学术相关
Avi Goldfarb—AI 颠覆行业的可能性:基于系统解决方案的新视角
多伦多大学罗特曼管理学院Marketing教授 Avi Goldfarb
《权力与预测》(Power and Prediction: The Disruptive Economics of Artificial Intelligence)
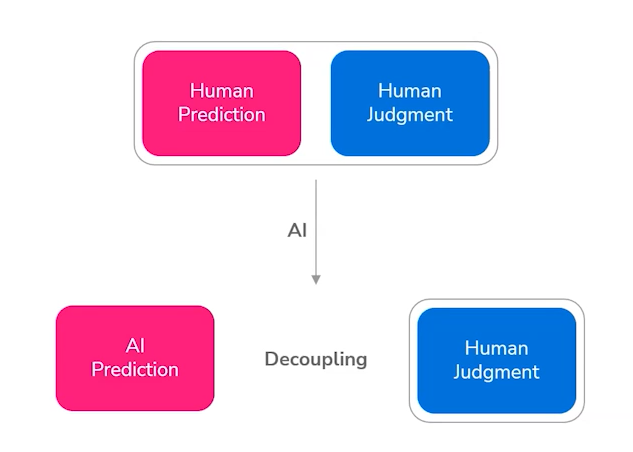
- 人工智能将预测和决策脱钩,用机器的力量提升大规模预测的能力以辅助人们的决策。
- 人工智能的发展仍处于初级阶段,如何根据人工智能的能力设计系统解决方案值得企业思考。
丹尼尔·卡尼曼曾说过:“毫无疑问AI即将胜利。人类应该如何适应这是一个有趣的问题。”
AI与预测
本次报告讨论的是近20~50年来机器学习这一人工智能分支对世界的影响,而机器学习就是一种预测的技术。这里的预测指的是一种Statistics Sense: Using information that you do have to generate information that you don’t have。
2018年作者关于这一话题的第一部著作《Prediction Machines》指出科技很清晰地显示了预测的成本正在快速下降,而经济学原理指出,越便宜的商品你就会越多的购买。事实上,随着机器学习的成本降低,人们所做的机器学习训练越来越多,人们逐渐认识到,越来越多曾经不被认为可预测的事情被纳入了预测的框架,例如疾病预测、药物设计、图像识别,以及OpenAI的一些工作。
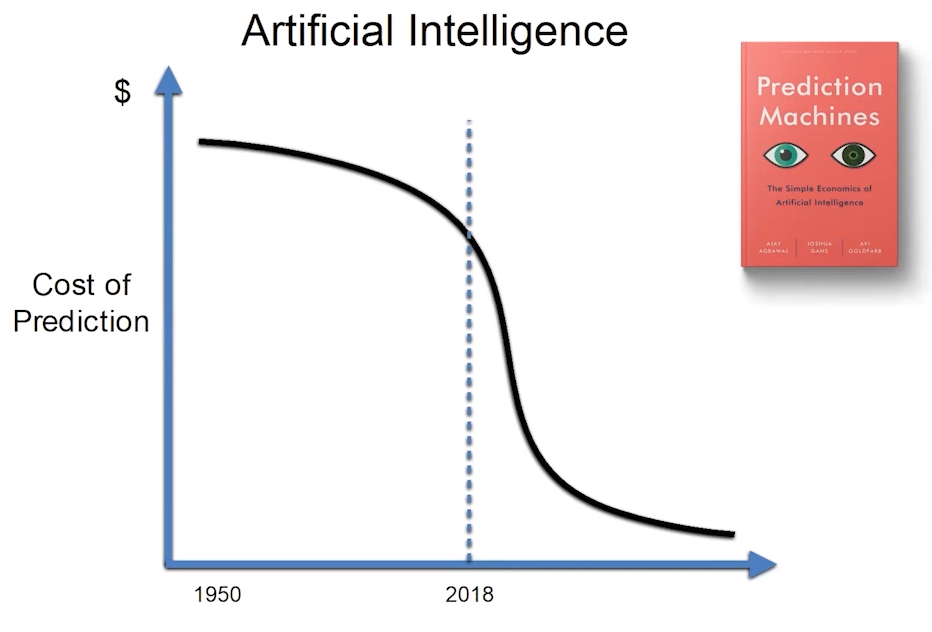
技术变革与生产力爆发
如今,许多公司都在着力于开发AI算法,在十多年前就有人,特别是Amazon这些公司,认为这些技术可以为精确地识别消费需求,为企业获取更多的利益提供巨大的帮助。然而,十多年过去了,很多当前的假设并没有发生,一个事实是从整体上绝大多数公司并没有应用AI,而使用AI算法的公司中也只有10%的公司反映认为它们从其AI花销之中收益。
那么我们应该如何理解精英口中的:“AI is more profound than electricity.”?从科学史上,1880s绝对是电磁学极其关键的一个时代,爱迪生改进了白炽灯,特斯拉发明了交流发电机。然而,直到40年后的1920s一半的美国家庭和美国工厂才开始电气化。
这是1880s的美国工厂,中央有一个巨大的蒸汽引擎。此时,工厂的组织被动力源所决定,这使得工厂的基本逻辑是如何降低动力损失。

一些企业家当时可能意识到了电气化会极大程度的降低传动带导致的动力损失且拥有更便捷的动力源。然而,结果却是他们并没有在1880s选择电气化,因为他们只是试图将过去的工作程序随意带入到新的程序中,并保持工作流不变,这种局部解决方案致使最终收益只有5%~15%,这并不足以弥补电气化的成本。
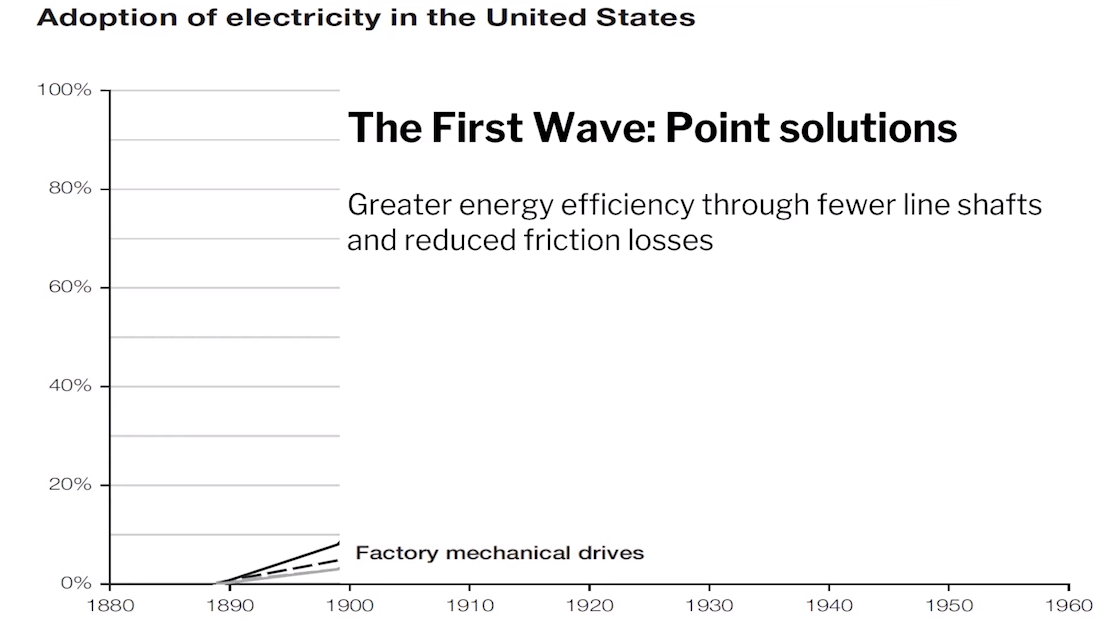
直到1900s,极少数的企业家才意识到电气化可能不仅仅意味着更便宜的能源,它更是一种分布式的能源,使工厂可以更灵活的组织生产设备,进而产生了20世纪美国工厂常见的流水线式生产模式,极大地提高了生产力。这种全局解决方案才是真正的电气化对生产力带来的影响。

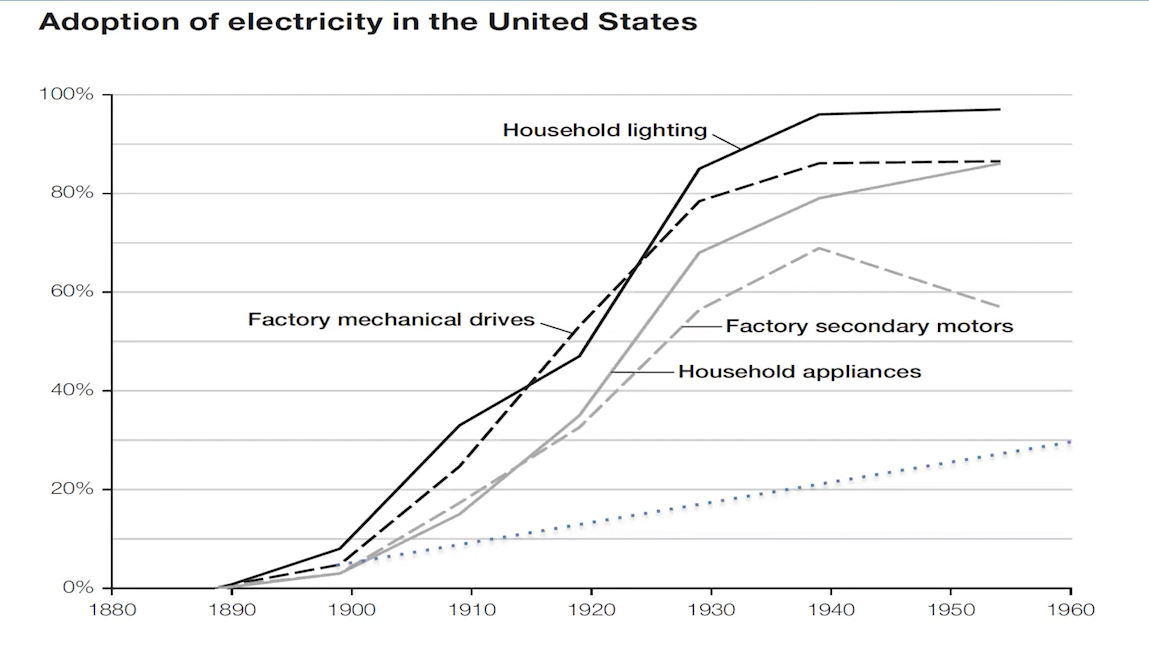
Avi认为,当下的我们就像是1880s的人们一样,我们看到了一个极具潜力的技术,我们拥有一些局部解决方案,使人们认为AI技术可能更能强大,但是目前并没有企业成功地从工作流的角度提出系统性解决方案。这就解释了前文所提出的疑问,问什么目前多数企业并没有使用AI,且只有10%的企业从AI应用中受益。
人机协作决策
30年前,欧美有许多人是职业汽车司机,他们工作的重点是将人们从点A高效、可达地带往点B。在伦敦,这项工作是一项硬技能,人们通常需要3年的学习才能获取taxi licenses。15年后,导航AI出现了,它最开始被用于点解决方案。在2009年,司机会认为导航对他们的工作帮助极大,他们可以更有效的工作。
