学术相关
Generative Agents: Interactive Simulacra of Human Behavior1
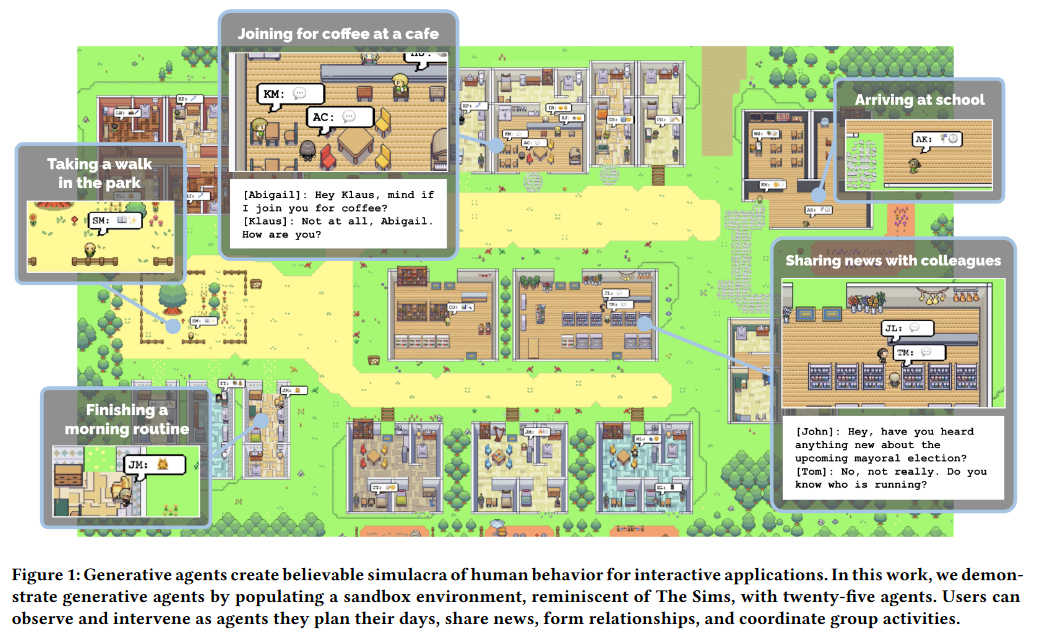
在这项可信人类行为(LLMs:看起来真实、自然的人类行为)智能体模拟研究中,作者构建了一个大语言模型的拓展架构来存储智能体的自然语言经历,并随时间发展综合这些的记忆以形成更高层次的深思,通过动态检索这些深思实现计划行为,最终使25个初始化在一个类似于模拟人生游戏交互沙盒中的智能体可以实现起床、做早餐、工作并进行互动。此外,作者还通过消融实验证明了这个智能体架构的3个组成部分:观察、计划和深思都对智能体行为的可信性做出关键性贡献。
在前人的研究之中,尽管LLMs取得了极大的进展,可以模拟单个时间点上的可信人类行为,但是可以确保长期一致性的完全通用智能体将更适合管理随互动、冲突和事件发展与时间推移不断增长记忆的架构,同时也可以处理多智能体之间展开的级联社会动力学。这一效果的实现需要架构可以在很长一段时间内检索相关的事件和互动,对这些记忆进行深思以归纳得出更高层次的推论,并应用这些推论来创建计划和反应,使这些计划和反应在当下时刻及长期的尺度下都是合理的智能体行为。一个由生成式代理构成的模拟社会,展现了信息扩散、新关系形成和智能体之间协调的社会动态特性。
作者提出的大语言生成式架构包含3个主要组价:
- 记忆流 memory stream
- 长期记忆模块 long-term memory module
- 使用自然语言记录的智能体经历的综合列表
- 检索模型 retrieval model
- 结合相关性、回顾性和重要性提取智能体即时行为所需要的信息
- 长期记忆模块 long-term memory module
- 深思 reflection
- 综合记忆并随时间形成高层次推断,使智能体可以对自身和其他智能体进行总结,更好的指导自身行为
- 计划 planning
- 将深思的结论与当前环境转译成高层次的行动计划,之后递归到具体的行为和反应
- 深思和计划的结果将被反馈到记忆流组价中影响未来行为
这一架构预示着许多领域的应用价值,包括社会角色场景模拟、社会研究和游戏开发等。这一篇论文集中在类似于模拟人生的小型交互智能体社会。通过联结ChatGPT,作者在游戏环境中构建了25个智能体,终端用户可以对这些智能体进行观察和交互。例如,如果终端用户希望沙盒中举办一场聚会,传统的游戏环境需要手动地为角色编写脚本;而生成式智能体只需要告诉其中一个智能体,希望它举办一场聚会即可,虽然这场聚会的举办可能失败,例如它忘记了告诉其他智能体参加。
作者为智能体设计了两个评估:控制评估用于测试智能体在孤立情况下能否产生可信的个人行为;端到端评估通过2天的游戏时间生成式智能体以开放方式互动,分析其稳定性和出现的社会行为。
