学术相关
拒绝比选择更具传染性:他人的决策如何影响我们的行为?1
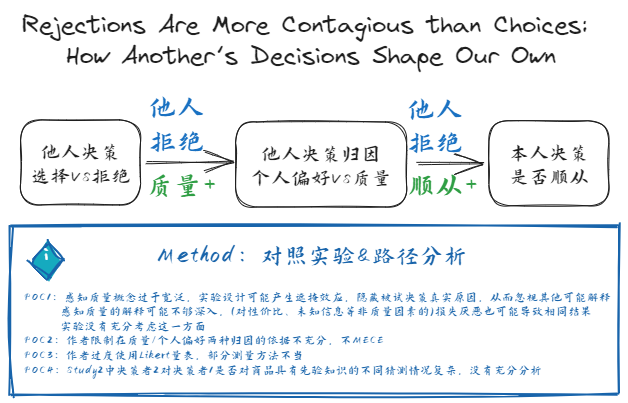
| 主题 | Title | Author | Journal | ROF | SPL | CPL | GAP |
|---|---|---|---|---|---|---|---|
| 决策 | Rejections Are More Contagious than Choices: How Another’s Decisions Shape Our Own | Nan, L. X., Park, S. K., & Yang, Y.【2023】 | JCR | 在选择情境下,若消费者认为他人的决定是拒绝某项某项而非选择,他们更有可能顺从他人的决定,且更可能将他人的决定归因于产品质量,而非个人偏好;质量与个人偏好的推断在框架效应(拒绝与选择)对一致性的影响中起中介作用 | 在各种情况下,选择和拒绝涉及不同的决策过程,并导致明显不同的结果 | 没有研究我们将他人的决策视为选择或拒绝会如何影响我们的行为;以往有关社会影响的研究总是在不同的背景下研究选择和拒绝 | 将他人决策视为选择或拒绝如何影响被试决策 |
| RFW | POC-RPP | IV | DV | Method |
