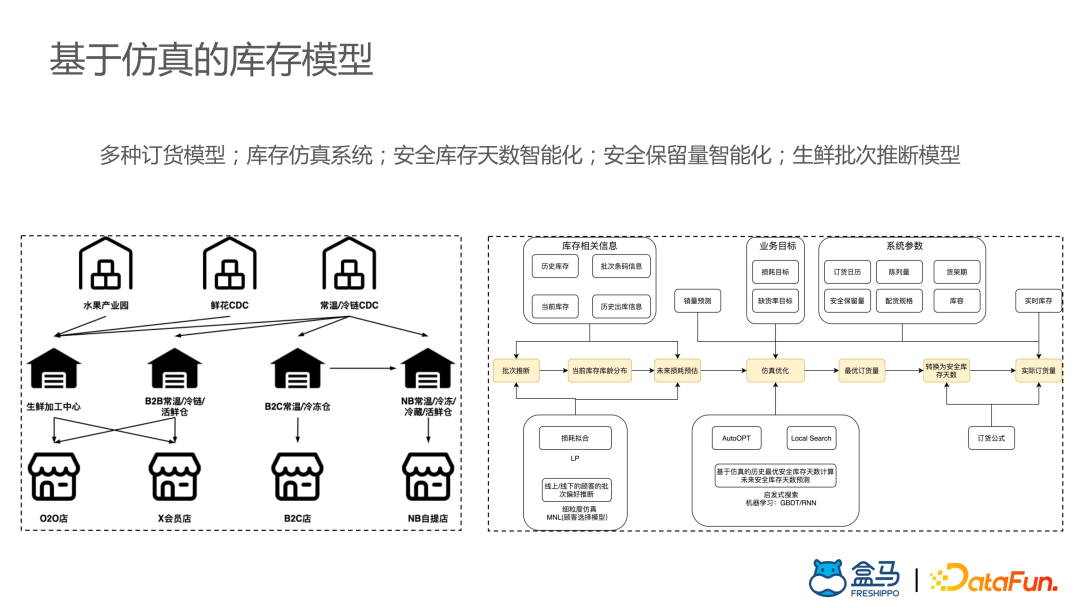
度小满自动机器学习平台实践
度小满自建的自动机器学习平台ATLAS。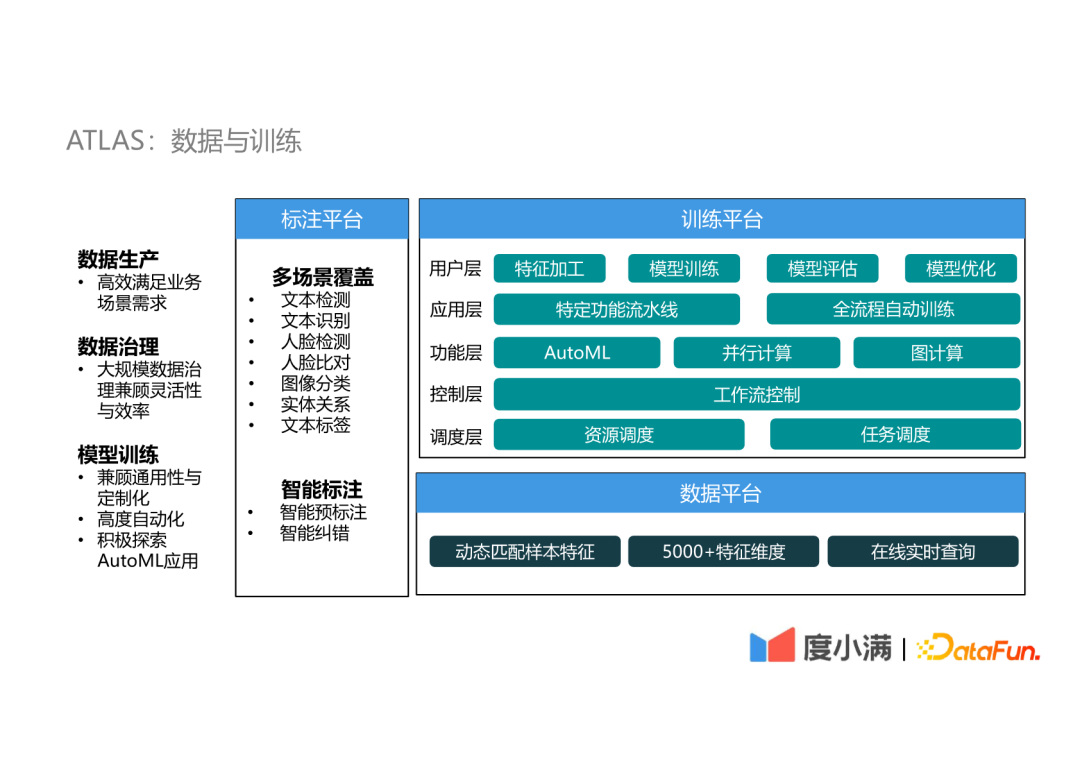
- 优化场景
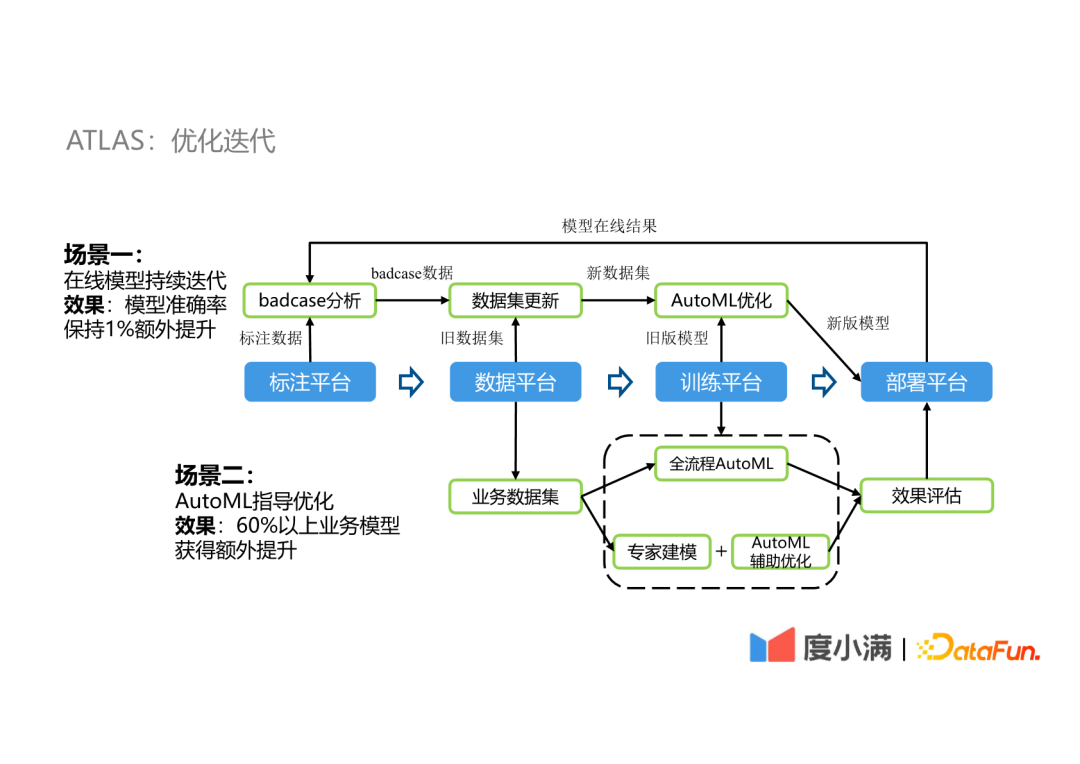
- 在线模型持续迭代
- ex. 一个OCR模型部署后产生一些bad case,将bad case和已有标注数据融合的数据集通过AutoML优化,部署优化后模型并持续改进
- 该过程能将OCR模型在原有基础上再提升1%
- ex. 一个OCR模型部署后产生一些bad case,将bad case和已有标注数据融合的数据集通过AutoML优化,部署优化后模型并持续改进
- AutoML指导优化
- 度小满内部有60%以上的场景在专家建模的基础上进行AutoML辅助优化
- 提升效果在1%~5%
- 度小满内部有60%以上的场景在专家建模的基础上进行AutoML辅助优化
- 在线模型持续迭代
AutoML技术
- 超参优化:黑盒优化(贝叶斯优化等);多保真优化(学习曲线、bandit等)
- 元学习:从任务性质或先验模型进行学习
- 历史任务的超参指导新任务的参数优化
- 应用场景1:已有数据集衍生数据集
- 应用场景2:数据集重复采样
- 历史任务的超参指导新任务的参数优化
- 网络结构搜索:搜索空间(基于Cell、基于MBConv)、搜索算法(RL、EA、可微分DARTS)
2022年世界科技进展100项
全球技术地图转载的一篇2022年科技进展总结。
- 生物医药方面多项进展
- 基因突变可能非随机产生
- RNA计算机
- 首例活人成功植入基因编辑猪心脏手术
- 猪蛋白人工眼角膜
- 考古与远古生命形态