在技术评估上,作者通过自然语言对智能体进行“面试”,评估智能体的知识和行为,以探索它们在保持性格、记忆、反应和深思保持准确的能力。
作者比较了几种限制智能体获取记忆、深思和计划能力的消融实验,结果表明这些组件都具有关键作用。
在整个技术评估和端到端评估中,智能体最常见的错误是未能检索到相关记忆、对记忆进行编造或从语言模型中继承了过于正式的语言或行为。
文献综述
人类-AI交互
交互式人工智能系统致力于将人类的洞察力和能力结合到可以增强用户的计算工具之中。前人的工作已经表明我们可以创建交互系统中代理人类行为的智能体,并能够通过自然语言实现交互。
这项研究重新打开了围绕着认知模型(GOMS、KLM等)、原型(UI设计等)工具和泛在计算应用(高可移植、自适应等)等研究基础人机交互的大门。
人类行为的可信代理
可信智能体旨在提供一种生活幻想,使它们呈现出按自身意愿决策和行事的实现主义表象,类似于迪士尼电影中的人物。这些智能体可以根植和感知在一个像我们生活一样的开放世界,并努力表现出与用户或其他智能体的社会互动行为,目的是在个人和社区的假设仿真中成为人类行为的可信代理。
历史上,这些智能体通常被开发为智能游戏的NPC,但如今游戏世界提供了越来越真实的世界呈现。
过去四十年间,学者们创建了多种不同的可信代理,但在实际中,这些方法往往简化了环境或降低了智能体行为的维度,使其更加可控。
基于规则的方法,如有限状态机和行为树展示了人类编写智能体行为的蛮力方法,这种方法至今还是主流方法。然而,在一个开放世界中,人工构建方法是不可能解决全部互动的,它所产生的智能体行为并不完全基于互动,也不能质性脱离脚本的新程序。
盛行的基于学习的方法,如强化学习,通过让智能体学习它们的行为克服了人工编写的挑战,并在近年来的游戏中取得了出色表现,如《星际争霸》中的AlphaStar和《Dota2》中的OpenAI Five。然而,它们的成功很大程度发生在有清晰奖励定义的对抗性游戏中,使学习算法可以进行优化。它们还没有解决在开放世界中创建可信智能体。
由NeWell开创的计算中的认知架构旨在建立一整套认知功能的基础设施,以适应最初设想中的可信智能体的全部性质。如第一人称射击游戏中Quakebot-SOAR和ICARUS生成的NPC、空战模拟器中TacAir-SOAR生成的飞行员。这类算法保持了长短期记忆,并使用符号填充这些记忆,在感知-计划-行动循环中运作,动态地感知环境,并将之与人工设计的行动程序之一相匹配。这类认知架构可以生成绝大多数,甚至全部的开放世界内容,并展示可靠的行为。然而,它们的行动空间局限于人工创建的程序性知识,且不能激发新行为,因此常被部署于非开放世界,如第一人称射击游戏或方块沙盒。
如今,可信智能体仍然是一个棘手的问题, 许多人质疑它或许只能止步于此,但作者认为大语言模型为这一问题赋予了新的基于。
