学术相关
几句对话就能“看清”消费者?他的UTD研究让客服更高效1
第一作者是浙江大学管理学院数据科学与管理工程学系特聘副研究员陈刚,本研究试图解决的问题是在缺少消费者信息的情况下,如何通过语音分析预测线上邀请-线下消费商业模式的消费者到店率。
这项研究局限性是比较大的,首先是研究背景完全基于北京中国汽车销售推广代理服务提供商提供的电话邀约信息,缺乏跨行业、不同来源的数据集进行训练和验证,同时作者设立的一些样本筛选条件如通话时间大于30s等可能会引起严重的样本选择偏差;其次,作者团队的MKT知识不系统,一些概念相互穿插、模糊,文献综述部分比较混乱,作者题目中Theory-Driven里的理论指的是消费者知觉理论中满意度取决于预期与体验的比较,作者引用的1996年JM文献也是指消费者预期与体验如何影响消费者购后满意度的,这与作者研究的邀约后到店率并不是同一概念;最后,作者在利用理论的方式存在问题,例如作者简单的认为在通话中先提及是引起作者到店的重要因素,并通过属性提及的平均顺序构建了统计Embedding矩阵,违背常规,又如作者所谓的预期与体验概念实质上仅仅够构建了这样一对作差的矩阵,在缺乏ground-truth的前提下通过对比学习习得了两个矩阵,它完全可能与预期、体验等概念无关,更无论前面提及的这一理论原本上是用于售后满意度分析的,而非到店率预测。
综上所述,这一研究我认为源于偶然因素的可能大于结构创新的可能。当然,我很喜欢这种将经典理论与新技术手段相结合的思路,只是很多地方需要更多的考虑。

Combining Choice and Response Time Data: A Drift-Diffusion Model of Mobile Advertisements2
作者提供了数据文件,但我没有下载成功,有时间复制一下
决策所消耗的时间对决策行为具有重要影响,正如Block和Marschak (1959)3在随机效用模型的开创性著作中描述的:“延迟的时间越短,不同人为两个候选对象赋予的价值差异越大;而非常长的延迟则容易产生几乎冷漠的状态,即‘冲突情境’:哈姆雷特花了很长时间决定是否杀死他的叔叔。”
就决策为什么要花费时间这一问题,经济学理论文献提出了贯序信息抽样模型(Sequential Information Sampling),它认为在选项的效用是未知的情况下,人们必须通过(付出高昂代价)对噪声效用信号进行采样来习得选项的效用。该模型对决策者积累充足的信息或证据以支持某一特定选项所需的时间进行直接建模,因此选择和相应时间同时作为动态结构方程的一部分,是内生相关的。这一类模型的早期代表是从心理物理学与神经经济学关于短时间尺度决策的研究中发展起来的漂移-扩散模型(drift-diffusion model;DDM)。前人已经在实验室控制实验中验证了DDM及其变体能够在预测任务重较好的估计效用参数,但是在现实世界重要决策行为中还未得以测试。