- 小行星“龙宫”发现20+种氨基酸(这个之前那篇娱乐文有提到)

- 小行星“龙宫”发现20+种氨基酸(这个之前那篇娱乐文有提到)
- 深空&深海
- NASA改变小行星轨道
- 撞击造成的偏斜程度远大于预期
- NASA改变小行星轨道
- 新材料
- 完美的光传输和吸收材料
- DNA折叠法分子马达
- 全球首块柔性有机发光二极管显示屏
- 信息
- 量子计算机保真度达99%以上
- 首次实现两个逻辑量子位的一组计算操作
- 量子计算机Osprey,量子比特数433个
- 单个神经元构建神经网络
- 分布在时间而不是时空上
- 减少芯片算力限制和超算电力消耗
- 十四个光子有效纠缠
- 6G室外传输超过320m
- 100km量子通信系统
- AI
- DALL-E 2
- AlphaTensor & AlphaCode
- 生态与能源
- 核聚变反映净能量增益
- 氢燃料电池成本大降
- 效率超过40%的热光伏电池
- 锂离子电池极速充电
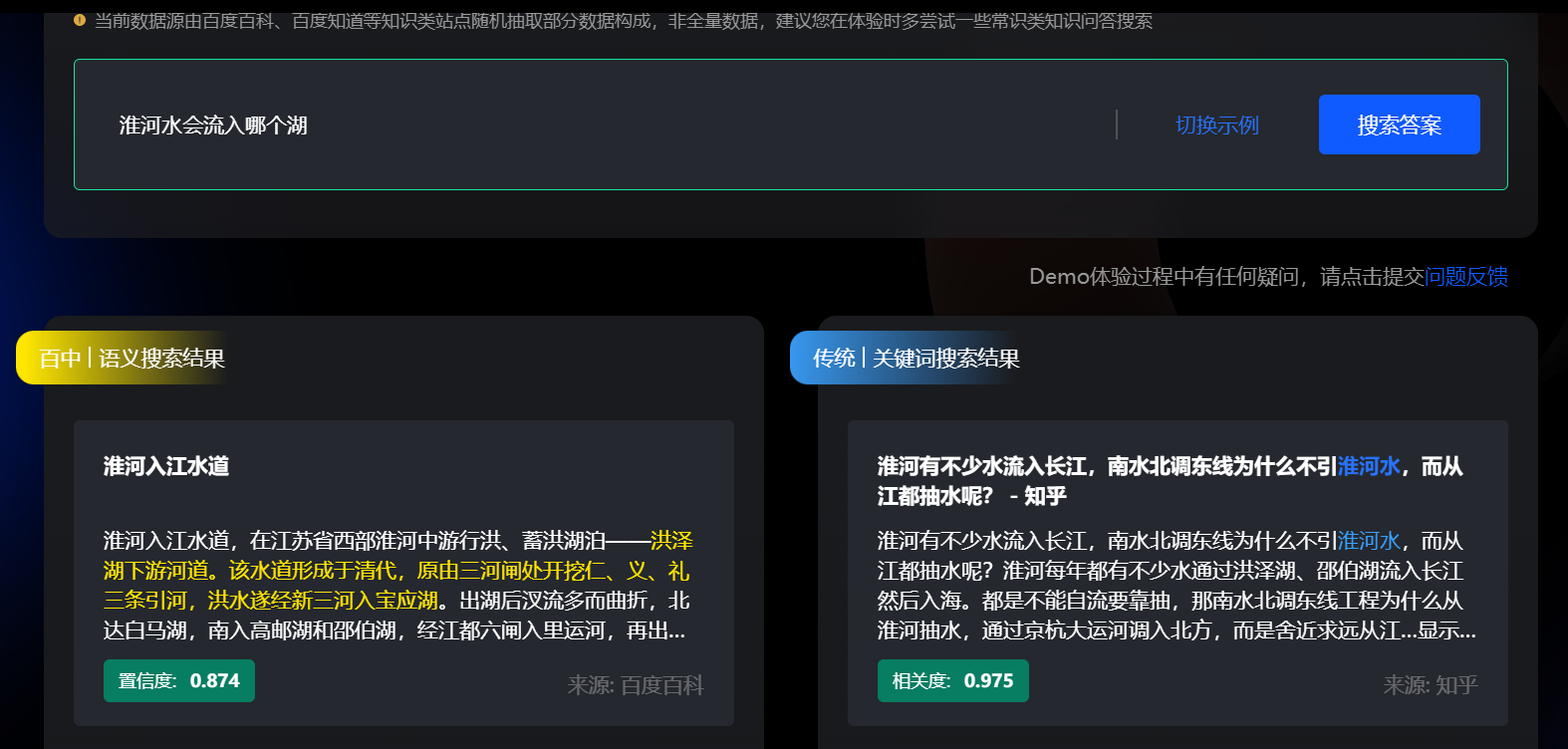
文心百中:大模型驱动的产业级搜索系统
百度预备推出的大模型驱动搜索系统文心百中,简单体验了一下。整体感觉偏向大众化,重在走量,专业内容上不行(当然语料质量就不行)。体验版上,感觉到的性能改进并不直观,搜索模式的改变对我而言影响也不大,毕竟之前就觉得百度关键字搜索的搜索符不太好用,多个自然语言的理解应该对多数用户而言也不算核心需求,毕竟都用了多少年了,不会有ChatGPT那种惊艳感。体验版在娱乐、生活上下了些工夫,我觉得可能盈利需求比较大,看重直接经营利润。
超详超硬Jeff Dean万字总结火热出炉!图解谷歌2022年AIGC、LLM、CV三大领域成就
自然语言处理
-