大语言模型与人类行为
生成式智能体利用大语言模型为智能体赋能。一个关键的事实是,LLMs在其训练数据中标注了海量的人类行为,如果存在一个给定的详细语境,LLMs就能生成可信行为,近期的研究对这一方法的有效性已经有所证明。例如,社会仿真使用一个LLM生成用户,这些用户被填充到一个新的社会计算系统中,为其社会动态提供原型2。该方法使用一个提示链生成关于系统中作为原型的个体及其行为的简短自然语言描述。
类似的实证研究被用于社会科学研究、政治调查和生成合成数据等用途,游戏上,LLMs已经被用于创建交互性小说、文字冒险游戏等。由于LLMs具有创建和分解动作序列的能力,它也已经被用于创建机器人任务。
作者基于上述内容相关研究工作,假定LLMs可以成为构建可信智能体的关键构件。现有文献已经构建了单独依赖于智能体当下环境状态的一阶提示模板,但可信智能体还需要依赖过去经历。最近的研究试图超越一阶提示,使用静态知识库和信息检索方案或简单的总结方案来增强语言模型的作用。本研究拓展了这些想法,设计了一个处理检索的智能体架构,使过去经历在每个时间步中动态更新,并与智能体当前环境和计划向结合,这些经历可能是相互加强或相互矛盾的。
生成式智能体行为与交互
为了使生成代理的能吃具体化,作者将它们实例化为一个简单的沙盒世界的角色,如《模拟人生》。这个名为Smallville的基于精灵(可交互图形对象)的沙盒游戏世界构建了一个小镇的环境。
智能体头像与交流
作者采用一个简单的精灵头像表示一个智能体。作者撰写了一段自然语言描述来形容每个智能体的身份,包括他们的职业和与其他智能体的关系,将之作为种子记忆。
一个名为John Lin的智能体描述示例:

每个分号限定的短语在模拟开始时作为初始记忆输入。
智能体之间沟通
智能体通过行动与世界互动,通过自然语言与其他智能体互动。
在沙盒引擎的每个时间步,智能体输出一个自然语言的状态陈述智能体的行为,如“Isabella Rodriguez 正在写日记”。然后这一陈述会转化为影响沙盒世界的具体行为,并在沙盒世界上显示为一组表情符号 📖 ✍️。
智能体之间的交流完全通过自然语言完成。智能体能意识到他所处地区的其他智能体,而是否生成智能体架构取决于它们是否路过或发生对话。
用户控制
仿真的运行者可以通过与智能体对话或直接向智能体下指令实现对仿真的操纵或干预。
环境交互
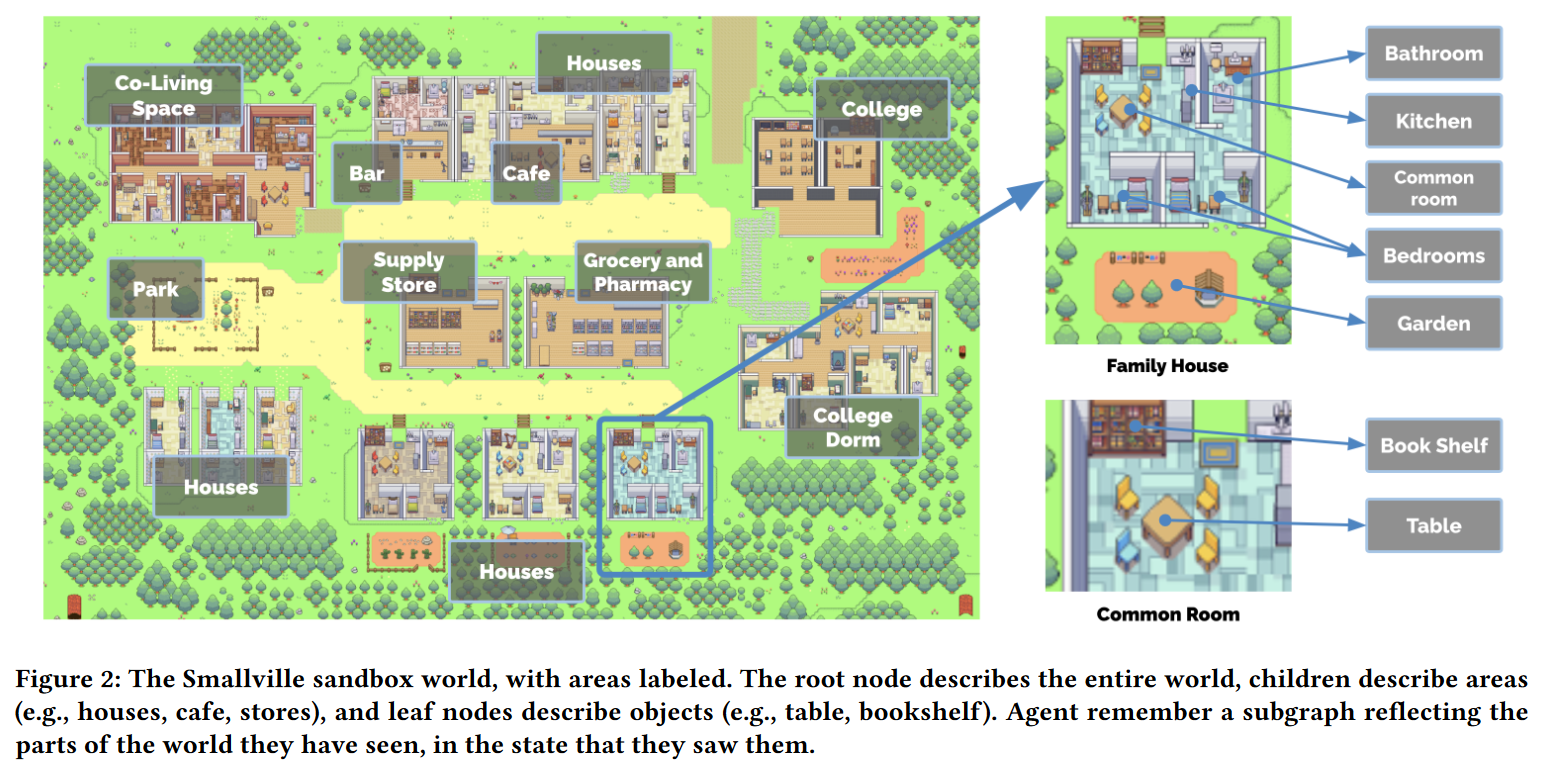
Smallville包含咖啡厅、酒吧、停车场、学校、宿舍、房价和商店,同时作者也定义了子区域和对象。所有的智能体基本生活区包含床、桌子、衣柜、书架、卫生间和厨房。
智能体的移动是由生成式智能体架构和沙盒游戏引擎指引的,当模型决定智能体将移动到某一地点时,沙盒计算Smallville环境中的行走路径,然后代理开始移动。用户也可以参与到环境之中。用户和智能体能够影响环境中的物品状态,如使用物品。