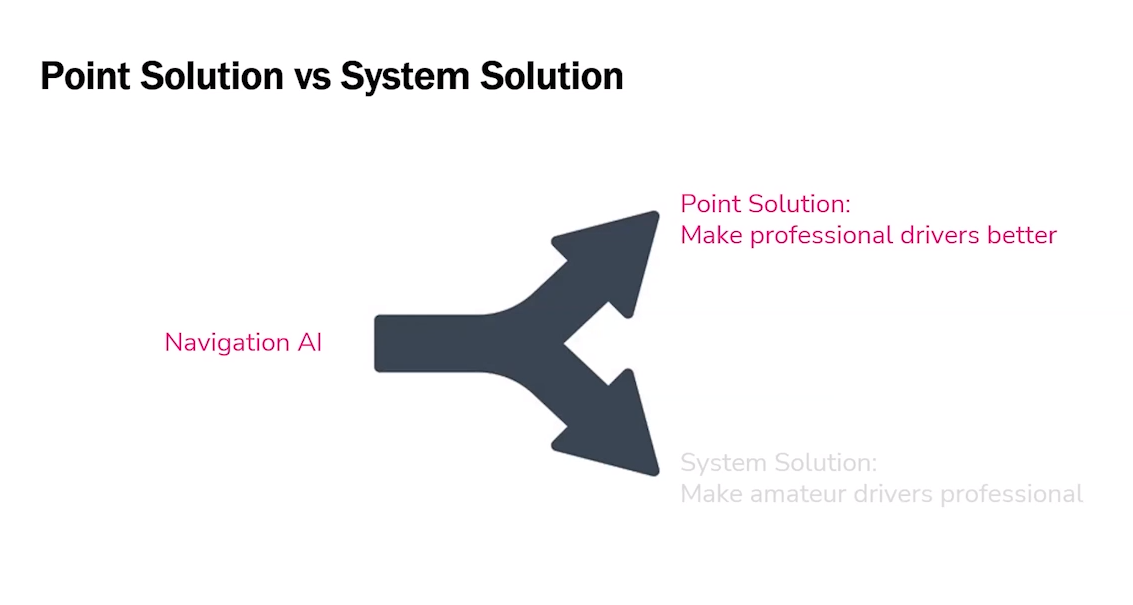
但直到人人都知道如何使用导航AI的时候,这个点解决方案才变成系统解决方案,它使业余司机变得职业化。
AI预测的最终目的就是做决策。作者将决策分为两类,一类是行动action决策,重点是预测,预测工作即分析世界不同状态的概率,AI革命使它可以被机器完成;另一种决策类型称之为判断judgment,它需要高水平的知识支持,如知晓应该完成哪些预测任务、预测的目的等,它更像是最终损益的效用函数,这部分将由人完成,但它将会被人机协作极大的改变。
人类目前的工作方式是将预测和判断同时在人脑中执行,AI的发展使这两部分可以被分离。而如果只是单独地利用AI进行决策,可能会出现公平性或过于孤立的看待问题,忽视其他系统性联系等问题。
人工智能与劳动市场
对于自动化对劳动份额替代的问题,Avi保持谨慎乐观的态度,“Yes and No”。每一项变革都会让一些人获利,一些人损失,而Avi认为通过AI获利的人会多于损失的人,虽然那些落后的人非常值得担心。过去的40年,互联网和计算机确实使欧美国家的不平等问题变得更严重了,过去的科技变革要求人们必须通过教育获取技能,进而使那些缺少技能的人面临严峻挑战。但这次生成式模型的出现可以增强那些缺少技能群体的能力,增强他们的边际产出。
行人和商业街零售的数据科学:将城市信息学推进到个体尺度的框架1
行人进入建筑的方式、原因是什么,他们是如何与环境和其他同行人互动的?这些问题是城市科学的关键概念。然而,不幸的是,行人现象通常很难被研究。其一,行人通常同时暴露在城市的多个方面上,难以区分;其二,行人通常以独特个体的形式与城市生活连接在一起,行人的观点常常稍纵即逝;其三,行人的行为尺度可以转化为双人、团体、人群到人流量较大的流动街景。但是,近些年的科技发展为我们提供了越来越多的数据信息,将城市信息学推进到个体尺度在理论上变得可行。虽然目前大数据存在一些问题,本文认为零售数据可以让这一方面更进一步。
行人在建筑中的行动一致被认为是城市信息学思想框架的一部分。本文基于商业街零售这一单一的环境,将消费者旅程在某种程度上视作一种具有特定目的的步行形式,试图在将经验数据与步行旅程相结合,在城市科学中提取步行的多样性和主观性。
消费者旅程作为零售业知识生产的框架
- 消费者旅程
- 在实体世界的零售中可能包括穿越店铺等
- 虚拟消费者旅程大多数环节会在线上进行,但最终会与实体店铺交互
- 消费者体验
- 零售接触点
- 零售服务场景
- 整合方法
零售消费者旅程与城市行人之间的现有数据对应关系
- 行人调查
- 行人日记
- 问卷调查
- 行人移动追踪
- 客流量
- 顾客识别
- AOI & POI
- 手动追踪
- 地理定位系统的行程揭示
- 许多中大型城市计划组织市民行程行为的长期调查
- GPS数据
- 电话登记访谈
- 许多中大型城市计划组织市民行程行为的长期调查
- Wi-Fi和蜂窝数据的行程揭示
- 地理推荐社交媒体数据
- 客流量
- 通过点分析城市事物
- 接触点
- 交通系统
- 数据挖掘城市活动探测
- 生活方式
- 城市场景计算机视觉
- 视频数据
- 视频行人追踪
- 监控
- 图像采集中的街景审核
- 视频数据
零售中行走与城市科学行走的推测性联系
- 城市全渠道 & 零售全渠道
- 数据可获性与大数据
- 借鉴零售数据方式
- 数据需求总是难以满足
- 数据时效性
- 快数据
- 边缘计算、GPS、Wi-Fi等
- 快数据
- 商业街信息系统
地理统计信息
控制实验
- VR
白天不懂夜的黑:社交媒体的参与内容在一天中是如何变化的?2
如何进行个人和群体决策:AHP层次分析法3
多人评价的话需要加权求和,并注意一致性检验
构建决策问题
在AHP中,一旦选定与决策重要相关的因素,我们需要按照整体目标到标准、子标准或连续水平层次排列这些因素。