|---|---|---|---|---|
| 考虑同时包含选择/拒绝观点的情况;将他人决策替换为他人推荐是否会导致不同结果;对产品的先验知识、社会规范是否及如何影响这一决策过程 | 感知质量概念过于宽泛,对存在差异的产品选择中可能遮掩其他原因;作者直接限制在质量/个人偏好依据不充分;由于遮掩效应存在,感知质量的解释可能不够深入,如(对性价比、未知信息等非质量因素的)损失厌恶也可能导致相同结果;Study 2第二决策者对第一决策者是否对商品具有先验知识的不同猜测可能意味着不同的影响因素,没有充分分析;作者过度使用Likert量表,部分测量方法不当;能否拓展至多个参照他人决策的情景;能否增加分析消费者放弃购买的情景 | 他人决策被认为是选择/拒绝某选项 | 是否顺从他人决策 | 对照实验;路径分析 |
新冠疫情冲击下城市人群出行特征变化及韧性分析——以北京市为例2
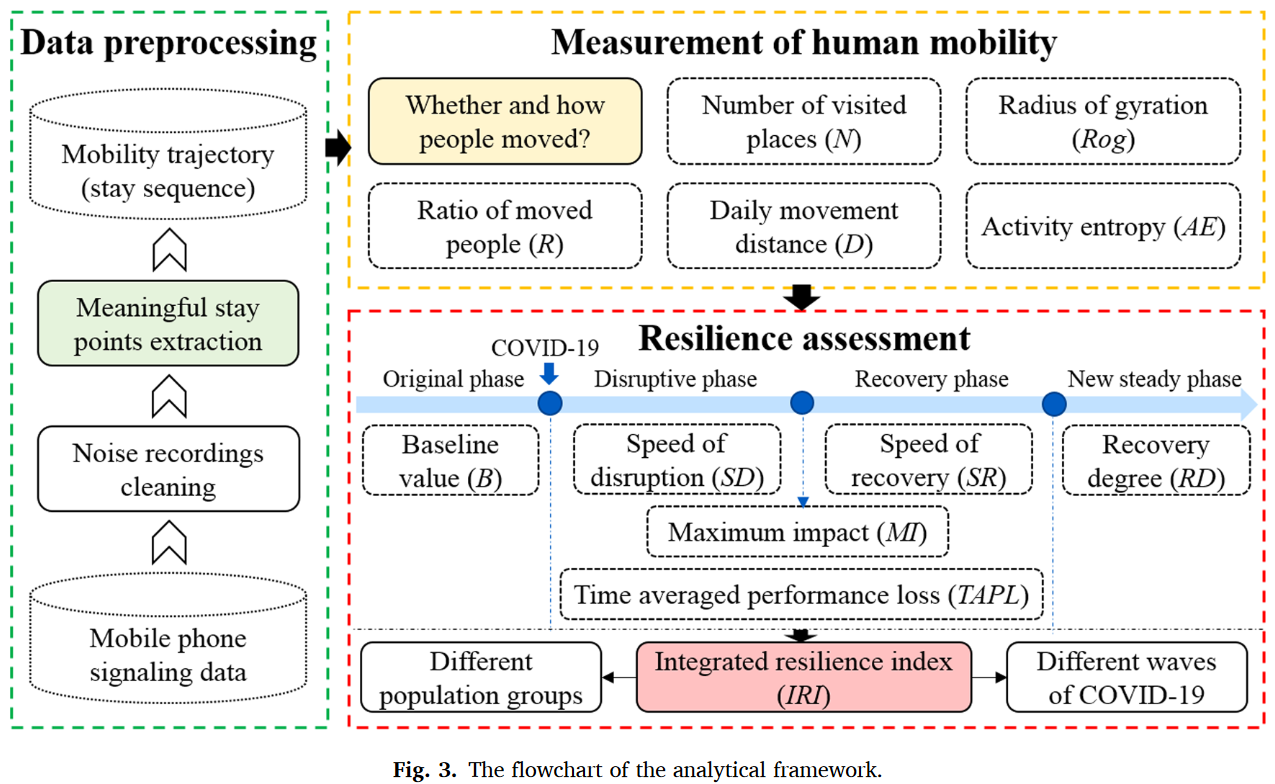
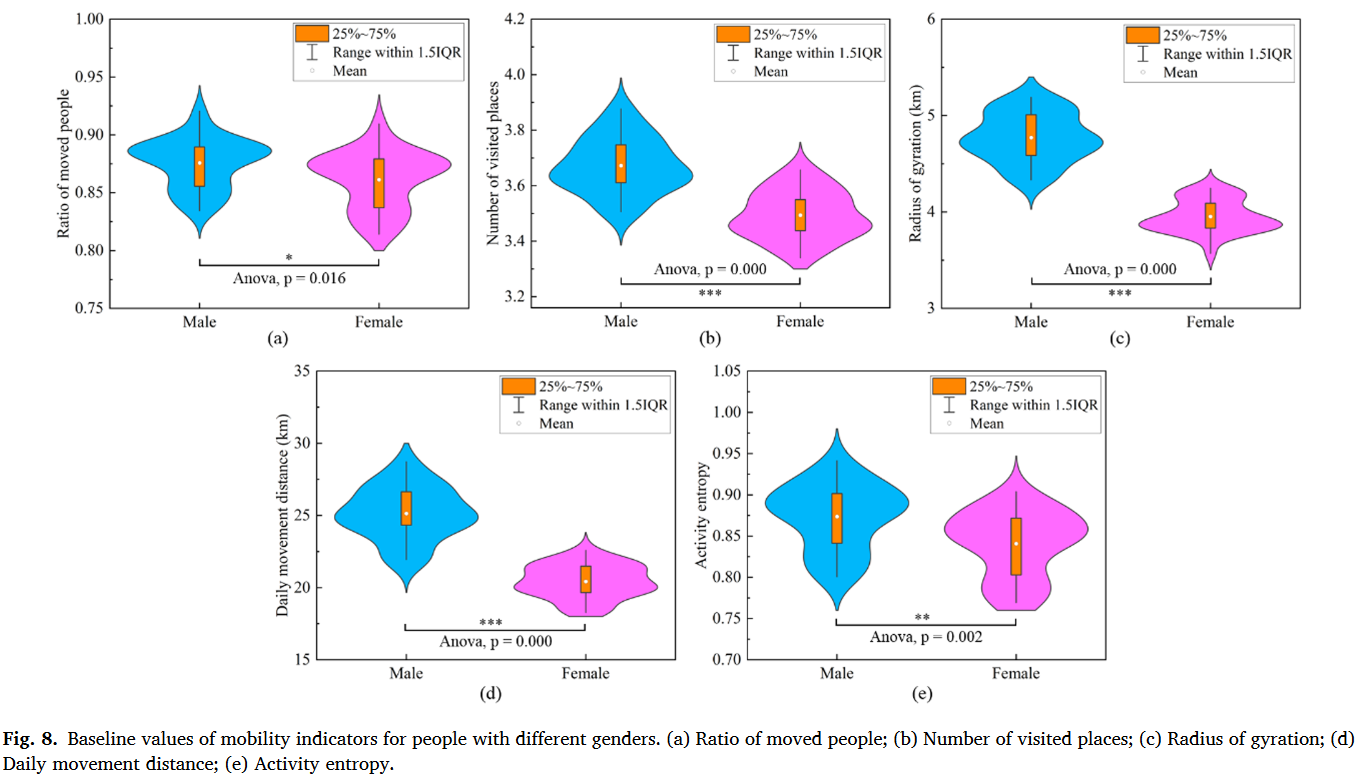
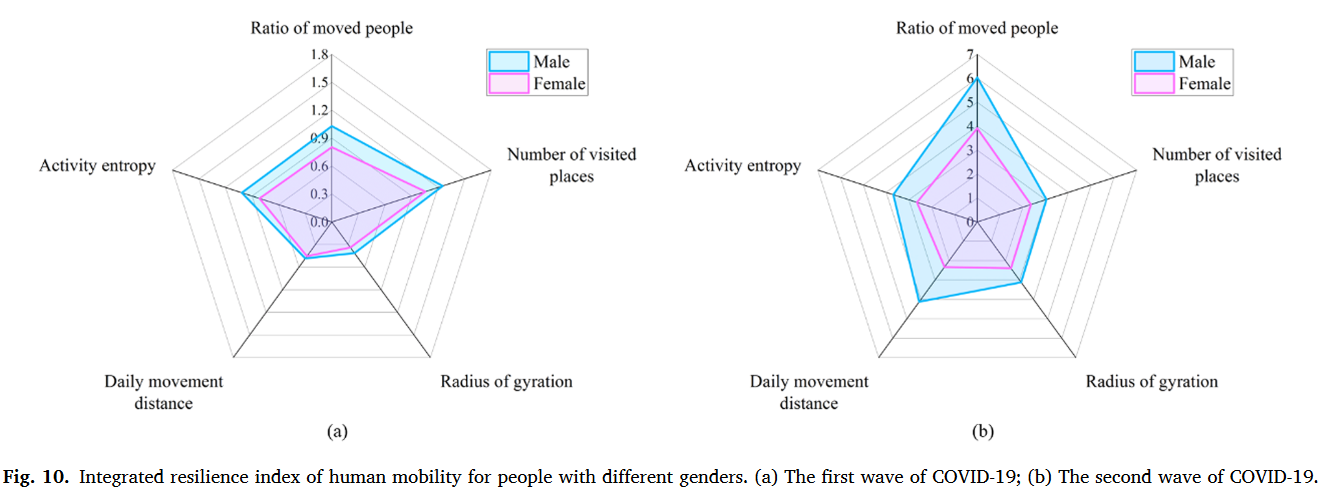
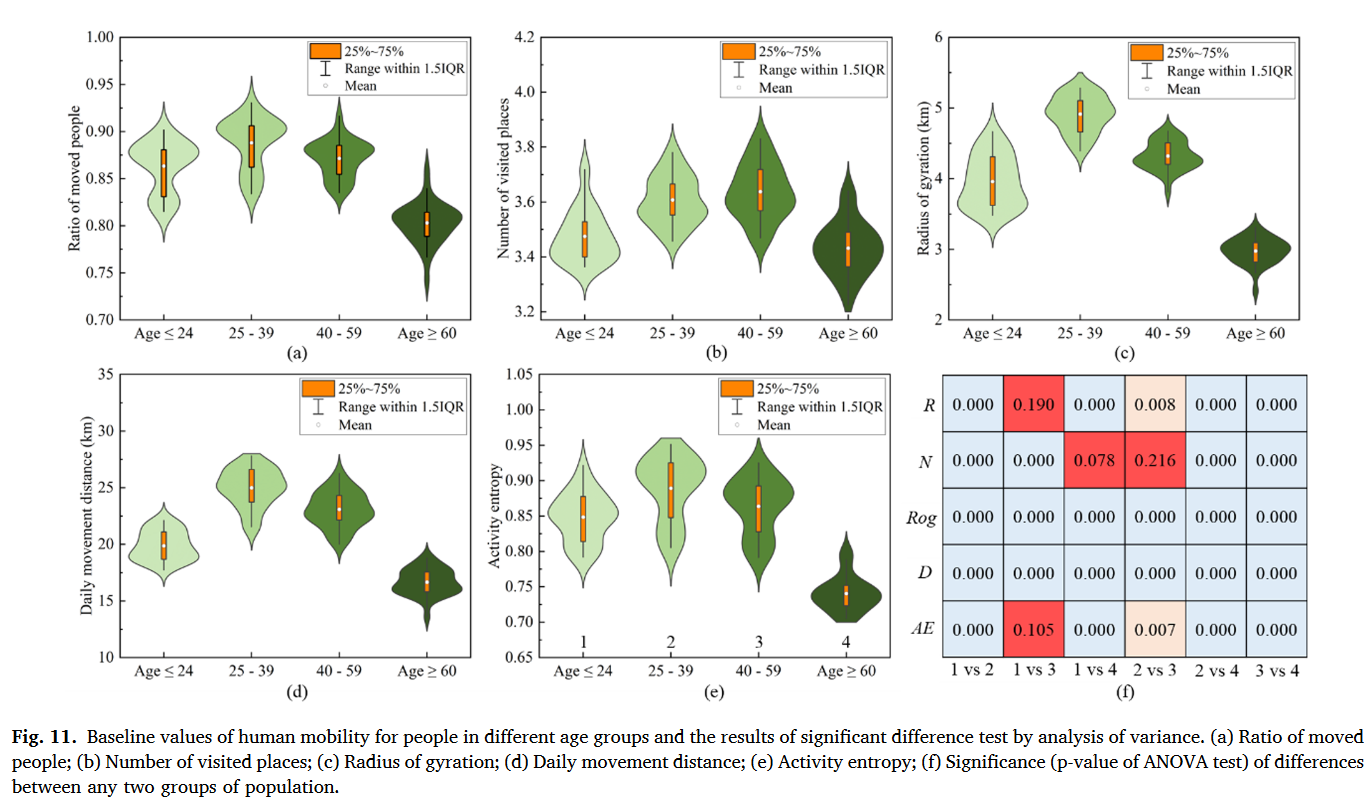