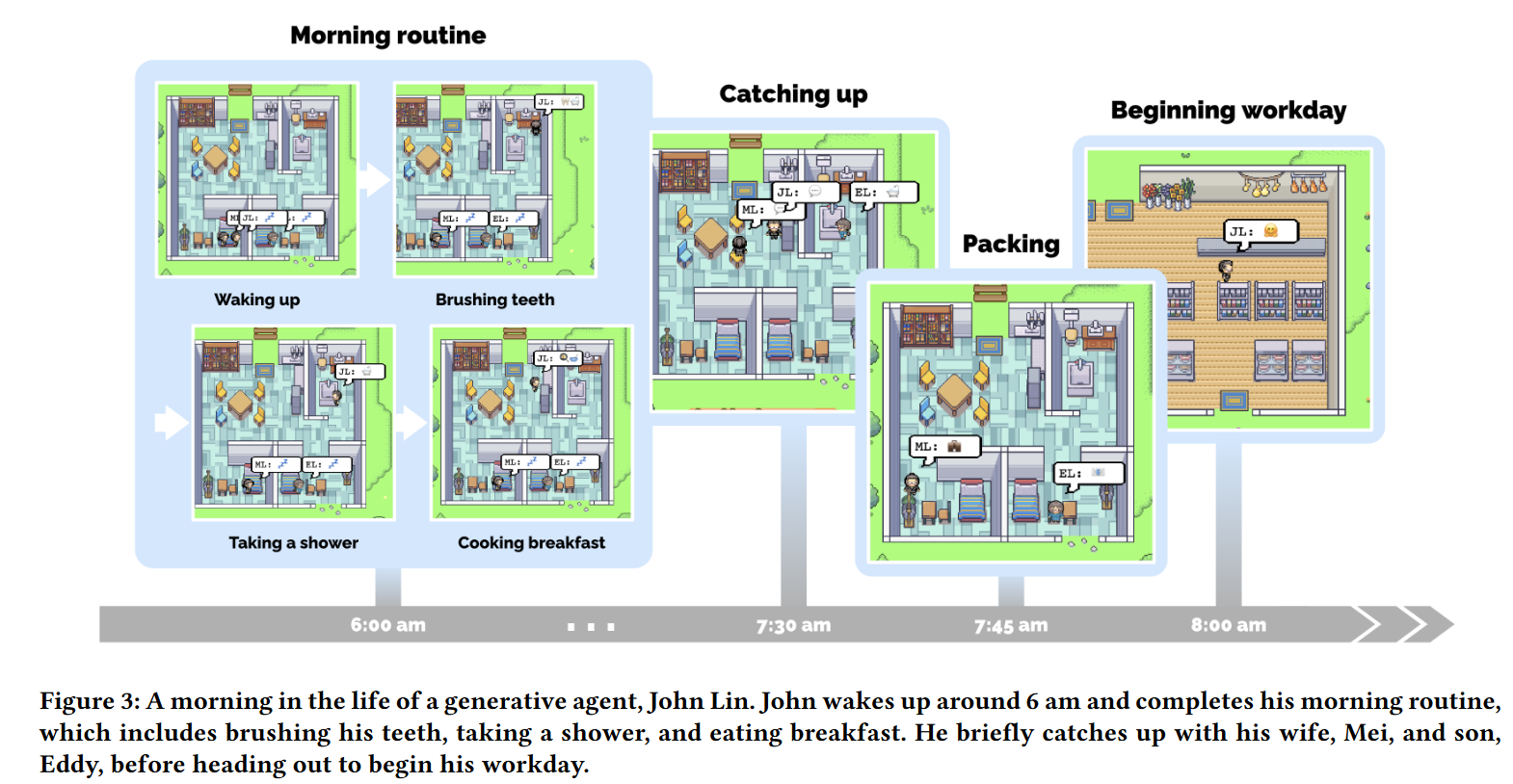
社会行为涌现
- 信息扩散
- 信息可以通过智能体之间的交流得到扩散。
- 关系记忆
- 随着时间推移,Smallville中的智能体会形成新的关系,并记忆它们之间的互动。
- 协作
- 生成式智能体之间存在着协作关系。
生成式智能体架构
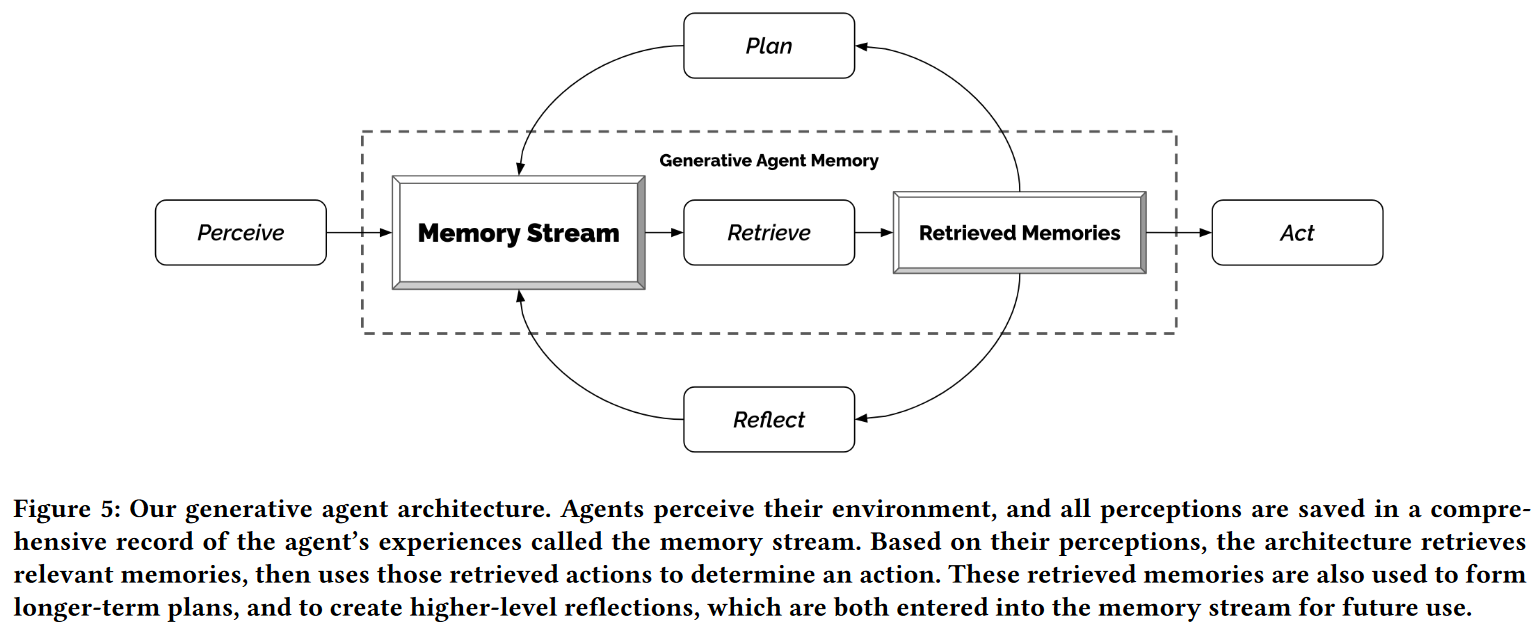
生成式智能体将它们当下的环境和过往经历作为输入,将生成行为作为输出。这一行为有赖于将大语言模型与合成、提取相关记忆的机制相结合的架构,它的核心是一个对智能体经历保留全面记录的数据库的记忆流构件。
本研究使用ChatGPT3.5。
记忆与提取
最大的挑战是创建可信生成式智能体所需要的经历远远超过prompt可以描述的规模,完整的记忆流无法适应ChatGPT有限的上下文窗口。
记忆流保存了智能体经历的完整记录,在这个由记忆对象组成的列表中,每个记忆对象都有一个自然语言描述、创建时间戳和最近提取时间戳。记忆流最基本的元素是观察,它是由一个智能体直接感知的时间。常见的观察包括智能体自身行为、感知到的其他智能体或非智能执行的行为。
本架构创建了一个检索功能,它将智能体当前的情况作为输入,返回记忆流的一个子集,将之传递给大语言模型。作者为近期存取的记忆对象赋予更高的分数,使与近期相关的记忆对象更容易保留在智能体的注意空间内。近期函数为一个沙盒游戏时间指数衰减函数$R(t)=A\cdot e^{-0.99t}$,衰减系数为0.99。重要性区分智能体认为重要的记忆和一般记忆,作者直接令LLM输出一个整数分数,prompt如下:

重要性得分在记忆创建的同时生成。相关性为与当前情境相关的记忆设定更高的得分,由于相关性通常在查询中出现,因此作者使用语言模型为每段记忆的文本描述都创建了Embedding向量,通过计算查询记忆Embedding向量与其他记忆Embedding向量之间的余弦相似度获取相似性得分。最终的检索得分首先将近期性、重要性、相关性得分使用min-max放缩在$[0,1]$,之后加强求和$score=\alpha_{recency}\cdot recency+\alpha_{importance}\cdot importance+\alpha_{relevance}\cdot relevance$,本研究中将所有的权重$\alpha$都设置为1,满足ChatGPT输入框要求的所有高排名记忆都会被包含在prompt之中。

深思