构建层次需要考虑:表示问题尽可能详尽,但不至于彻底丧失对元素变化的敏感性;考虑问题背景环境;确定有助于产生解决问题的方案和属性;识别问题相关参与者。
层次结构不需要完整,即给定水平的元素不需要给所有下属元素设定函数。在判断完所有影响因素的影响并计算层次结构的优先级后,可以丢弃不重要的元素并重新计算优先级。
量表测量
如果仅仅随意设定优先级,他人可能不会信服。一些量化的方法中,相对而言最客观的是在特定标准下为备选判断分配一组数值,之后标准化这些数据(乘以数值和的倒数),使之位于$[0,1]$区间。注意,原始数据只带有序数,不包含距离或比率信息。
测量包含三要素:一组对象、一组数字、对象到数字的一组映射。相较而言,相对尺度更为适合。
比率的配对比较
最有效的比较方式是对一对元素在单一维度上比较,忽视其他维度或元素。假设给定$n$个对象$A_1,…,A_n$,其权重$w_1,…,w_n$,构建配对比较矩阵。
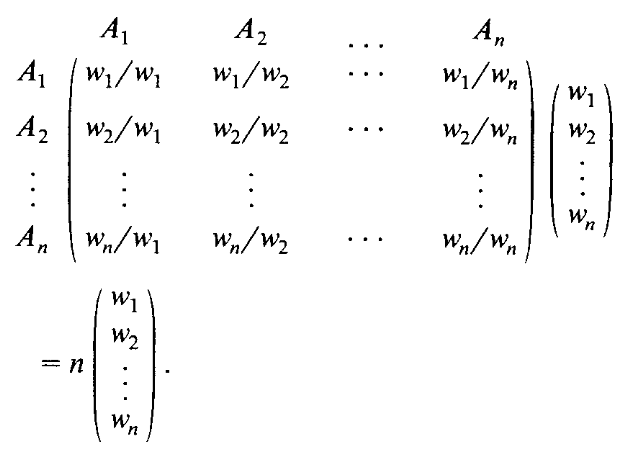
其中,若$n$为$A$的特征值,则$w$为对应的特征向量。此时,矩阵$A$的秩为1,每一行都是第一行的倍数,因此它只有一个非零特征值。特征值之和为矩阵迹,$A$的迹为$n$,$n$是最大的特征值。为使满足$Aw=nw$的$w$唯一,作者标准化了每一个元素。$A$中元素满足$a_{ij}=\frac{1}{a_{ji}}$。
一致矩阵必须拥有比率形式$A=\frac{w_i}{w_j}\ \ \ \ i,j=1,…,n$,A一致的必要条件是$A$可逆,充要条件是$A$的最大特征值等于$A$的阶数$n$。当$A$不一致的时候,就会在特征值附近小幅扰动。
由于实际决策环境中,我们无法给出$\frac{w_i}{w_j}$的实际值,只能由专家给出估计值,这个小的扰动导致一个特征值问题$Aw=\lambda_{max}w$,其中$\lambda_{max}$为$A$的最大特征值,此时$A$不再一致。因此,一个问题是$w$多大程度上真正反映了专家的意见。有趣的是,不一致性可以通过一个简单的数字$\lambda_{max}-n$度量。
令$a_{ij}=(1+\delta_{ij})\frac{w_i}{w_j}$,其中$\delta_{ij}>-1$为对$\frac{w_i}{w_j}$的扰动,$w$为$A$的主特征向量。
-
定理1:$\lambda_{max}\geq n$
$\lambda_{max}-n=\frac{1}{n}\sum\limits_{1\leq i<j\leq n}\frac{\delta_{ij}^2}{1+\delta_{ij}}\geq 0$
-
定理2:当且仅当$\lambda_{max}=n$时$A$为一致矩阵
一致性指数$CI=(\lambda_{max}-n)/(n-1)$,若CI显著的比从随机矩阵中得出的小(10%或更小),则采用$w$的估计值,否则尝试改进一致性。
执行程序
-
相对测量
-
构建层次结构
-
成对比较
评分粒度可以进一步缩小,如1.1等
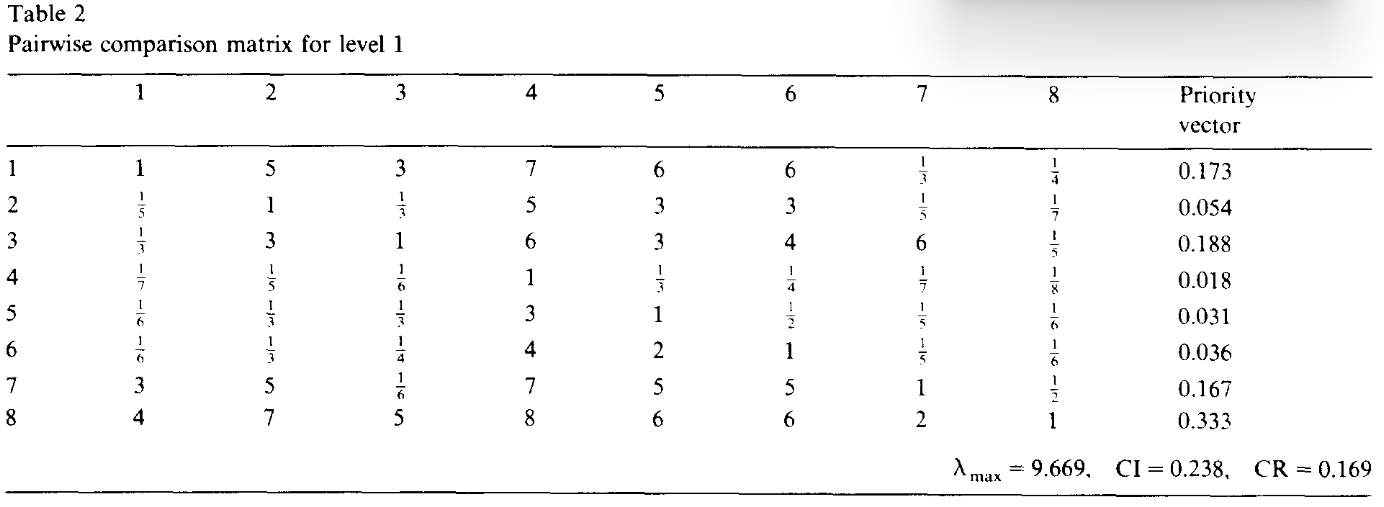
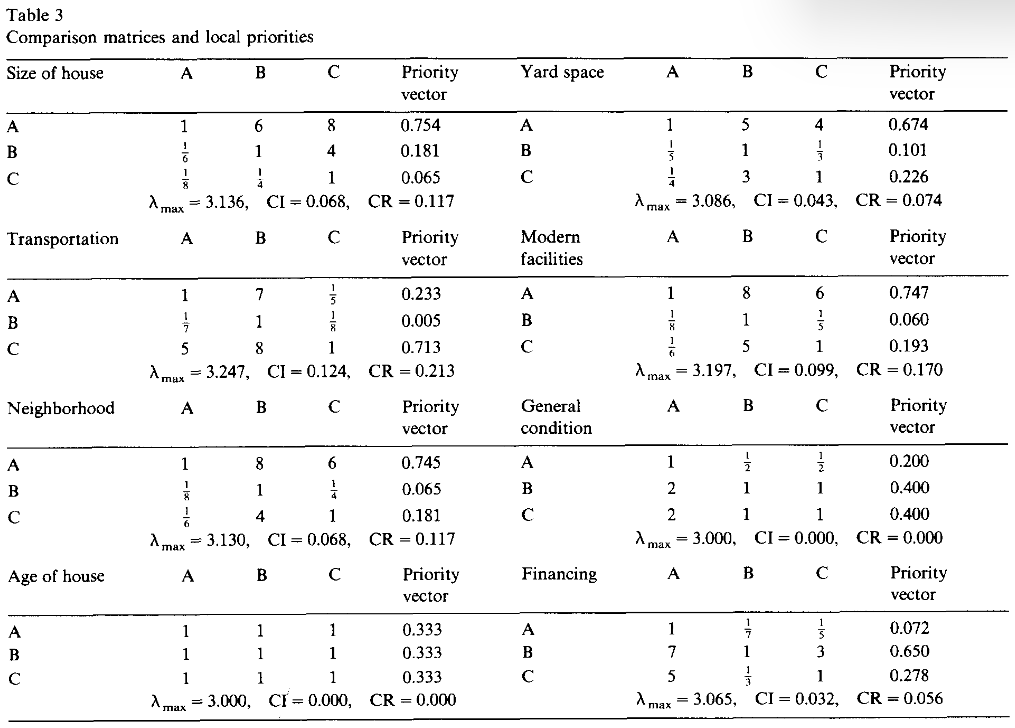

-
A是最佳选择
-
-
绝对测量
-
适用于按照标准的评级、强度或等级对备选方案排名
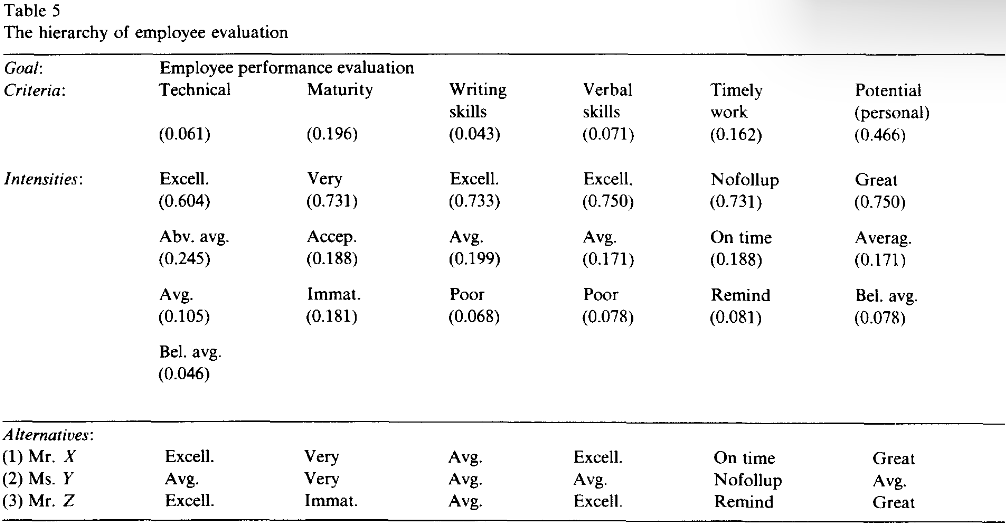
Mr. X得分为0.061×0.604+0.196×0.731+0.043×0.199+0.071×0.750+0.162×0.188+0.466×0.750=0.623
-
业界动态
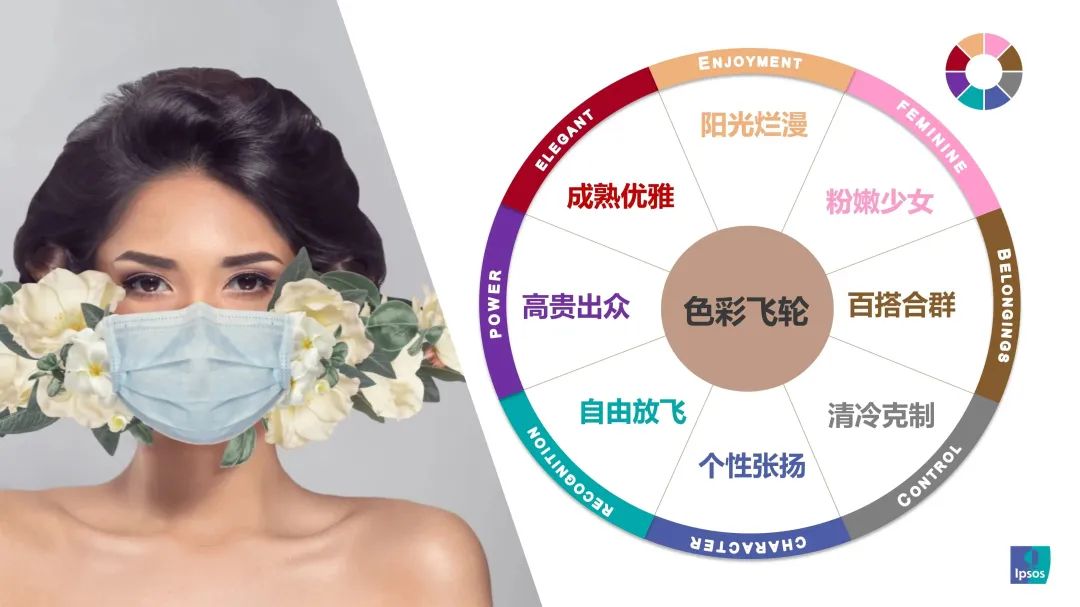
市场研究丨彩妆玩色:不同色系背后的消费者偏好与动机
一直对一些亚文化群体不是很理解,盖普索刚好作了一个调研《色彩主义——美妆色彩高相关品类洞察》,权作了解。
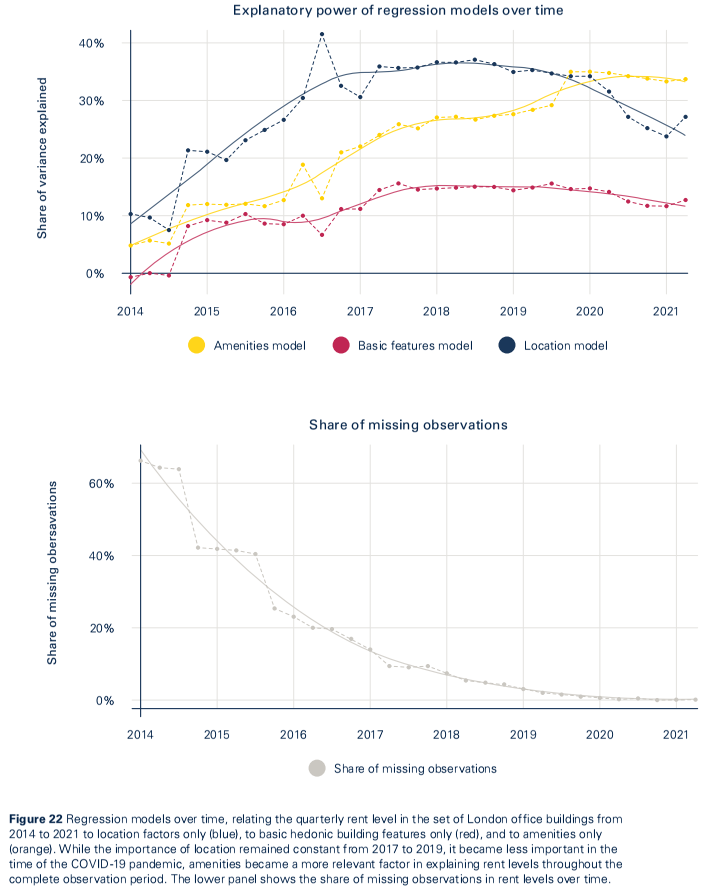
牛津大学:未来,办公楼的租金由什么决定?