DDM范式
假定一个双向选择情境,两个选项的效用(y=1/0)差异决定了更优的代理人选择。在贯序抽样模型中,我们假定代理人只有随着时间逐步学习选项的未知效用水平。
正式地,感知效用差异(y=1/0)被建模成基于随机微分方程$dZ(t)=(\mu+\gamma Z(t))dt+\sigma dW(t)$演化的高斯过程$Z(t)$。Fudenberg等(2018)将这一随机过程解释为偏好某一选项的随机证据积累过程,代理人无法观测到表示实际选项效用差的漂移项$\mu$,它们只能观测到噪声信号过程$Z(t)$,其中噪声服从标准差为$\sigma$的Wiener过程(布朗运动)$W_t$。在实践中,$\frac{u}{\sigma}$捕获了效用信号的相对信息量。
在扩散过程中参数$\gamma$(泄露参数)捕获了扩散过程的序列依赖,当$\gamma\neq 0$时,$t$时间步之前的信息积累会影响代理人在$t$时刻的信息感知,产生时间的延续效应。当$\gamma=0$时,随机过程为一个带有漂移项的连续时间随机游走,其中每个样本都是独立等权重的,同时,$\gamma=0$意味着不同选择结果的响应时间部分是相同的,这与理论假设相悖。
该模型的决策规则为对称的首次通过规则,给定阈值$B>0$,当首次发生$Z(t)>B$则选择$y=1$,当首次发生$Z(t)<-B$则选择$y=0$,响应时间即为首次通过$B$或$-B$所消耗的时间步。本文与其他多数DDM应用一致采用外生的阈值$B$。
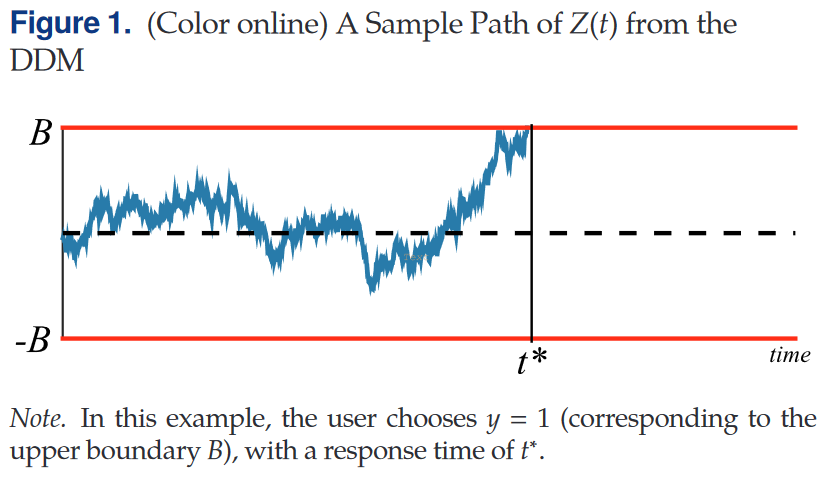
应用:移动平台视频广告
当下的一种主流Apps盈利模式是“免费”模式(”freemium” model),即用户免费下载App,但App会定期向用户推送广告进行盈利,这导致移动广告成为数字广告领域最大的细分市场。
本文中,作者将Apps开发者称为发布者,将广告创作者称为广告商。在多数案例中,广告发布者与广告商均为Apps。一种常见的移动广告形式为30s左右可跳过视频广告,在广告视频播放期间和播放完毕后,用户可以选择关闭(click back $y=0$)或下载广告App(click-through $y=1$)。
本研究的数据集源自一个充当广告商和发布商中介的双边移动广告平台络,并限制广告商为一款益智游戏,获取其自2016年十月一日至十二月十五日共计$n=232663$广告服务。数据集中有3.17%的样本选择了click-through,符合平台普遍的1.5%~3% CTR特征(click-through rate)。