对于只配备原始观察记忆的生成式智能体而言,做出合理的推论或推断是非常困难的。通常,大语言模型只会根据过去记忆直接套用,产生错误的行为。因此,作者引入了被称之为“深思Reflection”的第二类记忆。深思是更高级、更抽象的记忆。由于深思也是一种记忆,它们在进行检索时与其他的记忆一同被评估。深思的生成是周期性的,在本研究中,当智能体最新事件的重要性得分超过特定阈值时才会生成深思。实践中,智能体每天通常深思2~3次。
深思的第一步是通过询问与智能体近期经历相关的查询问题,让智能体确定深思的内容。作者通过智能体记忆流中最新的100条记录询问LLM:“Given only the information above, what are 3 most salient high-level questions we can answer about the subjects in the statements?”,LLM的回答会生成候选问题。之后,作者利用这些生成的候选问题进行检索程序,为每个问题收集相关记忆(包括其他深思)。接着作者要求LLM为这些记忆提出洞见,并引用作为洞见依据的记录:

作者将生成的语句作为深思存储在记忆流之中,包括指向被引用对象的指针。
由于深思不仅可以基于初始记忆创建,也可以基于其他深思创建,因此最终智能体会生成深思树,它的叶结点表示基本观察,非叶结点表示越来越抽象、高级的深思。
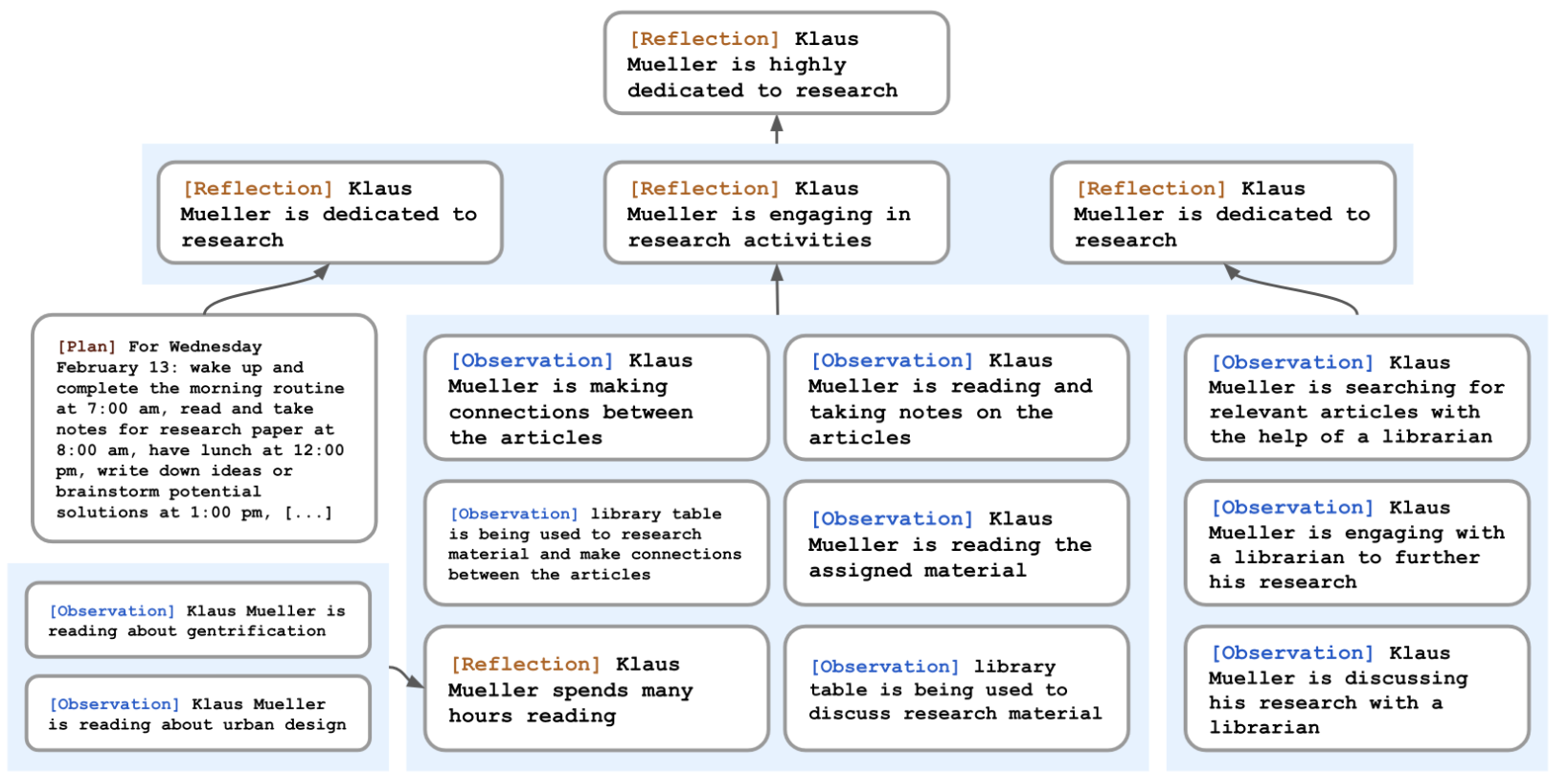
计划与反应
为使用LLM给特定情境信息生成合理行为,智能体形成较长期的计划来确保它们的行动序列是合理、可信的。如果缺少计划,智能体可能会出现在2个小时内吃3次午餐等错误情况。
计划描述了智能体的未来行动序列,并帮助智能体的行为在长期内保持一致。计划包括地点、起始时间和持续时长,例如for 180 minutes from 9am, February 12th, 2023, at Oak Hill College Dorm: Klaus Mueller’s room: desk, read and take notes for research paper。与深思一样,计划也会被存储在记忆流之中,且会被包括在检索程序里。这样就能让智能体同时考虑观察、深思和计划。智能体可能在中期改变它的计划。
为生成可信的计划,作者自上至下地生成计划,通过递归生成更多的细节。
第一步是创建一个大体上概括当天议程的计划。作者通过prompt智能体的描述总结和前一天的总结。


智能体会在记忆流之中存储这一计划,之后对每一块计划进行递归分解来创建更细粒度的行动,直至达到所需的粒度。
反应和更新计划
在每个时间步,生成式智能体会感知周边环境并存储在记忆流之中,架构会prompt LLM这些观察来决定智能体是否继续现有计划或做出反应。

背景摘要的生成通过两个查询“What is [observer]’s relationship with the [observed entity]?”和“[Observed entity] is [action status of the observed entity]”综合而成。