前段时间好几个公众号转发了这篇文章,标题看着还挺唬人的,报告使用了多种方法,但是我觉得有些地方并不严谨,一度以为这是学生作业,但查了一下还真不是。这篇报告可视化方面有很多值得学习的地方,作图使用的是R。
本报告使用统计模型估计了设施和科技对伦敦办公楼租金的影响,着重讨论了主要科技趋势在近些年如何影响房地产市场的。主要结论包括:
- 地点、居住者的选择自由、员工意愿、设施和租金水平之间存在权衡,并随时间而持续变化
- 开发了一种手动收集多种网络渠道信息的方法,生成了伦敦办公楼关于地点、基本享乐性建筑特征和60余种设施和技术的数据集
- 与灵活装修有关的特点(如无柱式办公室)倾向于获取更高的租金;限制灵活性的设施(如模块化装修)则于租金呈负相关关系
- 可持续性和环保证书对租金有正向影响
- 绝大多数设施与租金水平没有显著性关系
- 可能租户不会感知为相关的质量信号
- 也可能没有足够的数据和可视化将之呈现给租户
- 数据缺失是限制房地产市场透明度的关键瓶颈
本报告的结果建议,除了位置,特定的设施——特别是与装修的灵活性、环境可持续性关乎预测租金水平。然而,许多与员工卷入度、工作效率有关的变量与租金水平不相关。
疫情、气候变化和数字化使基于办公室的工作发生了很大的改变。
COVID-19期间的居家政策使得许多办公室员工转向了远程工作,并迅速改变了CBD的办公室空间、装潢和地点需求,实体办公空间要与在线会议室相竞争,许多CBD的公司总部被城郊或农村地区的原子化办公室取代,办公楼租赁的影响因素需要以新的思路进行分析。在这样的背景下,工作效率和员工参与度(满意度、参与度、感染力)变得越来越重要。
租户参与平台Office APP 分享了关于该公司办公室活动的匿名化数据。
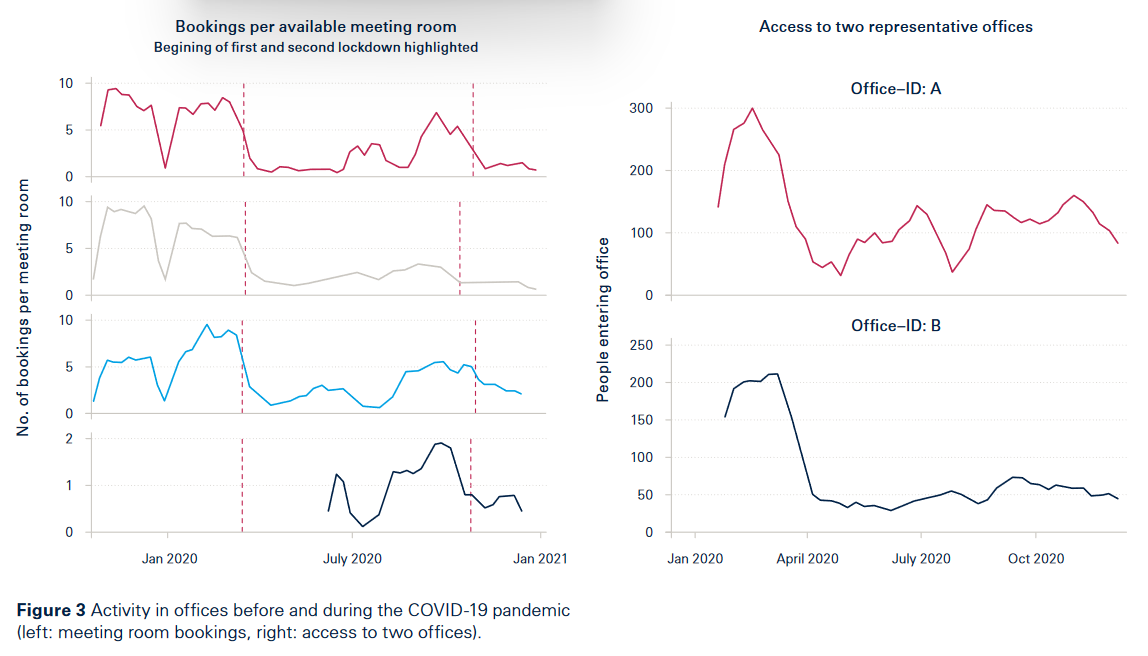
数据包含法国、荷兰、挪威、波兰在2020年的数据,红线是隔离政策期间,所有的数据都显示了隔离政策使办公室的订阅量了下降。
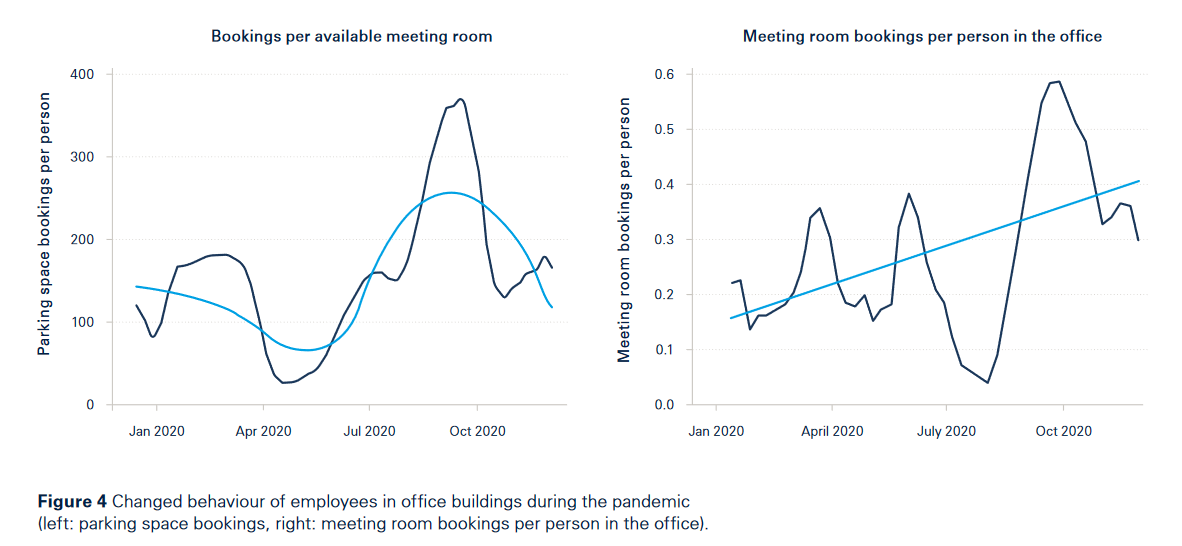
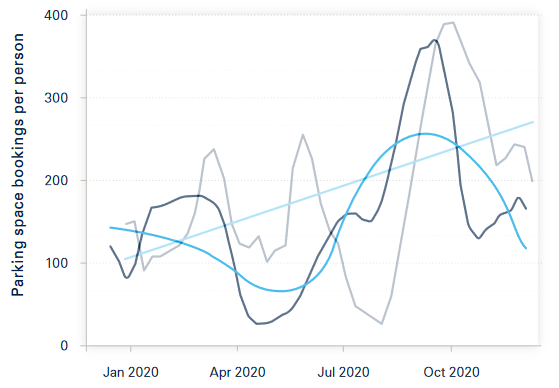
作者说:“非公共交通方式和每人会议室订阅都有所增多,即在大流行期间,来办公室的员工总数大幅减少,但办公室的人却有不同的目的,人们来办公室不是为了在办公桌或工作站工作,而是为了与同事互动和协作。”但我觉得这些数据并不支持作者的结论,而且很明显停车场预约和会议室订阅趋势并不完全相同,如5月前后的数据就有矛盾,这些作者都没有予以解释,同时也没有提供疫情前的数据。将上面两幅图叠影在一起的图像如下:
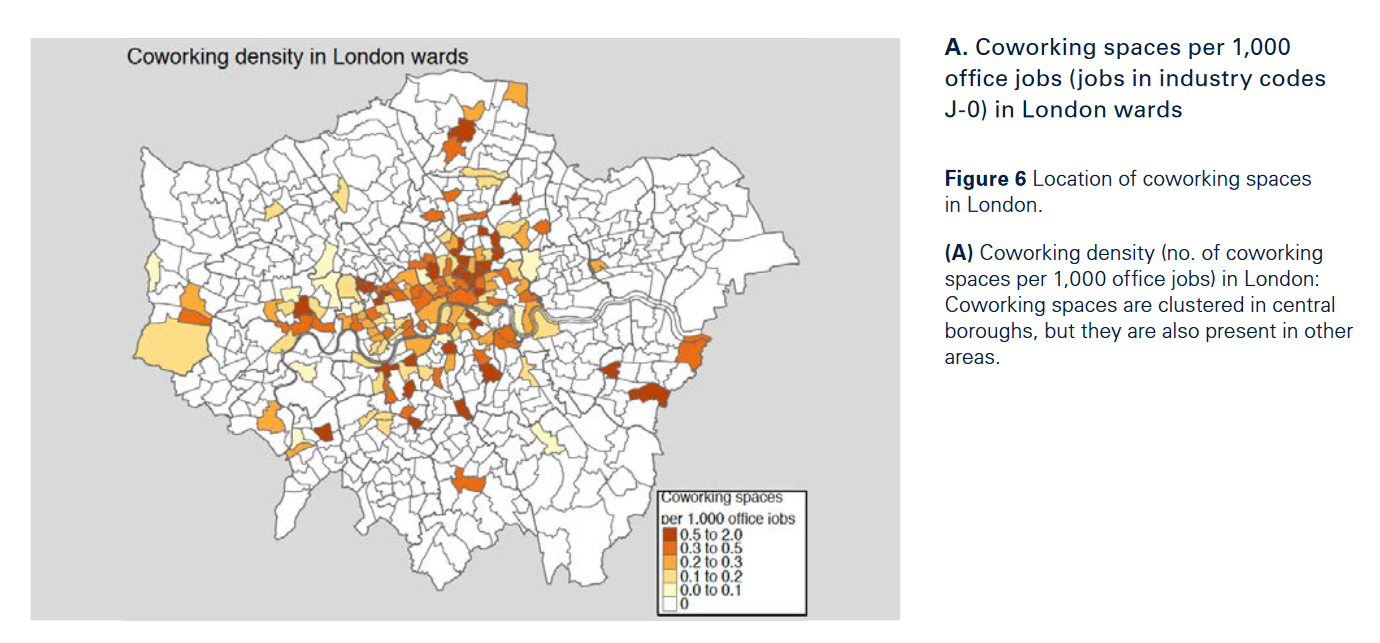