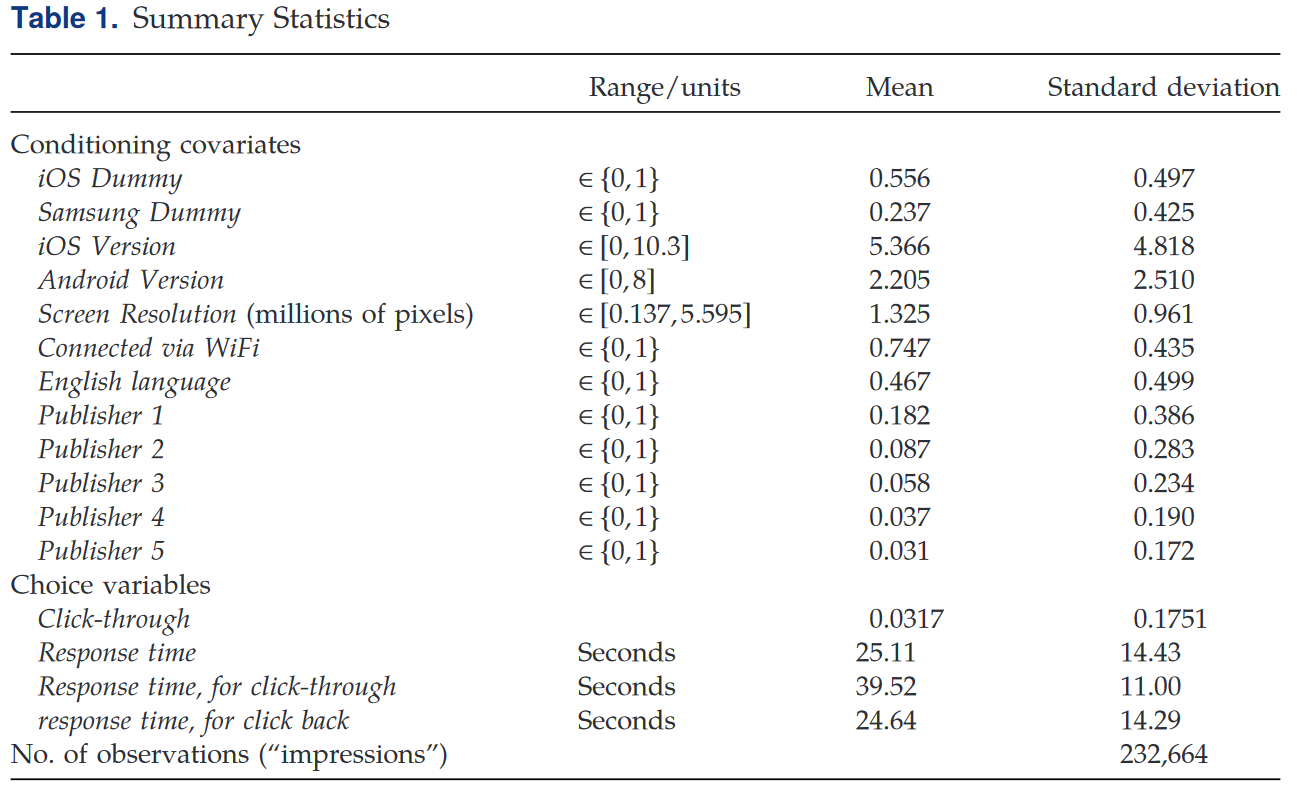
用户内生的响应时间直方图表明53.6%的样本选择在广告视频播放结束后(30s)进行决策选择。响应时间与选项具有明显的系统相关性,click-back分布呈现双峰特征,一峰出现在广告播放期间,另一峰则在广告播放后,整体上平均click-back时间为24.6s,中位数为31.6s。Click-though分布同样是双峰的,主峰分布在广告播放完毕后,在广告播放期间有一个很小的峰,整体决策时间均值为39.5s,中位数为38.5s。在后一阶段click-though倾向于比click-back更晚决策。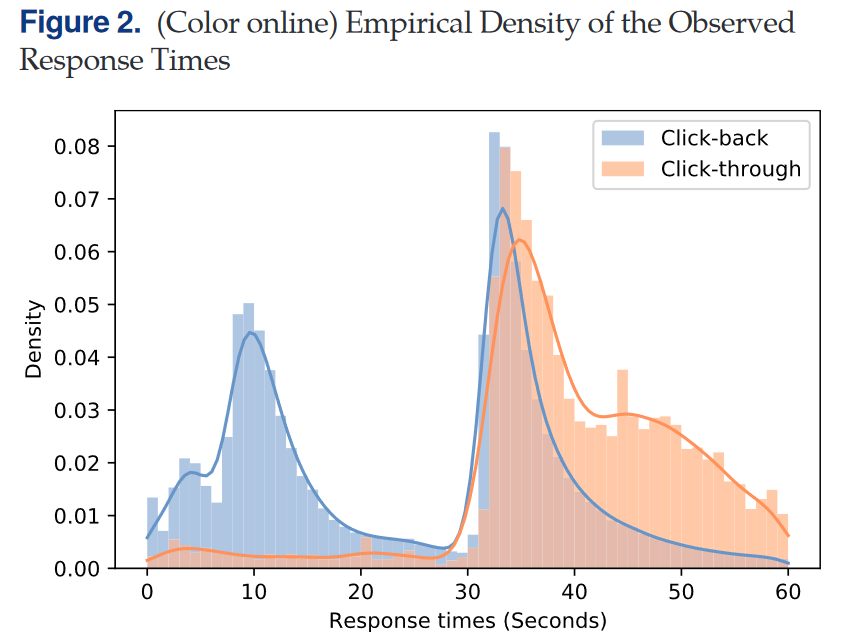
作者同样展示了Click-though的风险概率(用户在时间$t$时刻仍未决策前提下的Click-though条件概率),整体上决策越晚Click-though概率越高,且在30s处概率具有明显跃迁。这一特征也为作者采用两阶段DDM模型提供了依据。
作者研究的一项关键假设是用户知道广告是可跳过的,作者研究的广告展示了一个“跳过广告”按钮和一个倒计时计时器。
移动广告两阶段DDM模型
为了将DDM框架与移动广告数据特征相适应,作者提出了DDM的两阶段拓展。
第一阶段是广告播放阶段(ad-play stage),广告播放完毕后为第二阶段后阶段(postad stage),用户在两个阶段均可以做出决策。尽管作者都使用扩散模型为两个阶段进行建模,但作者运行两个阶段的参数不相同以反应两阶段在类型和信息来源上的差异。 作者认为,在ad-play阶段主要信息来源就是视频广告本身;在postad阶段用户可能会将广告中传递的信息与他们之前在原应用中的游戏体验进行比较。
正式地,在ad-play阶段,信息积累过程描述为$dZ_1(t)=(\mu_1+\gamma_1Z_1(t))dt+\sigma dW(t)\ \ \ for\ 0\leq t\leq 30$这一阶段的漂移项为$\mu_1$,它被解释为视频广告传递的广告应用与原应用之间效应差异的测量。若过程达到了上下限阈值,用户就会Click-though/Click-back。
在视频播放完毕后,postad阶段开始,产生一个不同的信息积累过程$dZ_2(t)=\mu_2dt+\gamma_2Z_2(t)dt+\sigma dW(t),\ \ \ for\ t>30$。两阶段虽然参数不同,但样本路径在$t=30s$处是连续的。