当有反应发生时,架构会重新从当前时间步生成智能体计划。如果反应是两个智能体之间的互动,则创建它们的对话。
对话
框架通过调节智能体关于对方的记忆来生成对话。

结果是:“Hey Eddy, how’s the music composition project for your class coming along?”回答同理。

对话直至双方决定停止对话为止。
沙盒环境实施
Smallville沙盒游戏环境使用Phaser web game 部署框架3构建的。
结构化世界环境与自然语言转换
作者将沙盒环境(区域和对象)表示为树状数据结构,树边表示沙盒中的包含关系,如“炉子”是“厨房”的子节点,之后使用自然语言描述这一数据结构,如“炉子在厨房中”。
每个智能体在浏览环境时独立的构建它们的树状环境表示数据(整体沙盒环境树的子图)。每个智能体有一定的合理初始化环境树,随着它们探索世界,环境树会被更新。智能体并非全知全能的,当它们离开一个区域后,关于这个区域的环境树不会继续更新。
为确保智能体的每个行动都发生在确定的位置,作者将遍历智能体存储的环境树,将之一部分扁平化为自然语言,作为prompt输入LLM。递归将从环境树的根部开始,作者会prompt LLM找到合适的区域。


示例这样就可以得到Lin家的房子,之后使用同样的方式递归所选区域内最合适的子区域,直至到达代理人环境树的一个叶节点。最后,使用传统的游戏路径算法对代理人的运动进行动画处理。
在上述过程中,作者会prompt LLM查询事物对象的状态,并更新环境树。
控制评估
作者利用生成式智能体能够回答自然语言问题的特性,通过“面试”的方式探索智能体过往经历的记忆能力、基于经历规划未来行动的能力、对突发事件的合理反应能力和反思自己的表现来提升未来行动的能力。
为回答这些问题,智能体必须成功地检索并综合信息。作者选取了前人工作中最关键的DV行为的可信度作为本研究的因变量。
“面试”内容具体包括5个问题类别,分别对应5个关键领域:保持自我认知、检索记忆、生成计划、反应和深思。

智能体是在2个游戏日模拟结束之后采样的,这样它们已经积累了一些互动和记忆可以塑造它们的回答。
可信度的评估方面,作者招募了100名人工评估员观看随机选取的智能体在Smallville中的生活回放,并可以访问存储在该智能体记忆流之中的所有信息。具体地,100名参与者需要比较4种不同的智能体架构(含3种禁止智能体访问记忆流中观察、深思、计划的部分或全部记忆的消融实验)和同一智能体在人类作者条件下的采访反应(每个智能体招募1个独立的作者),实验展示了5类问题中每类随机一个问题的5种代理人回答。评估者需要对所有情形的可信度从最可信到最不可信进行排名。