伦敦的共享工作空间分布,它与经济活动一样聚集于伦敦市中心。为减少经济活动带来的叠加效应,作者估计了每个区的工作岗位数,并将每个区的共享工作空间与工作岗位数作比,结果依然是聚集于市中心,但也有一些共享工作空间聚集于城市外围。
作者构建了与共享工作空间、共享工作密度相关的3个回归模型,但作者没有展示多重共线性检验等结果,且部分解释我认为存在问题。
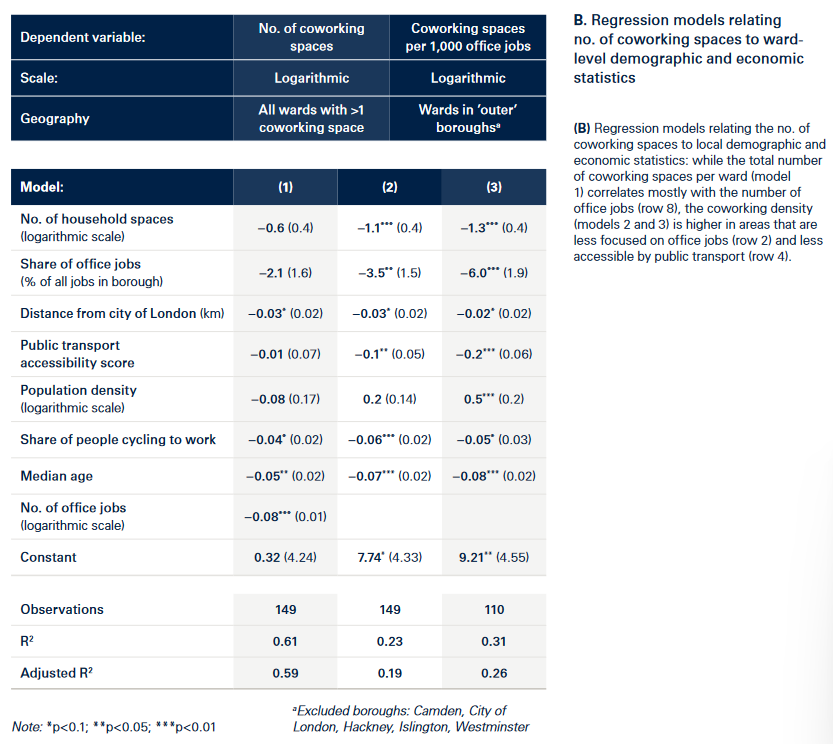
作者使用CBRE London City Rent Survey数据集对200个伦敦办公楼进行了量化分析,同时作者收集了20余个房地产网站的数据作为补充。
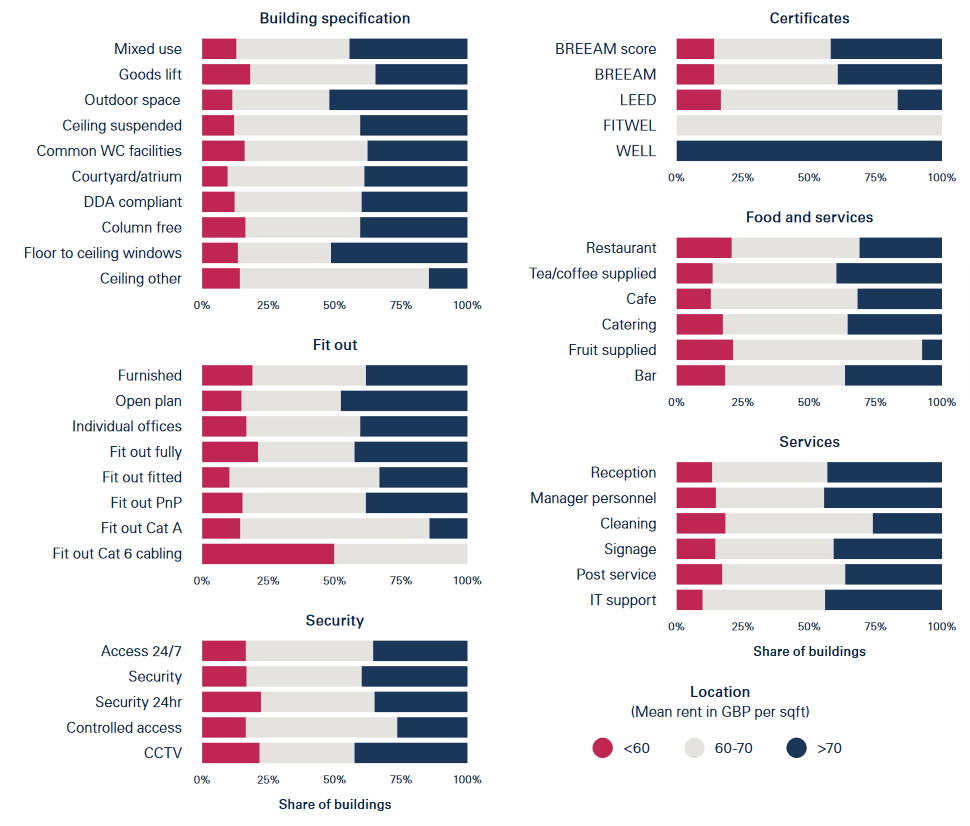
作者将一些办公楼设施特征与员工相关变量相联系。例如:
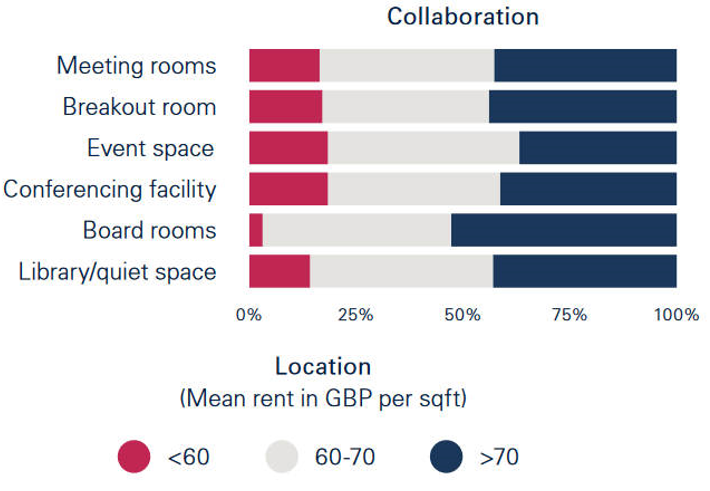
描述性分析展示了不同租金水平的办公楼的各类设施拥有情况:
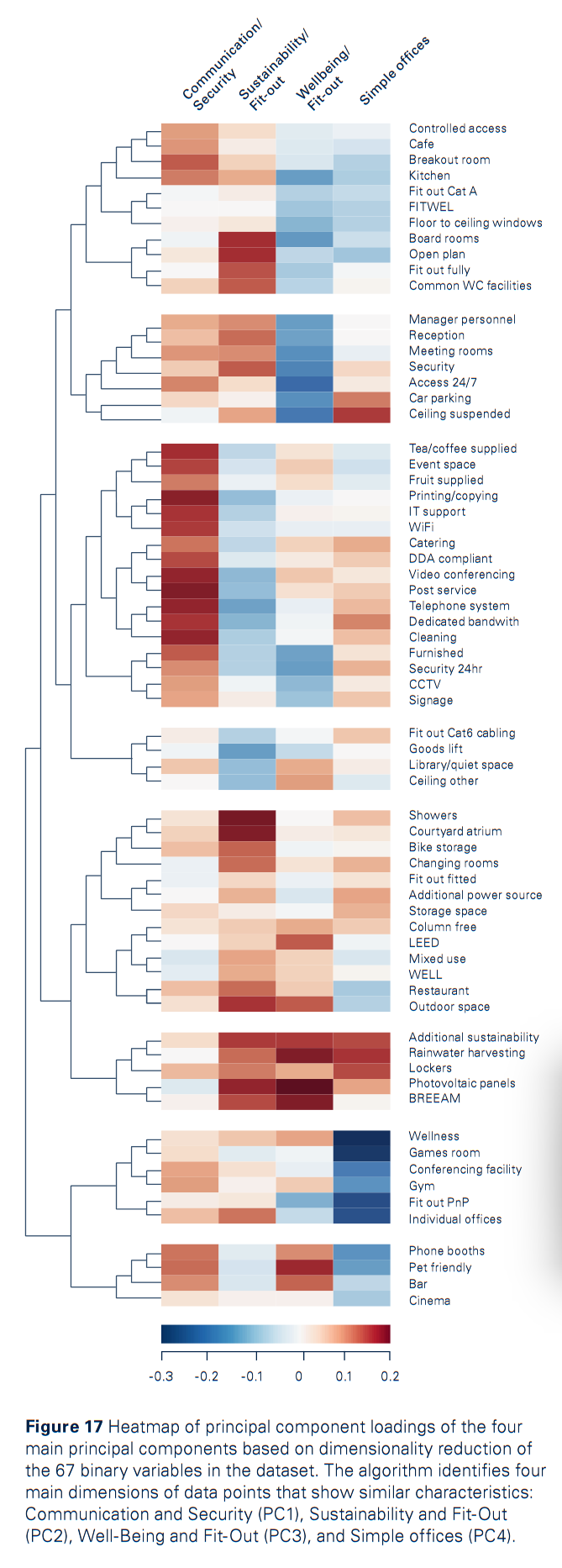
无监督统计学习:PCA & k-means聚类分析
作者把PCA的因子载荷和聚类结果画在了一起。
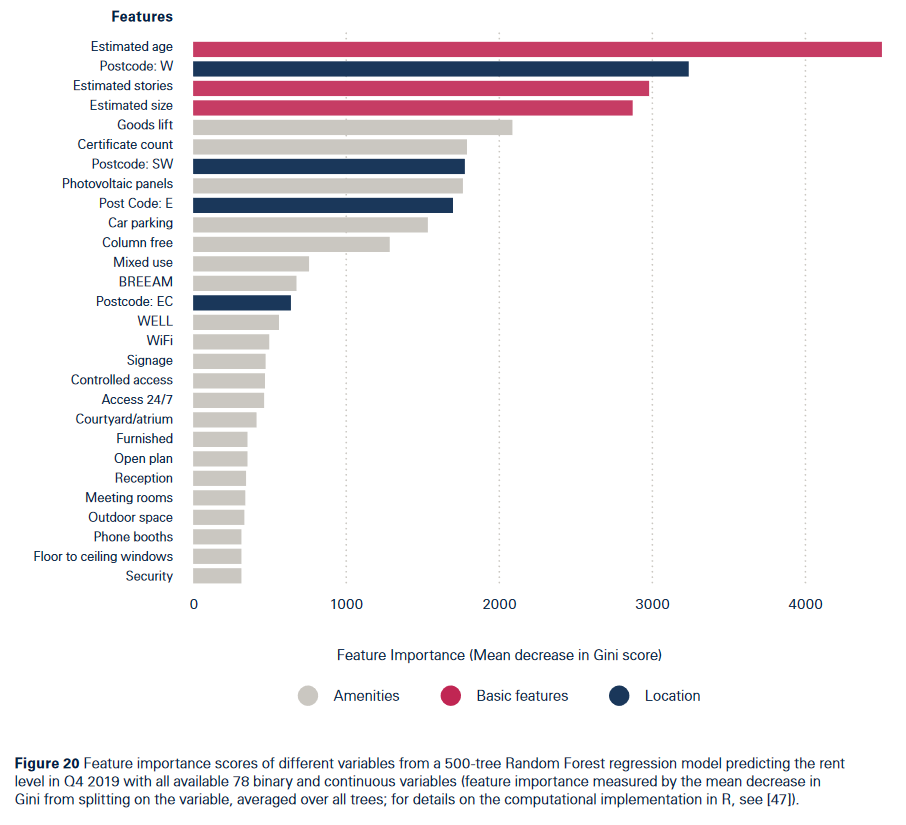
机器学习模型:特征选择
作者选择LASSO模型控制模型变量数量,重要变量可视化如下(R:glmnet包):
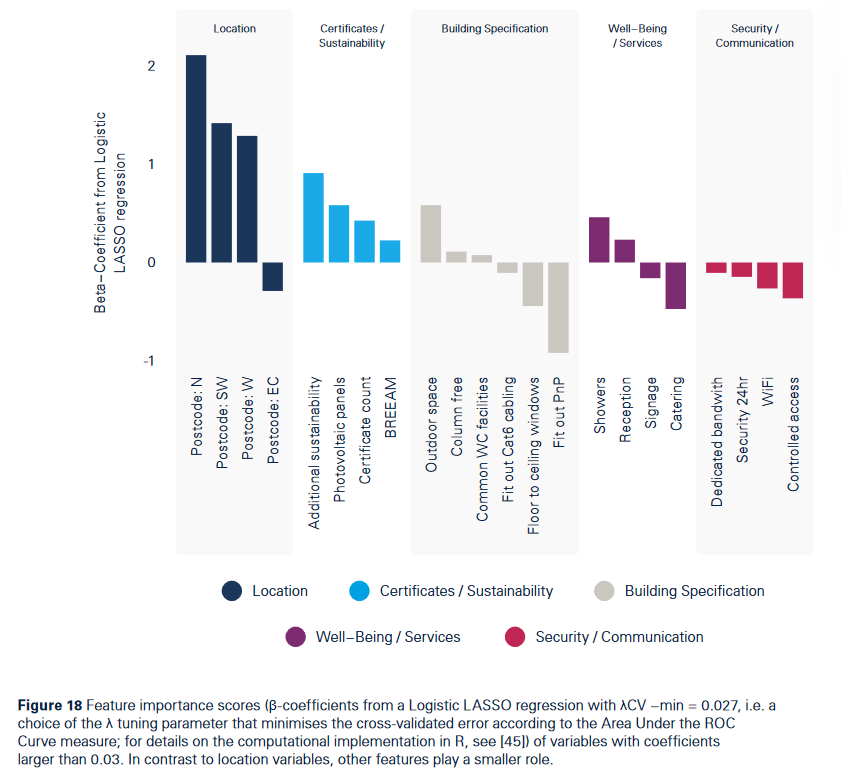
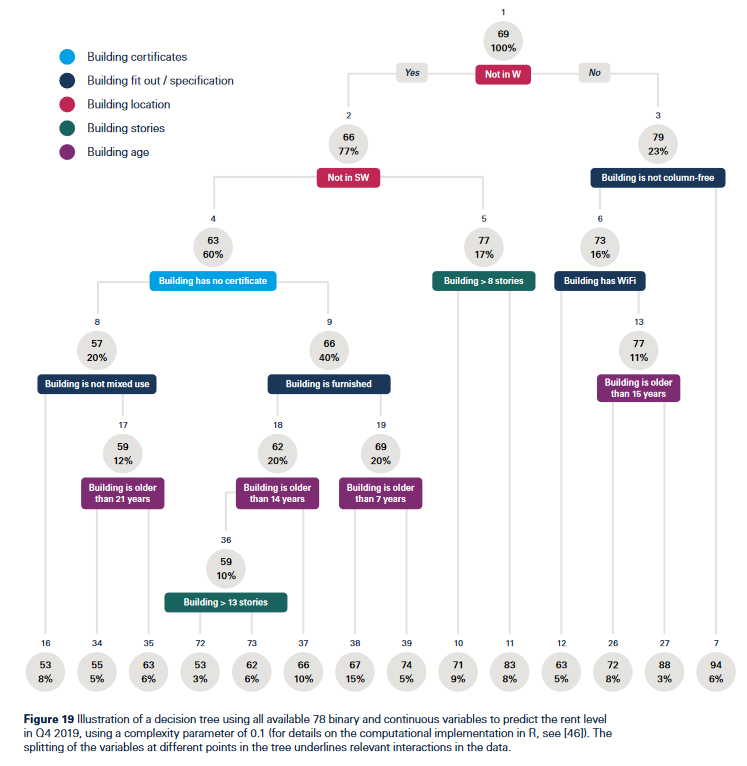
作者接着利用决策树模型确定设施之间的相互作用,及这些相互作用在预测租金水平方面的可能影响。
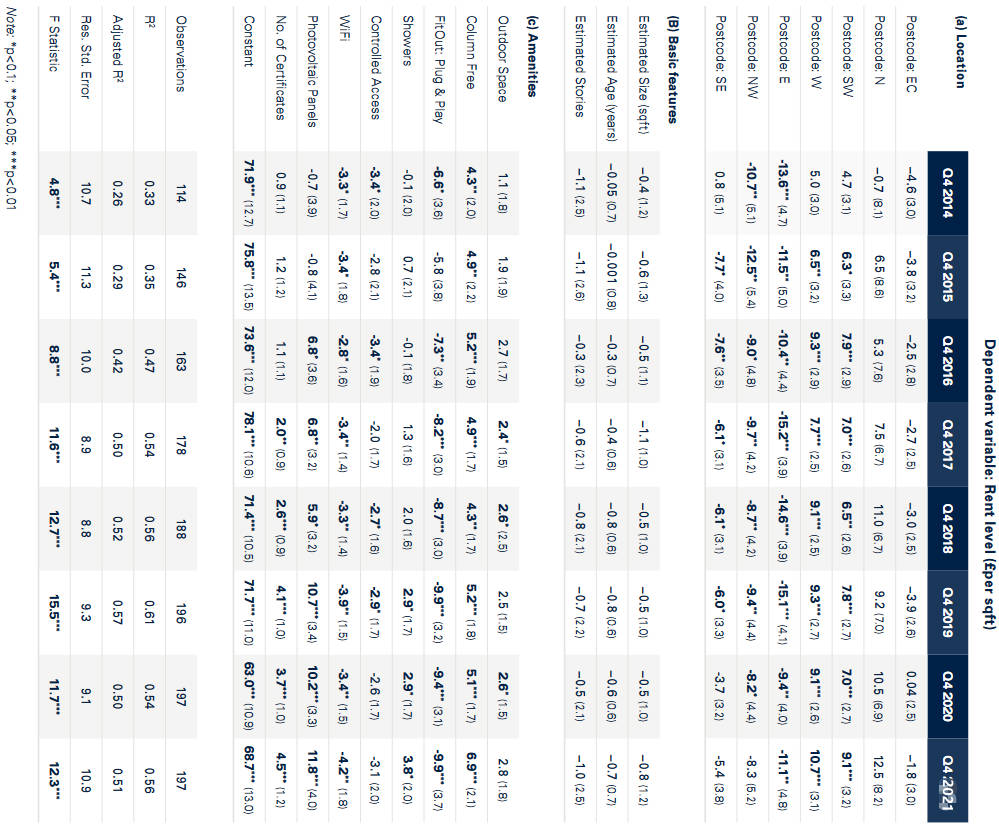
之后,作者利用这些变量构建OLS回归模型,模型解释了61%的伦敦办公楼租金水平方差,同时作者补充了2014-2021年的每年回归模型。
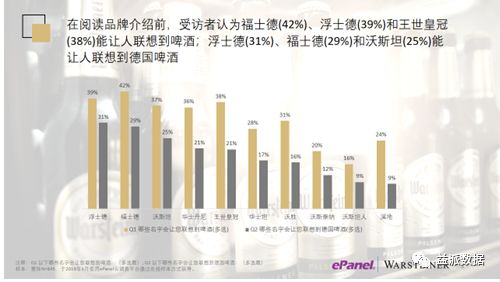
益派数据丨国际品牌中文命名实践
本报告的作者是德国啤酒品牌Warsteiner的廉晋青(Isaac)和北京益派数据有限公司的何建新。
这篇国际品牌中文命名案例综合了语源语义解析、文献、品类/品牌命名梳理、文字联想创意(工坊)、深访探测挖掘、8核心城市消费者量化云调查等常规和非常规的市场研究方法,并最终确定将Warsteiner翻译为沃斯坦。
品牌背景

Warsteiner是始于1753年,家族传承九代的德国最大私人酿酒厂,严格遵守1516年的德国啤酒纯净法,只使用大麦芽、啤酒花、水和酵母四种原料。目前,Warsteiner是德国出口量排名第一的啤酒集团,产品销往70余国家和地区,是多家航空和方程式赛车的指定赞助商。