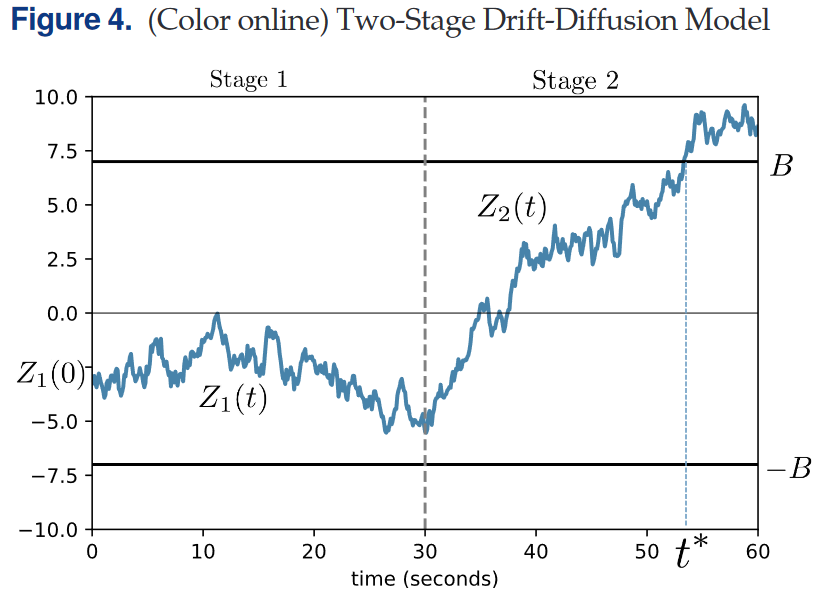
最后,作者允许扩散过程初始值$t=0$时刻非零,并且在不同用户之间变化,作者假设初始值服从高斯分布$Z_1(0)\sim \mathcal{N}(\mu_0,\sigma_0^2)$,它可以直观解释为各个用户对效用差异$\mu$的先验信念。基于Fudenberg et al. (2018),$\mu_1$解释为视频广告传递的广告app的效用信号均值;$\mu_2$表示用户对比广告app与原app产生的后回忆效用均值。由于这些参数是相对应$\sigma=1$设定的,因此一个等效解释是$\mu_1$和$\mu_2$捕获了两阶段中效应信号的相对信息量。
以第一阶段为例,扩散过程的数学特性意味着在任意$t$时刻$Z_1(t)\sim\mathcal{N}(\frac{\mu_1}{\gamma_1}(e^{\gamma_1t}-1),\frac{\sigma^2}{2\gamma_1}(e^{2\gamma_1t}-1))\ \ \ for\ 0\leq t\leq 30$为高斯随机变量。在这一等式中,泄露参数$\gamma_1$的符号决定了抽样路径$Z_1$在$t\to\infty$收敛($\gamma_1<0$)还是发散($\gamma_1>0$)。
参数识别
- 引理1
在没有泄露参数的单阶段简单DDM模型$dZ(t)=\mu dt+\sigma dW(t)$中,漂移项$\mu$和阈限$B$通过两个数据的矩进行识别:平均响应时间$\bar{t}=\mathbb{E}[t^\ast]$、Click-though概率$\bar{y}=\mathbb{E}[y]$,扩散的方差$\sigma^2$通过对样本归一化获取$\sigma=\bar{\sigma}$。
$\hat{\mu}=\left\{\begin{align}&-\sqrt{\frac{\bar{\sigma}^2(2\bar{y}-1)log(\frac{\bar{y}}{1-\bar{y}})}{2\bar{t}}} \ \ if\ \bar{y}<0.5\\ &\sqrt{\frac{\bar{\sigma}^2(2\bar{y}-1)log(\frac{\bar{y}}{1-\bar{y}})}{2\bar{t}}} \ \ if\ \bar{y}\geq0.5 \end{align}\right .$
$\hat{B}=\frac{\bar{\sigma}}{2}\sqrt{\frac{2\bar{t}log(\frac{\bar{y}}{1-\bar{y}})}{2\bar{y}-1}}$