对获取的100组排序数据,作者通过TrueSkill rating(一种竞技游戏评级)将定序数据转换为定距数据。
为分析统计学意义,作者对原始定序数据应用Kruskal-Wallis检验进行非参检验代替单因素ANOVA,然后进行了Dunn事后检验确定各条件之间的成对差异,最后使用Holm-Bonferroni方法对Dunn事后检验中的多重比较的P值进行调整。
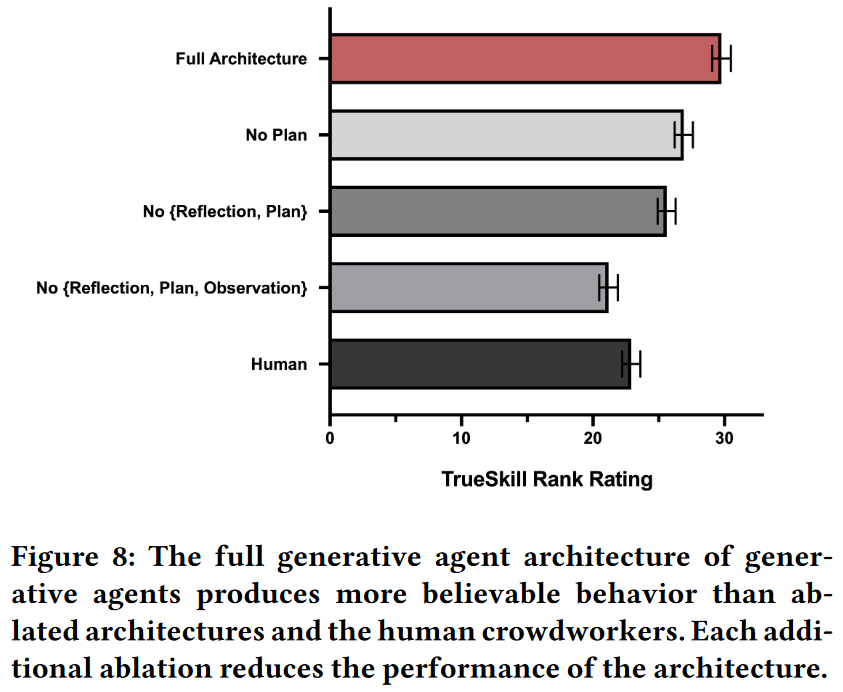
结果表明,在各种控制条件下,全架构生成式智能体生成了最可信的行为,但这并不意味着全架构智能体不存在缺陷。
生成式智能体能够记忆,但会对记忆进行装饰。它们有时候不能从记忆中检索到正确的实例,有时候会装饰它们的知识。通常,智能体不会完全编造自己的知识,但是会对它们没有的经验给出确切的回答,并仍然可以产生幻觉来装饰记忆。
此外,研究表明深思组件是智能体综合信息的必要部分。
端到端评估
作者描述了部署25个智能体在Smallville连续2个游戏日的互动情况。
涌现社会行为
信息扩散
作者测量了在2个游戏日中,2个特定信息的传播:Sam竞选村长和Isabella在Hobbs咖啡馆的情人节排队。在传播开始前,相关信息只有Sam/Isabella掌握。作者在2个游戏日之后面试所有的智能体,是否知悉情人节派对/村长竞选,并通过记忆流检查确定没有出现幻觉。
2个游戏日内,知晓Sam竞选村长的智能体从1个(4%)增长到了8个(32%);知晓Isabella的智能体从1个(4%)增长到了12个(48%),没有幻觉发生或模拟者干预。
关系形成
作者还通过同样的方法检验了人物之间的关系,当且仅当双方对表明认识对方时才会被确认存在关系。作者使用了无向图表示结果,网络密度公式为$\eta=\frac{2\times|E|}{|V|(|V|-1)}$,其中$|E|$为边数,$|V|$为节点数。
在2个游戏日内,网络密度从0.167增长到0.74。在453条智能体对它们与其他智能体关系的答复中,有6条(1.3%)被认定为幻觉。
协调
作者通过Isabella组织的情人节排队分析智能体在群体活动上的协调能力,作者通过知悉排队并在正确时间地点出席来衡量。
在派对的前一天,Isabella花费时间邀请嘉宾,收集物料及争取装饰咖啡厅的帮助,最终在情人节当前12名知悉的智能体中有5位出席了派对。未出席的智能体中,3人因为时间冲突,4名对派对感兴趣但没有出席。
框架的边界和问题
- 综合越来越大的数据集,不仅对检索最相关的信息片段构成挑战,而且随着智能体了解的地点增加,确定行动的适当空间也会构成挑战
- 智能体的行为随时间推移使行动不可信
- 存在由于对恰当行为误分类导致的古怪行为,特别是某些地点的物理规范难以用自然语言传达的时候