研究目标
分析Warsteiner中文名称,并通过质性和量化研究测试译名。
研究程序(历时45天)
- 收集背景资料
- 观察产品实物
- 设计十个备选方案(+防御性商标申请)
- 消费者量化调查
- 确定名称
- 青岛啤酒节亮相
研究方法
- 头脑风暴
- 网络搜索
- 搜索对象
- 搜索引擎的行业品类和品牌
- 常用中文常用输入法和谐音
- 社交软件搜索
- 头部APP搜索
- 分析现有中文命名的优劣
- 提出30+个新命名
- 内涵、传播、品牌、包装、竞争角度考虑
- 搜索对象
- 网络搜索
- 质性研究
- 6~8场针对典型目标客户的面对面深度访谈
- 广告创意/流行设计/时尚
- 影视/娱乐/足球/音乐/艺术
- 互联网/金融/政界
- 啤酒经销商
- 啤酒爱好者
- 市场营销专家
- 产生6~8个候选名称
- 6~8场针对典型目标客户的面对面深度访谈
- 量化研究
- 8个主要城市开展800名被试的在线问卷调查
Warsteiner词源分析
- Warstein为德国人口不足三万人的城市
- 德文Wäster为Water水,Warstein拥有森林清泉,水质佳
- Stein德文是石头;斯坦(波斯字母:ـستان -,拉丁字母:-stan)是一个后缀,源于波斯文,意为“……的地方”,相当于(印欧语系印度-伊朗语族)印度-雅利安语支的“-sthana”。两者的词源都可追索至梵文的后缀,意思相近。“斯坦”常用于国家或地区的名称里,尤其是在中亚和印度次大陆(即古代印度-雅利安人的居住地)
作者借用北京第二外国语学院吕和发和潘文国的观点:“语音是第一符号系统,而文字形式是记载语言的符号,是第二系统。声音符号蕴涵了十分丰富的情感和意义,文字只能是‘符号的符号’”。但汉语存在表意特点,这对西方品牌翻译具有挑战性,因为西方品牌倾向于表音判断。
通常,品牌名称,使用的字数越少,越易记忆、识别和传播,四个字以上的中文品牌通常会被简化。
深度访谈大纲

深访排名
- 沃斯坦人
- 沃森
- 沃斯泰纳
- 浮士德
- 福士德
- 沃斯坦
- 华士丹尼
- 溪地
- 爵士
- 王世皇冠
问卷调研

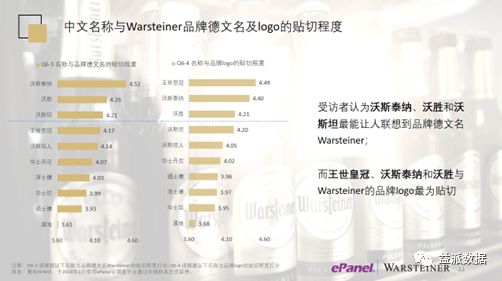
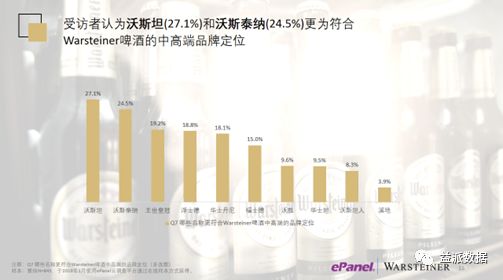
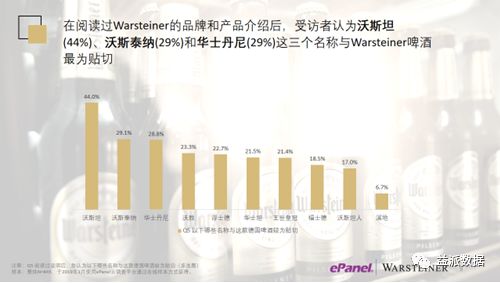
最终Warsteiner集团决定选用沃斯坦。
技术技巧
R包:程序结束提醒beepr
R版notify

| num | name | mean |
|---|---|---|
| 1 | ping | 乒乓声 |
| 2 | coin | 硬币声 |