双项选择的潜在效用差异估计量$\hat{\mu}$与平均响应时间$\bar{t}$负相关,它的逻辑是越早做出决策意味着个体的偏好越强烈。前人研究指出当Click-though概率显著偏离0.5时(本研究$\bar{y}\approx0.03$),估计效应水平对响应时间更为敏感。
结果表明除非代理人进行瞬间决策($<0.25s$),否则DDM的估计效应与logit估计有显著差异。
- 定理1
令$\hat{\mu}_{Logit}$为无协变量的二元logit截距,$\hat{\mu}_{DDM}$为无协变量的简单DDM漂移项。若平均响应时间$\bar{t}>0.25$,$|\hat{\mu}_{Logit}|>|\hat{\mu}_{DDM}|$
统计结果表明第一阶段Click-back更频繁,因此第一阶段漂移参数应该更负向。
泄露参数$\gamma$影响积累过程的方差,因此响应时间分布的高阶矩提供了这一参数的信息。
估计结果
作者采用非线性最小二乘法进行参数拟合。
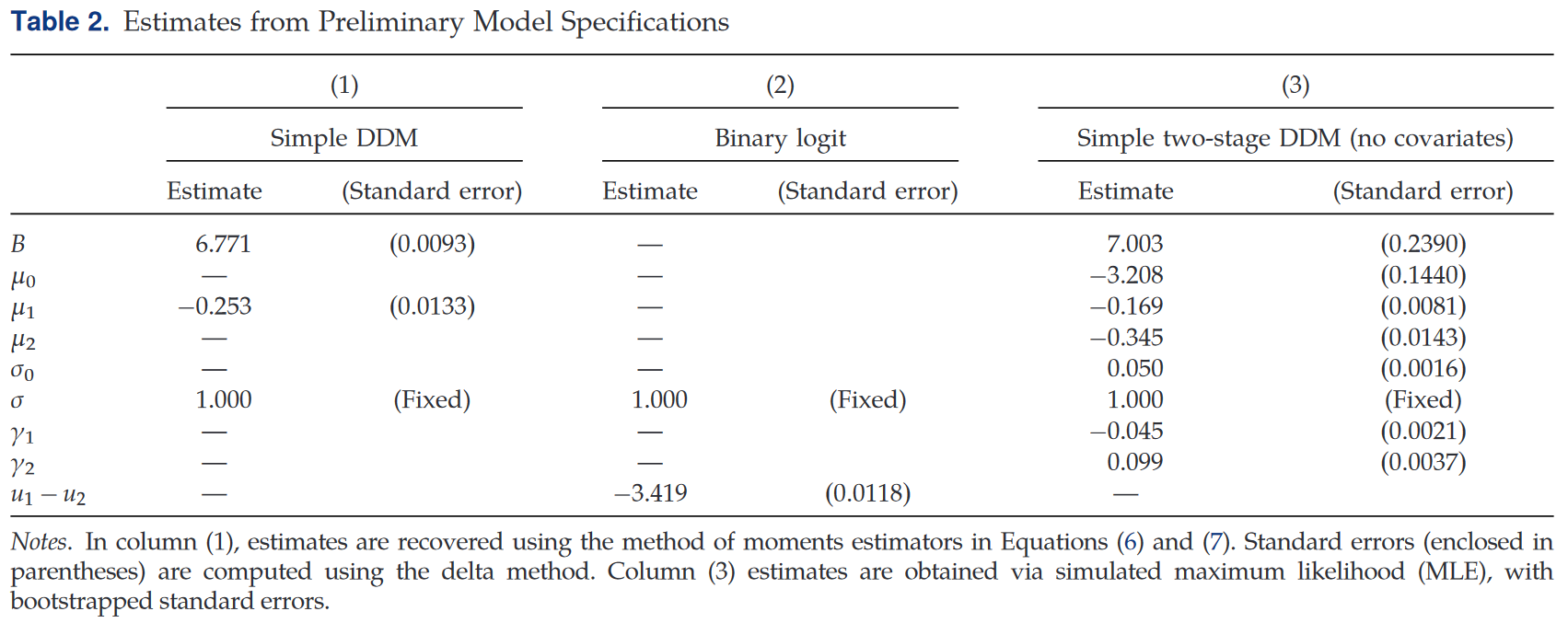
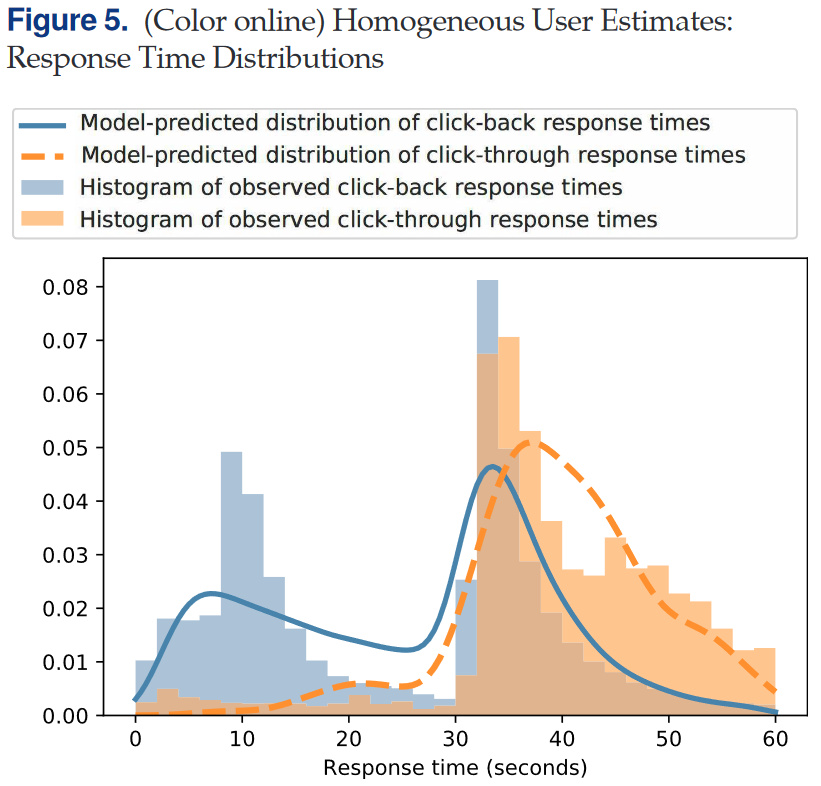
作者首先从简单初步模型开始,Simple DDM和Binary Logit在效用差异($\mu_1$与$u_1-u_2$)具有显著区别($-3.419\gg-0.253$)。第三列展示了不包含用户相关协变量的精简两阶段DDM,预测的CTR为3.10%,接近数据集平均CTR 3.17%。该模型对Click-back响应时间双峰分布和Click-though响应时间的多峰分布有较好的拟合,同时也捕获到了Click-though倾向于比Click-back更晚决策的现象。
- 全模型结果
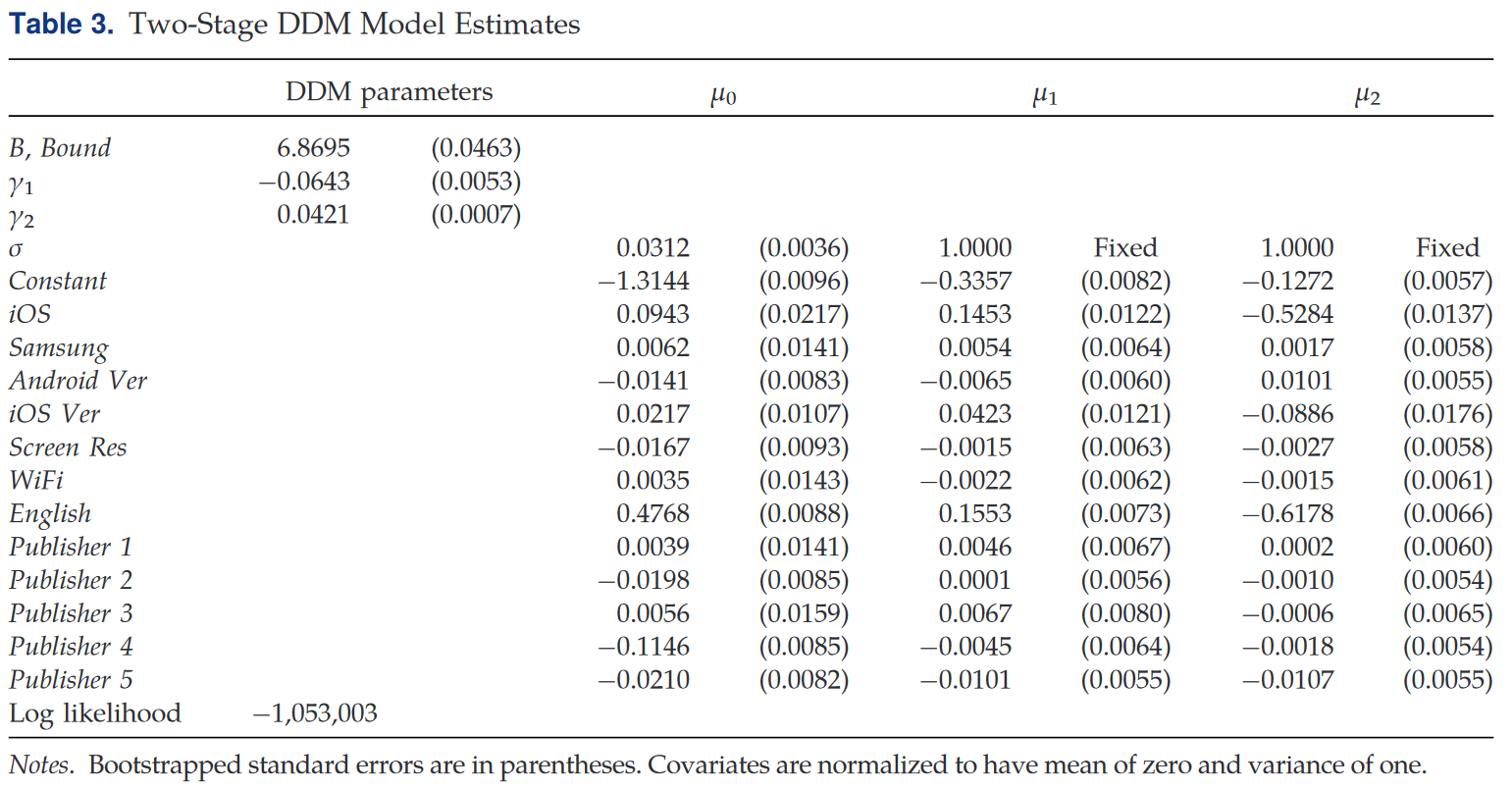
$\mu_1、\mu_2$为模型漂移项,$\mu_0$为扩散过程初始位置的均值,它们被参数化为观测协变量的线性指数。$\mu_0$大致介于0和下限$-B$之间,两阶段的泄露参数$\gamma_1(-0.0643)$和$\gamma_2(0.0421)$符号相反。
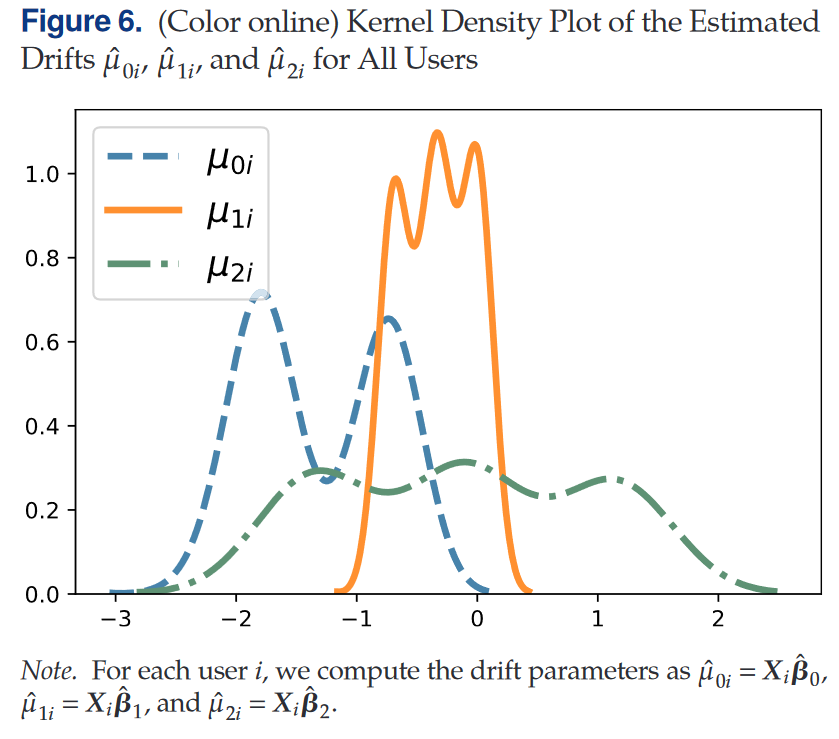
参数的核密度估计表明在ad-play阶段$(\mu_1)$用户的异质性低于决策阶段$(\mu_2)$,即用户在视频播放期间主要将注意力聚焦于视频,在视频播放后注意力更发散。
对于多数用户而言$\mu_0<\mu_1$,且二者正相关(相关系数0.647),而$\mu_1$与$\mu_2$的关系是复杂的。
反事实分析:操纵广告关注度能否增加点击量?