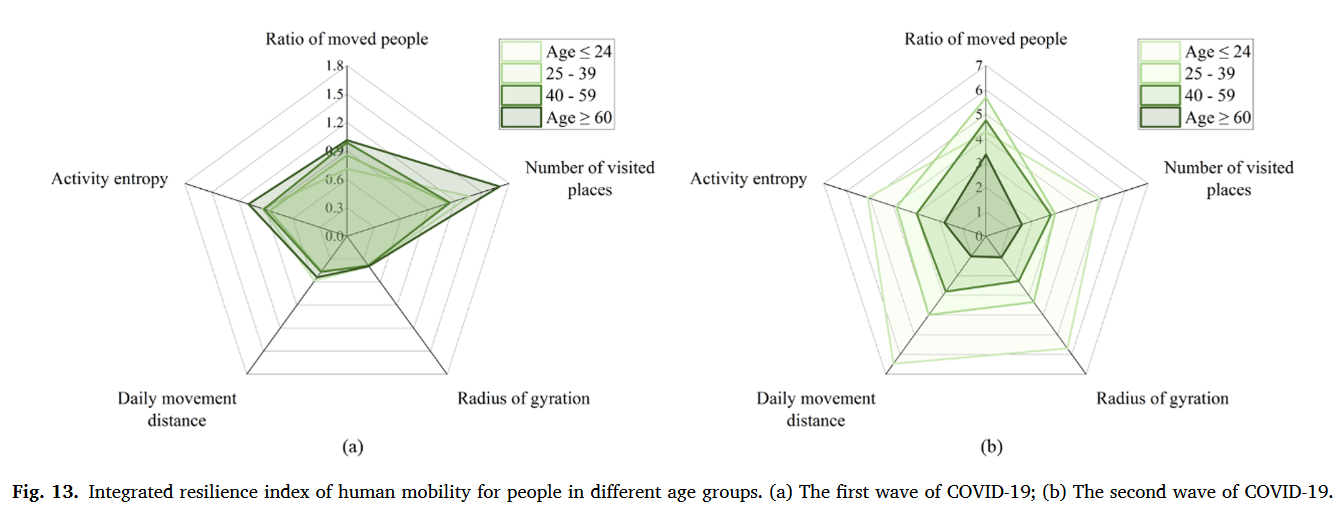
现有的人类流动性量化方法大体上可以划为三类:①移动强度:移动人口比例衡量一个地区整体流动强度、访问地点数量或移动频率衡量个体移动强度。②移动空间模式:移动位移衡量两个连续访问地点距离、回转半径衡量个体移动的空间范围、总位移衡量个体总移动距离③移动多样性:移动熵衡量移动方向的多样性、活动熵衡量访问地点多样性。
相比之下,量化人类移动韧性的方法要局限很多,常见的是移动位移和回转半径。评估移动韧性的框架通常有两种:①将灾害期间扰动的移动模式直接与常态进行比较。②基于韧性三角概念评估人类移动韧性,它指向灾害期间人类移动的整体变化过程。