| 3 | fanfare | 喇叭声 |
| 4 | complete | 完成声 |
| 5 | treasure | 宝藏声 |
| 6 | ready | 准备声 |
| 7 | shotgun | 猎枪声 |
| 8 | Mario | 马里奥 |
| 9 | wilhelm | 赫尔姆 |
| 10 | 脸书声 | |
| 0 | 随机 |
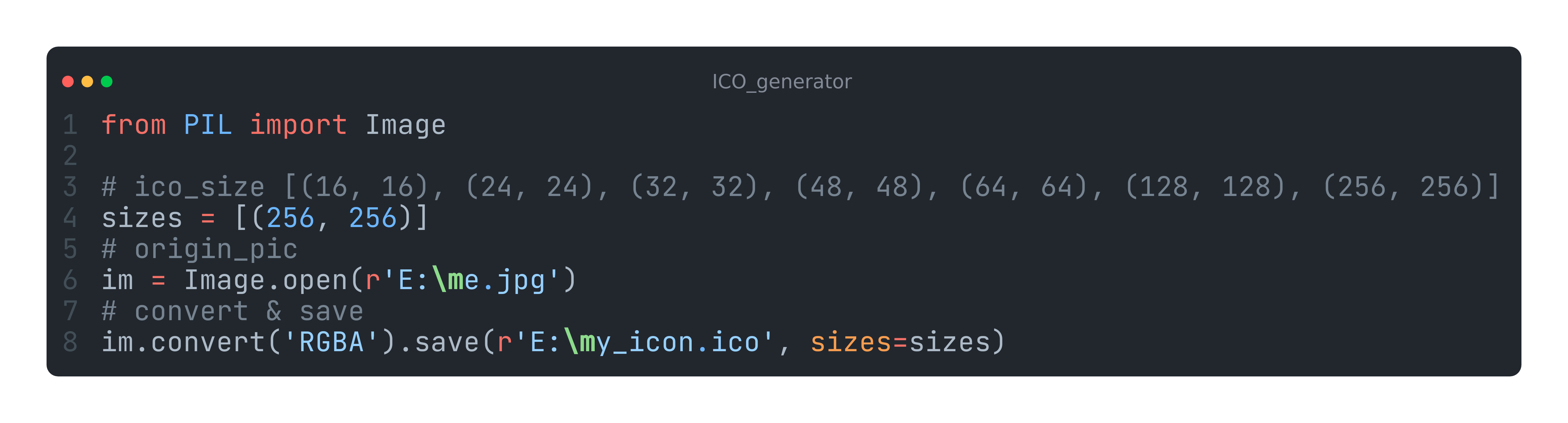
Python库:PIL输出ico图标
生成模型Prompt教程
国内一个用户写的ChatGPT和Midjourney开源教程。
Python库:PyTorch可视化工具
-
网络结构可视化
- HiddenLayer
- TorchViz
-
训练过程可视化
- tensorboardX
- HiddenLayer
娱乐
PNAS速递:三元影响定量衡量社会关系的兼容性4
本研究尝试以新的视角理解友谊形成,即社交网络中的链接预测。链路预测的难题在于时序网络:给定某些时间间隔内特定实体或节点连接图,任务是预测下一个时间间隔的链接集合。以往的研究由于数据难以收集,因此没有人成功研究真实世界的友谊形成问题。本研究了西班牙13所3359人60566条声明的友谊关系及他们自己认知能力(CRT测试)和亲社会关系的问题。作者将关系分为很好-很坏4级,分别编码为-2,-1,+1,+2。基于此,作者构建了有向加权网络,从友谊提名人指向被提名人,权重为关系评级,每一个结点代表着学生的个人属性(性别,CRT和亲社会关系)。
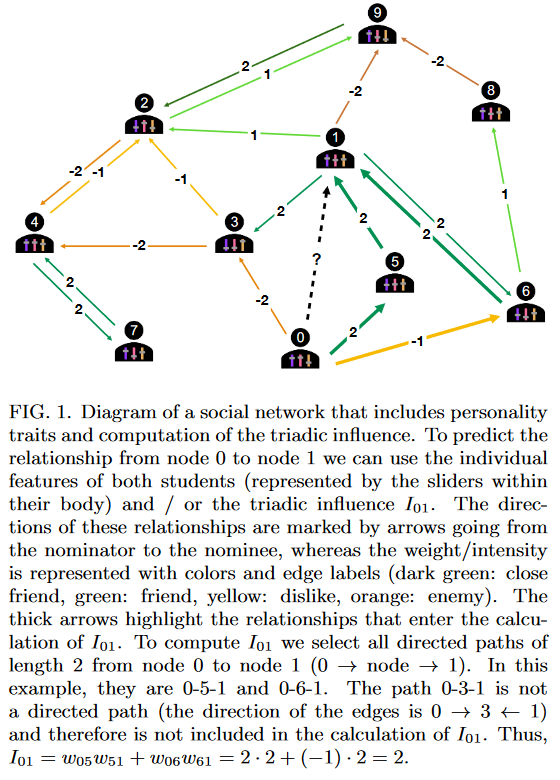
作者使用两种竞争的理论构建神经网络模型预测链路:
- 基于局部竞争:使用相连节点个人特征和最近邻影响
- 基于网络结构:只使用无向无权图预测
局部竞争方法
定义三元影响变量$I_{ij}\equiv(W^2)_{ij}=\sum\limits_{k}w_{ik}w_{kj}$,其中$w_{ik}$是节点$i$到$k$的权重,见图1。三元影响变量考虑第三方对友谊的影响
为简便起见,作者训练神经网络来分辨两类关系:朋友或敌人。深度神经网络的输入包含不同组三元影像关系组合和学生的个人特征,输出是一对节点的关系。由于数据存在不平衡问题(朋友远比地人多),作者采用了平衡精度(balanced accuracy)进行度量。$bAcc=\frac{1}{2}(\frac{N_{+}^C}{N_{+}^T}+\frac{N_{-}^C}{N_{-}^T})$
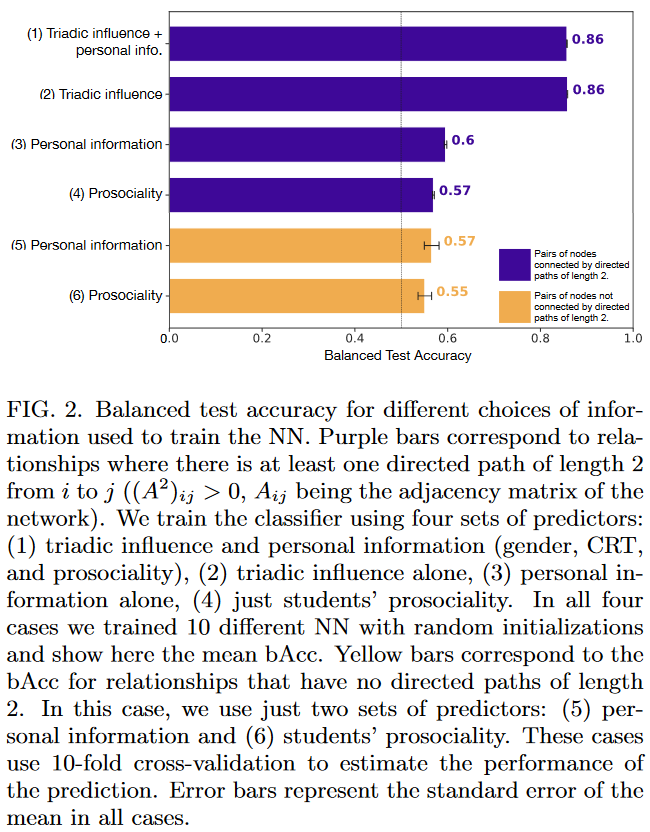