就这一问题,前人文献的传统做法通常是进行实验室实验,但作者选择通过设置能否跳过广告(及强制观看时间)来操纵广告关注度构建反事实场景。
具体地,作者设定用户被要求只有在看完$x$秒$(0\sim15s)$广告视频后才能Click-back,即在前$x$秒内移除漂移-扩散模型下限,确保扩散过程持续来实现反事实状态。作者没有分析15s以上的强制广告,因为它可能导致严重的广告骚扰、用户注意力离开等未被模型考虑的情况。
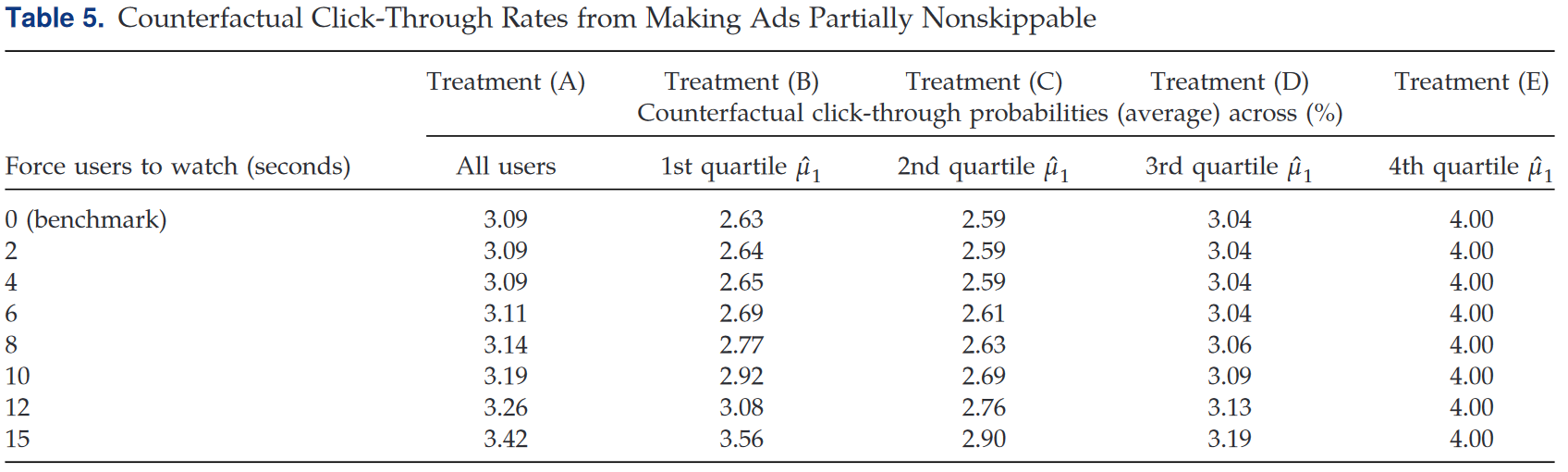
模拟的结果显示,所有用户在平均水平上延长强制观看时长确实有助于提高CTR(A列结果),但提升很小。同时,整体平均水平掩盖了很多用户异质性信息。按照$\mu_1$分组表明,强迫用户观看广告最初几秒所获“边际”CTR主要来自$\mu_1$最低的两个四分位。该结果与Krajbich(2019)实验室研究结果一致,强制观看广告在最有效的受试群体中选择效应约$1\% \sim 2\%$,其余样本中选择效应为0。
但$\mu_1$较低的用户通常认为广告APP效用水平较低,他们与最有效的受试群体一致吗?