LaMDA模型提供高质量的对话,Jeff Dean表示谷歌让LaMDA符合事实(相比于ChatGPT)。
-
谷歌LLMs能够极大地帮助内部开发人员,为开发者减少了6%的代码迭代时间。
AI中经常遇到的挑战之一,就是建立能够进行多步骤推理的系统,将复杂的问题分解成较小的任务,并结合这些任务的解决方案,解决更大的问题。
- 思维链提示
- 模型在解决问题时展示步骤
- 谷歌基于PaLM语言模型提出Minerva模型
- 在数学推理和科学问题的基准套件上,Minerva都展示了SOTA
- 类似的提示微调也展示了巨大前景
生成模型
2014年生成式对抗网络GAN;2015年扩散模型
- Text-to-Image:Imagen模型基于扩散模型和大语言模型
- 在Imagen中增加语言模型大小比增加扩散模型的大小更有效
- 用户控制
- 用户对模型进行微调,根据文本和用户提供的图像组合生成新的图像
- 生成式视频
- Imagen Video & Phenak
- 级联扩散模型
- 双向Transformer
- Imagen Video处理短视频片段的超分辨率;自回归的Phenaki生成长时标视频信息
- Imagen Video & Phenak
- 生成式音频
计算机视觉
- MAXViT高级视觉
- MAXIM低级视觉
- 3D视觉
-
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., & Polosukhin, I. (2017). Attention is all you need. 收入 I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, & R. Garnett (编), Advances in neural information processing systems (卷 30). Curran Associates, Inc. https://proceedings.neurips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf ↩
-
Guo, M., Haque, A., Huang, D.-A., Yeung, S., & Fei-Fei, L. (2018). Dynamic Task Prioritization for Multitask Learning. 270–287. https://openaccess.thecvf.com/content_ECCV_2018/html/Michelle_Guo_Focus_on_the_ECCV_2018_paper.html ↩
-
Ma, J., Zhao, Z., Yi, X., Chen, J., Hong, L., & Chi, E. H. (2018). Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts. Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 1930–1939. https://doi.org/10.1145/3219819.3220007 ↩
-
Lymperopoulos, I. N. (2016). Predicting the popularity growth of online content: Model and algorithm. Information Sciences, 369, 585–613. https://doi.org/10.1016/j.ins.2016.07.043 ↩