准确率最高的是使用三元影响作为输入的模型,无论是否添加个人信息平衡准确率均为86%。这意味着可能个人信息已经被三元影响信息包含在内了。
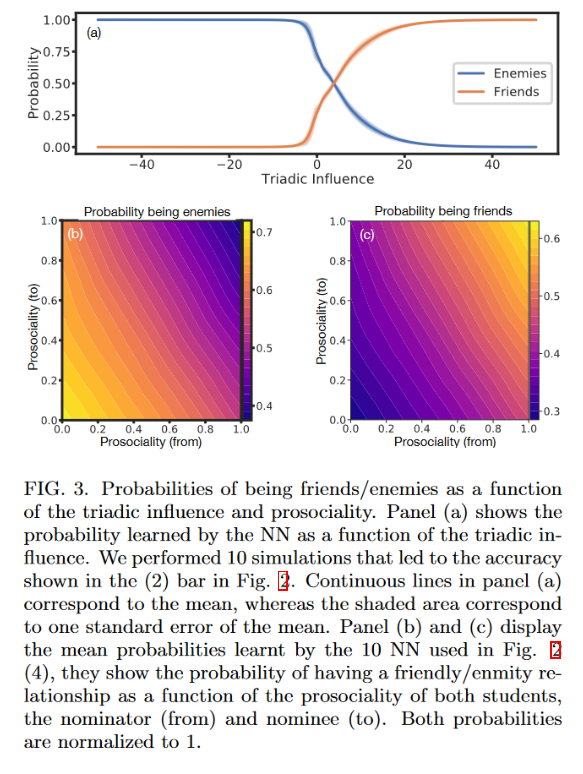
当三元影响$I_{ij}\gg1$时,该对节点为朋友关系的概率接近1,当$I_{ij}\lesssim0$时朋友概率接近0;当$I_{ij}\approx 5$时,朋友或敌人曲线交叉。
网络结构方法
使用Node2Vec进行128维Embedding作为输入,训练神经网络/随机森林模型。
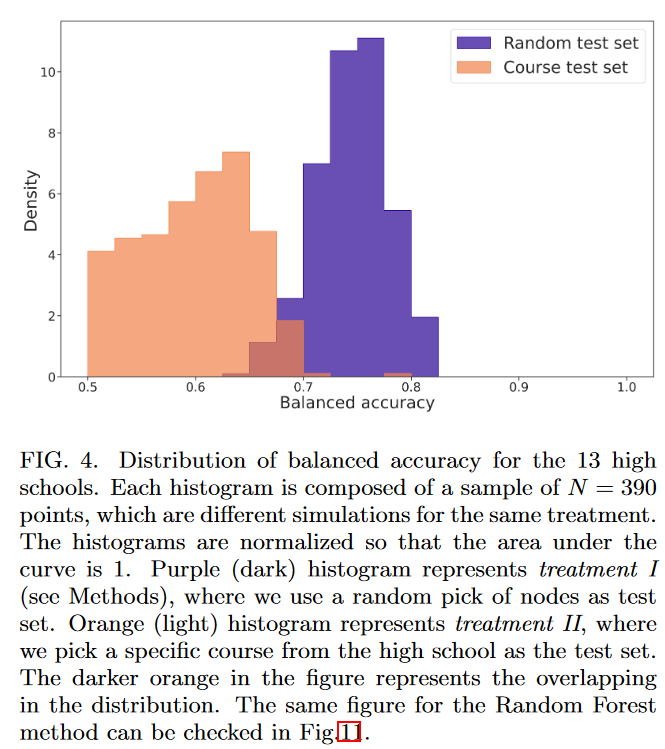
-
Torrens, P. M. (2022). Data science for pedestrian and high street retailing as a framework for advancing urban informatics to individual scales. Urban Informatics, 1(1), 9. https://doi.org/10.1007/s44212-022-00009-x ↩
-
Zor, O., Kim, K. H., & Monga, A. (2022). Tweets We Like Aren’t Alike: Time of Day Affects Engagement with Vice and Virtue Tweets. Journal of Consumer Research, 49(3), 473–495. https://doi.org/10.1093/jcr/ucab072 ↩
-
Saaty, T. L. (1990). How to make a decision: The analytic hierarchy process. European Journal of Operational Research, 48(1), 9–26. https://doi.org/10.1016/0377-2217(90)90057-I ↩
-
Ruiz-García, M., Ozaita, J., Pereda, M., Alfonso, A., Brañas-Garza, P., Cuesta, J. A., & Sánchez, A. (2023). Triadic influence as a proxy for compatibility in social relationships. Proceedings of the National Academy of Sciences, 120(13), e2215041120. https://doi.org/10.1073/pnas.2215041120 ↩