- 指令微调似乎在引导智能体更有礼貌和协调,使其在一些场合过分礼貌或配合
可解释性AI如何影响人们的认知4
当直播遇上强化学习5
技术技巧
常用统计检验Python代码
Python统计检验速查表
Python库:Streamlit 机器学习与数据科学Web应用框架
优势:集成度高、高效构建、快速部署
劣势:个性化程度低

Python库:FuzzyWuzzy模糊匹配
依赖Levenshtein Distance算法计算两个序列的差异,基本思想是计算两个字符串由一个转成另一个所需的最少编辑操作次数。
fuzz模块包括简单匹配、非完全匹配、忽略顺序匹配和去重子集匹配四个重要函数。
R包:cowplot图形排版
R包:dlookr自动输出数据诊断报告

-
Park, J. S., O’Brien, J. C., Cai, C. J., Morris, M. R., Liang, P., & Bernstein, M. S. (2023). Generative Agents: Interactive Simulacra of Human Behavior (arXiv:2304.03442). arXiv. http://arxiv.org/abs/2304.03442 ↩
-
Park, J. S., O’Brien, J. C., Cai, C. J., Morris, M. R., Liang, P., & Bernstein, M. S. (2023). Generative Agents: Interactive Simulacra of Human Behavior (arXiv:2304.03442). arXiv. https://doi.org/10.48550/arXiv.2304.03442(作者自己团队的研究) ↩
-
免费开源H5游戏框架 ↩
-
Bauer, K., Von Zahn, M., & Hinz, O. (2023). Expl(AI)ned: The Impact of Explainable Artificial Intelligence on Users’ Information Processing. Information Systems Research, isre.2023.1199. https://doi.org/10.1287/isre.2023.1199 ↩
-
Liu, X. (2022). Dynamic Coupon Targeting Using Batch Deep Reinforcement Learning: An Application to Livestream Shopping. Marketing Science, mksc.2022.1403. https://doi.org/10.1287/mksc.2022.1403 ↩