此外,最低两个四分位$\mu_1$用户对应的广告出价、APP内购买频率较低,缺乏广告价值。以2014年YouTube $CPM=\$7.50$为例,模拟表明整体而言,广告不可跳转(10s)带来的总收入增长相当于CPM增长$\$0.13$。
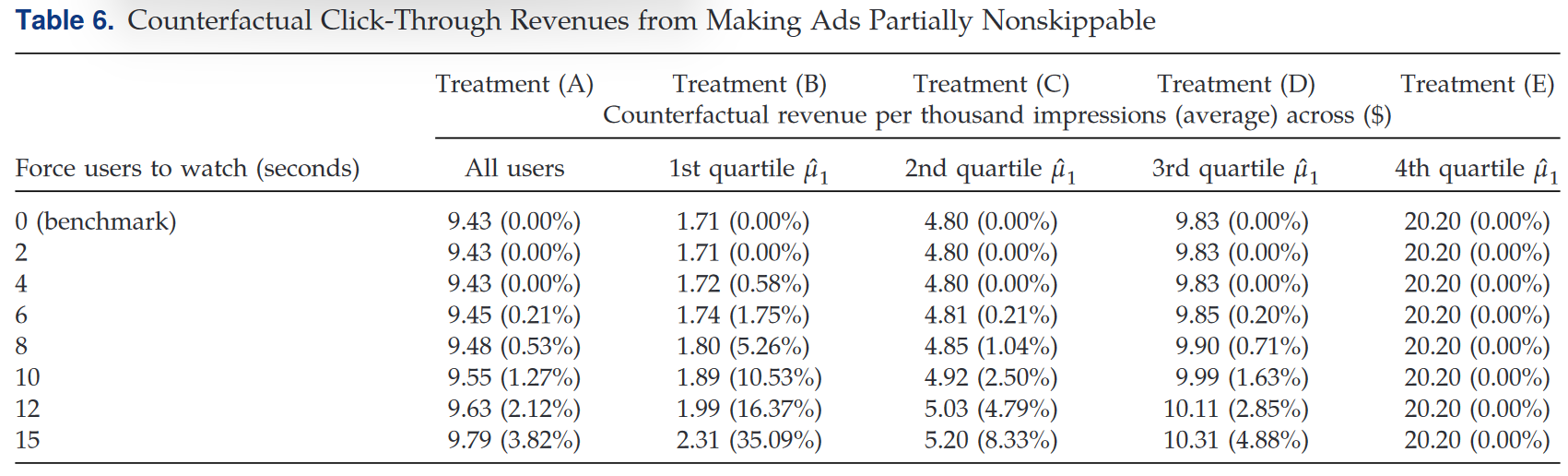
因此,强制观看广告可能不能有效提升广告APP收益,同时还可能损害消费者体验。
亚当 · 斯密300年丨斯密如何成为美国资本主义的象征?(研讨纪要)
主讲人Glory M. Liu是哈佛大学社会研究所的讲师,这篇纪要是关于她的新书《Adam Smith’s America》,但Liu开篇就说这实际上是American Adam Smith,这是关于美国人如何重新解读亚当·斯密的故事。
传统的亚当·斯密学术研究通常强调人们对亚当·斯密的错误认知,及希望重新解读亚当·斯密给那些将之简化为自由市场标签的人。但Liu却打破了这一惯例, 她重点关注亚当·斯密的思想是如何被接受、阅读和重新理解的,这是关于Reception History的一本书。
在研究这一问题上,Liu借用了Stefan Collini的“四阶段理论”,解释思想家如何迈入经典地位的。第一阶段为Living Resource,作者作为活得资源,他的思想、经历等会在作者活着的时候不断的被辩论;第二阶段为Discipleship(门徒),人们开始引用作者的思想,并声称自己为作者的追随者或反对者。第三阶段为Authority,Collini认为大多数作者只会经历前两个阶段,第三阶段象征着作者的思想极大的突破了现有思想,作者开始具有图腾式的象征意义。最后,作者被封圣Canonization,即使他的作品与当下并无联系,其作品依然会被视作经典或纯粹的学术研究对象。
- Smith as Living Resource
在Smith在世的时候,一批美国政治家和思想家认为他的作品能否启迪人们,《道德情操论》和《国富论》均被广泛阅读。1771年,托马斯·杰斐逊推荐了《道德情操论》,1786年,约翰·亚当斯大量引用《道德情操论》。1780年代,College of William首次将之作为政治经济学教材。最重要的是,Alexander Hamilton直接引用了《国富论》的思想构建国家银行、公共信贷和制造业的论文中,发展了新国家经济学。这些图景反映了在奠基时代,人们阅读亚当·斯密的想法,并独立地将其纳入自己的想法。《道德情操论》被视作公民在道德上的启蒙;《国富论》被政治家视作管理国家经济的资源。但在这一阶段,没有人将亚当·斯密视作经济学之父。
- Smith Discipleship
直到在19世纪中叶,那些使用或评论Smith思想的人可以被视作是亚当·斯密的信徒或反对者。随着政治经济学发展,《国富论》逐渐被公认是政治经济学的著作,人们不再仅仅比较学科新作是否认可Smith思想,同时也会比较风格、要素和结构。1823年,《North American Review》写道Adam Smith的工作开创了政治经济学科学。Smith的美国诠释者开始重新思考Smith时代与自己时代的差异,寻求经过时间检验的思想,其中自由市场等理念就是在这一过程被提取的。自此,美国读者开始建立起评估Smith思想遗产的模式,Smith思想开始成为一种标准。1838年,《国富论》成为最为畅销的教材。当然,这期间也产生了大量的批评。这些批评不仅仅是源自写作风格的,也有政治情境、学科相关的批评。在美国内战前期,自由贸易、关税问题成为最为重要的政治议题。随着辩论的激化,反对派认为Smith思想的时代与当时不一致,或借助他国历史经验试图证明Smith思想是错误的,而Smith思想支持者则不断地为期辩护,这些辩论使Smith思想不断被推向前,逐渐地形成这一领域的权威。
- Intellectual Authority
根据Collini的观点,当一位作者在广泛的文化术语中成为象征或传统的一部分时,他就成为了一种权威。在19世纪末的关税辩论中可以很好地体现这一点,当时的美国工业环境已经与18世纪完全不同了,Smith思想更多地被视作是一种符号,而不再完全聚焦于思想本身。辩论的双方都会试图通过Smith理论表明自己的党派立场,例如1893年大萧条时期,美国议会宣布自由贸易作为经济科学法案失败是因为Adam Smith认为减少制造业会损害国内市场规模。
关于Smith作为权威最著名的例子是弗里德曼为代表的芝加哥学派经常在他们的写作中引用Smith思想。他们认为Smith是芝加哥学派价格理论的先驱者,Smith关于自我利益的阐述为人类自由行为提供了一个近乎无限强大的定理,看不见的手通过价格与价格机制为上百万个体行为提供了解释。弗里德曼的说法确立了《国富论》作为科学经济学的开端,这一解释将Smith置于经济学整体传统的奠基人地位,令弗里德曼等芝加哥学派经济学家成为Smith遗产的“合法继承人”,并为自由市场提供了科学骨架。20世纪,Smith的理性人与看不见的手思想成为了市场本身的代名词。
- Canonization
在芝加哥学派等人的推动下,Smith的地位被提升到半国父水平。
之后,在上世纪以来的重新解读中,Smith思想进入到我们今天熟悉的地位。它既不是芝加哥学派经济学家,也不是资本和政府不干预的盲目吹捧者。许多学者致力于从Smith滥用中回复Smith本意,造就了今天的Smith学派。
关于Smith学说美国接受史的研究,Liu认为可以带来几项启发。
- 重新思考作为学科的政治经济学
政治经济学思想,特别是Smith思想通常被认为是跨时代的,但我们应该意识到经济学实际上是一种并非价值中立的推理风格,是一种话语权威。声称借用Smith重要思想的人可能只是Smith东拉西扯选择的东西。例如,19世纪战前贸易辩论,南方自由贸易的拥护者坚持Smith是这一科学的创始人,这就通过政治经济学中普遍话语——自由贸易规避了奴隶制这一极端词汇。芝加哥学派将理性人与无形的手滥用至市场之外也是类似例子。
- 理解Adam Smith思想的复杂性
作者希望我们回到19世纪,理解Smith的复杂性。长期以来,人们通过将Smith思想过度简化为自由市场,但这并不正确。例如19世纪Richard T Ely和Era Seligman就试图颠覆新古典主义的解释方法,重塑Smith形象。他们聚焦于Smith价值的劳动理论,声称Smith将劳动力置于中枢地位,维护劳工权益对抗资本,并非资本主义之父。20世纪的新保守主义思想家如Irving Kristol、Gertrude himmelfreb通过Smith的道德情操理论,试图证明资本主义的灵魂并非冰冷的计算,也包含道德进步。如今,很多人认同Smith是一位人道主义思想家。
- Smith本身的特别之处
Smith的言论特别小心,有时我们认为Smith为一个问题提供了一个答案时,却发现他其实提供了多个答案,有人可能会认为他是自相矛盾的,但其实他只是解释不通层次的情况。此外,Smith有时他确实是矛盾的,如《国富论》中对商人好坏的评价,因此在阅读Smith时必须特别小心。
业界动态
当克隆宠物成了一门生意
为了“公猫”的“复活”,刘兴花费了13.8万元,这还是宠物克隆公司给出的优惠价。
目前《试验动物使用许可证》是国内唯一能够对克隆宠物行业进行监管的依据,它涵盖了动物福利、伦理审查、生物安全等方面的内容,但这个由科技部门颁发的许可证,实际上只是认可了科技企业和科研单位开展动物实验的资质,并不限定实验用途。
“其实,就是要避免以克隆宠物之名来克隆人。”浙江大学国际联合商学院数字经济与金融创新研究中心联席主任、研究员盘和林建议,通过“报备制”加强风险管控,否则,“法无禁止即可为”。
“从全球范围看,克隆人是被禁止的,这也是学术界和产业界的高度共识,是不可逾越的红线。”米继东说,克隆宠物是一个新兴的领域,希望国家层面能出台相关的规范,确保企业的科技创新始终沿着正确的方向前进
克隆技术为濒危野生动物的保护提供了一个很好的切入点,这对生物多样性的保护具有很大贡献。
市场规模(Market Size)估算
【参考】
在计算市场规模时,通常考虑四种市场指标
- Potential Market Opportunity 潜在市场机会
- Total Addressable Market 总潜在市场TAM
- 当企业获取100%市场份额时能够达到的最大潜在价值
- Segment Addressable Market 细分潜在市场SAM
- 企业可以服务到的市场范围
- Expected Share of Addressable Market 期望市场份额 丨 Serviceable Obtainable Market SOM
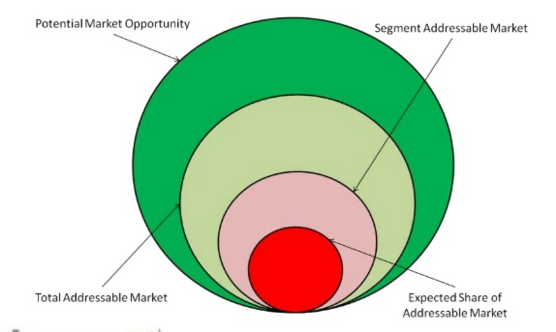
通常我们需要估算的是Total Addressable Market,然后根据实际情况计划选择细分市场与期望市场份额。
- Top-Down Approach自上而下法
从可获得的公开数据和报告中更广泛的市场范围数据(如行业信息),之后逐步缩小至总潜在市场
- Bottom- Approach
对细分市场数据进行加总整合
- 需求侧估计
- 供给侧估计
一般还会用到市场渗透率、标杆法等。
最好通过多个模型和方法分析市场,之后对所有结果进行比较分析,记住,要Always Challenge Your Results。
技术技巧
Python库:70个精美图快速上手seaborn!
-
Chen, G., Xiao, S., Zhang, C., & Zhao, H. (2023). A Theory-Driven Deep Learning Method for Voice Chat–Based Customer Response Prediction. Information Systems Research, isre.2022.1196. https://doi.org/10.1287/isre.2022.1196 ↩
-
Xiang Chiong, K., Shum, M., Webb, R., & Chen, R. (2023). Combining Choice and Response Time Data: A Drift-Diffusion Model of Mobile Advertisements. Management Science, mnsc.2023.4738. https://doi.org/10.1287/mnsc.2023.4738 ↩
-
Block H, Marschak J (1959) Random orderings and stochastic theories of responses. Cowles Foundation Discussion Papers, 289. https://elischolar.library.yale.edu/cowles-discussion-paper-series/ 289. ↩