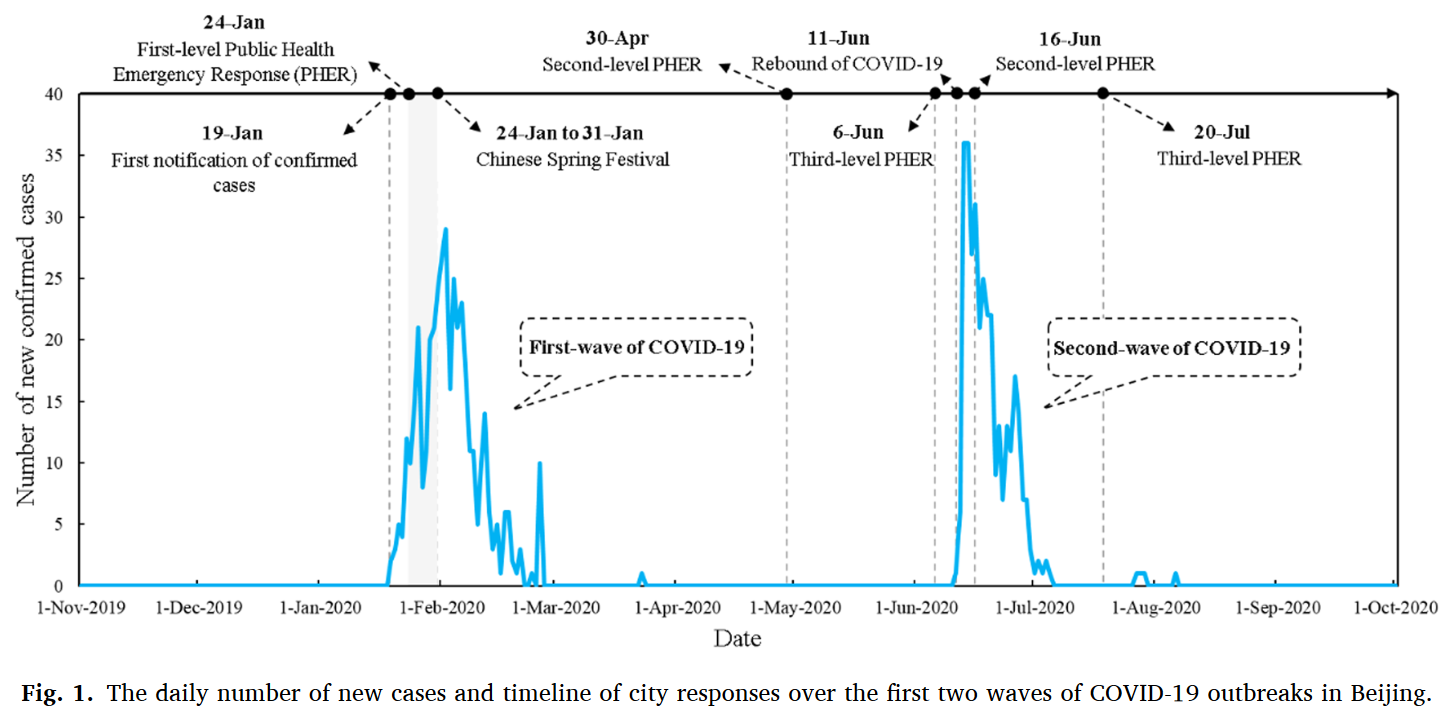
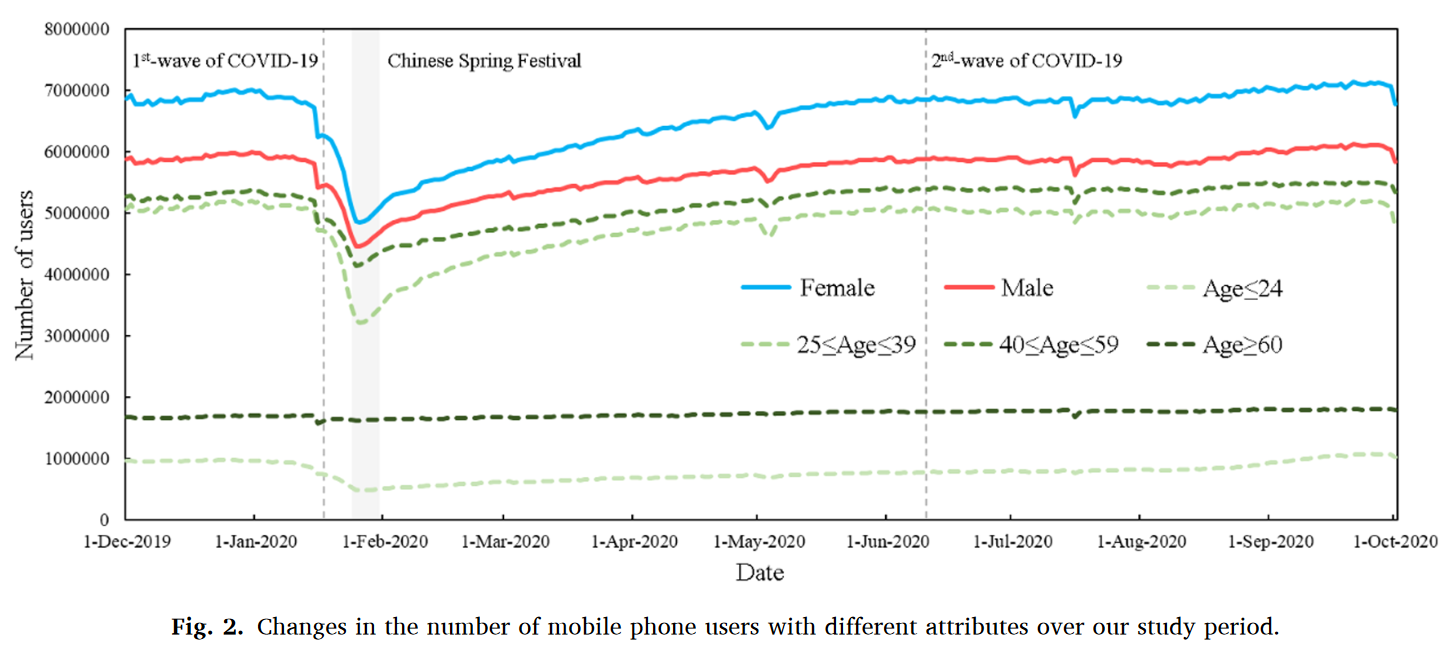
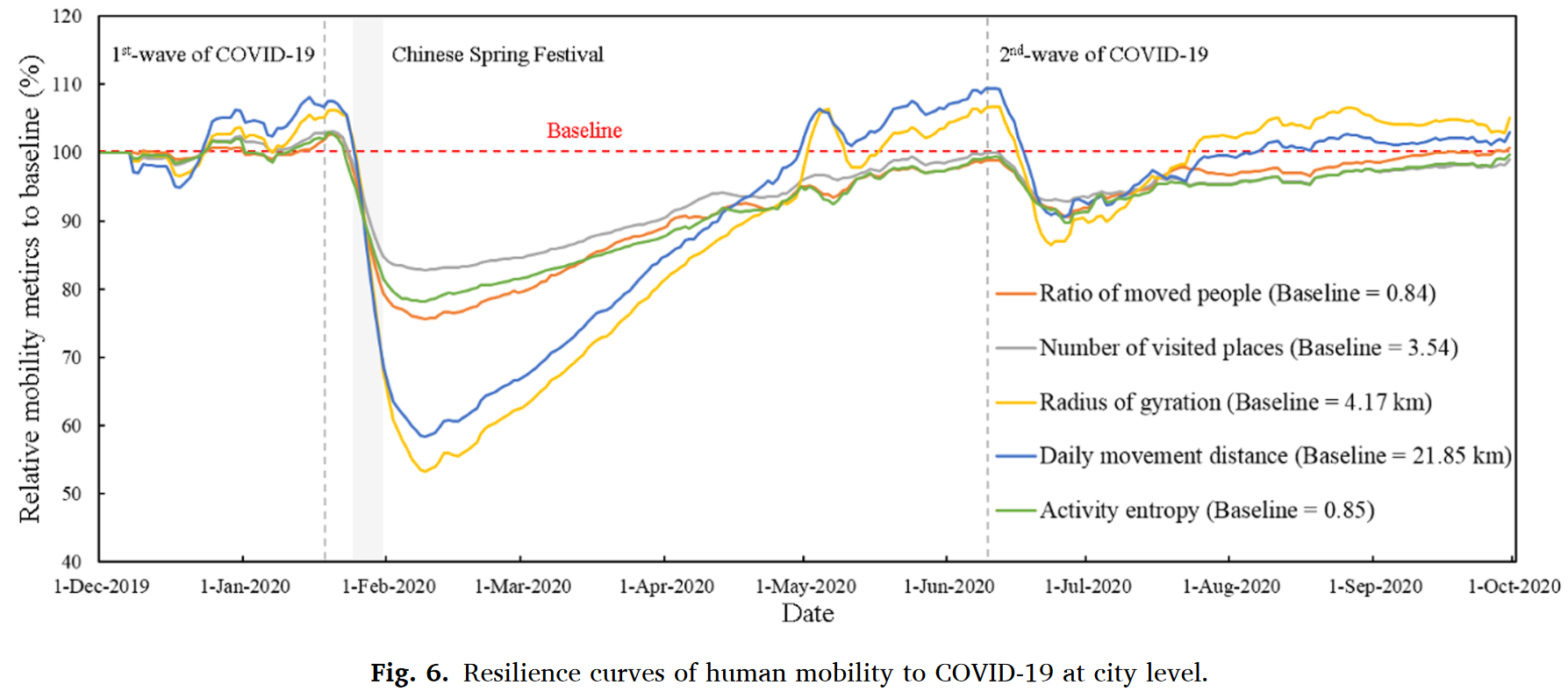
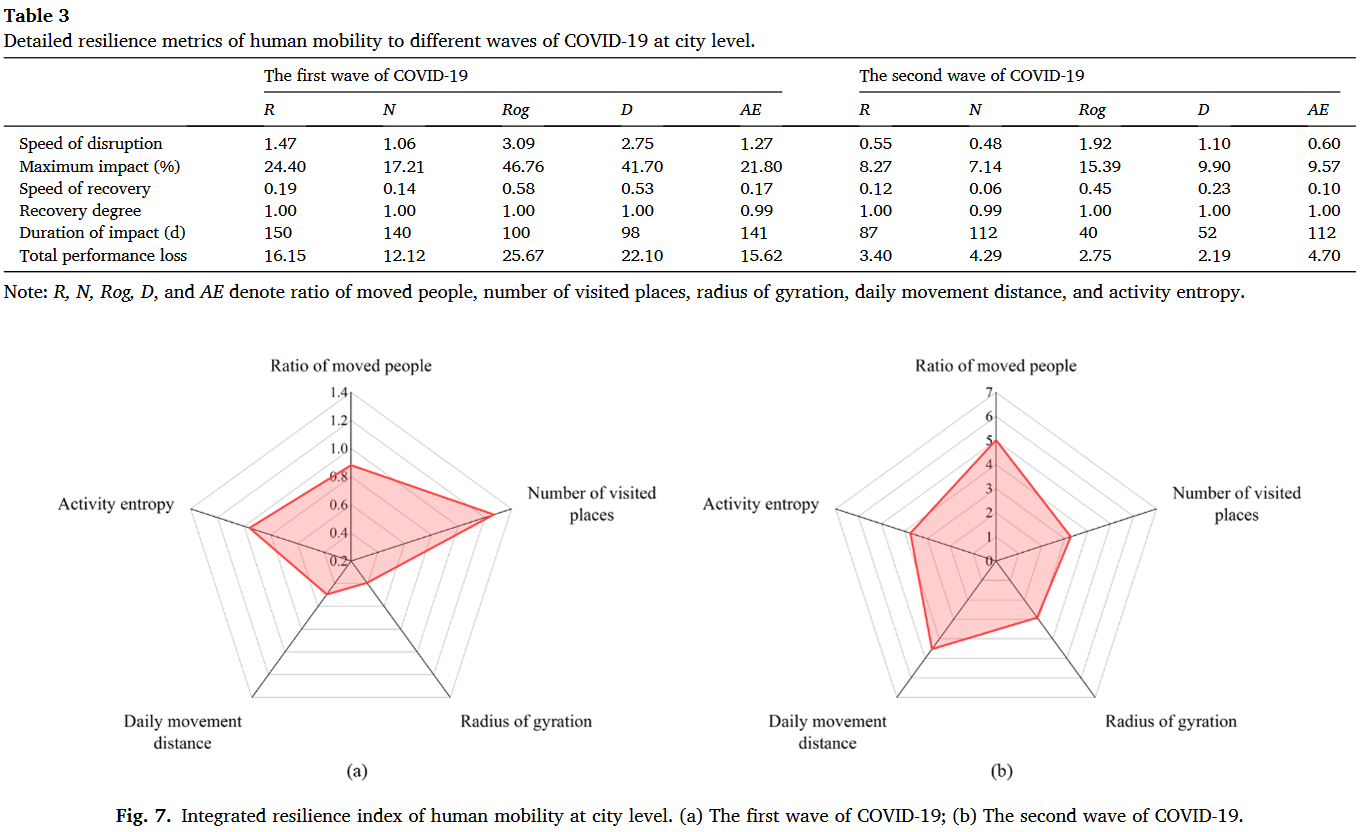
本研究重点研究北京自2019年12月至2020年9月的疫情数据,包含2020年1月(48天)和2020年6月(26天)两波疫情,利用手机信令数据从人类移动的不同角度设计了5种测量指标并提出了一套完整的自扰动开始至完全恢复的人类移动韧性评估框架。
作者采用了一些方法去除手机信令数据的噪声,清洗后的数据存储格式:$Trj=s_1\to s_2\to…\to s_n;s_i=(cx_i,cy_i,dur_i), i=1,2,…,n$。

测量指标:
- 移动人口比例$R=\frac{P_{moved}}{P}$
- 访问地点$N=|set(s_1,s_2,…,s_n)|$
- 回转半径$Rog=\sqrt{\frac{1}{N}\sum\limits_{i=1}^n((cx_i-\bar{x})^2+(cy_i-\bar{y})^2)}$
- $(\bar{x},\bar{y})=(\frac{1}{n}\sum\limits_{i=1}^ncx_i,\frac{1}{N}\sum\limits_{i=1}^1cy_i)$
- 即平均平方质心距离平方根
- 日常移动距离$D=\sum\limits_{i=1}^{n-1}\sqrt{(cx_i-cx_{i+1})^2+(cy_i-cy_{i+1})^2}$
- 活动熵$AE=-\sum\limits_{i=1}^np(s_j)log(p(s_j))$
- $p(s_j)=\frac{dur_j}{\sum\limits_{j=1}^Ndur_j}$
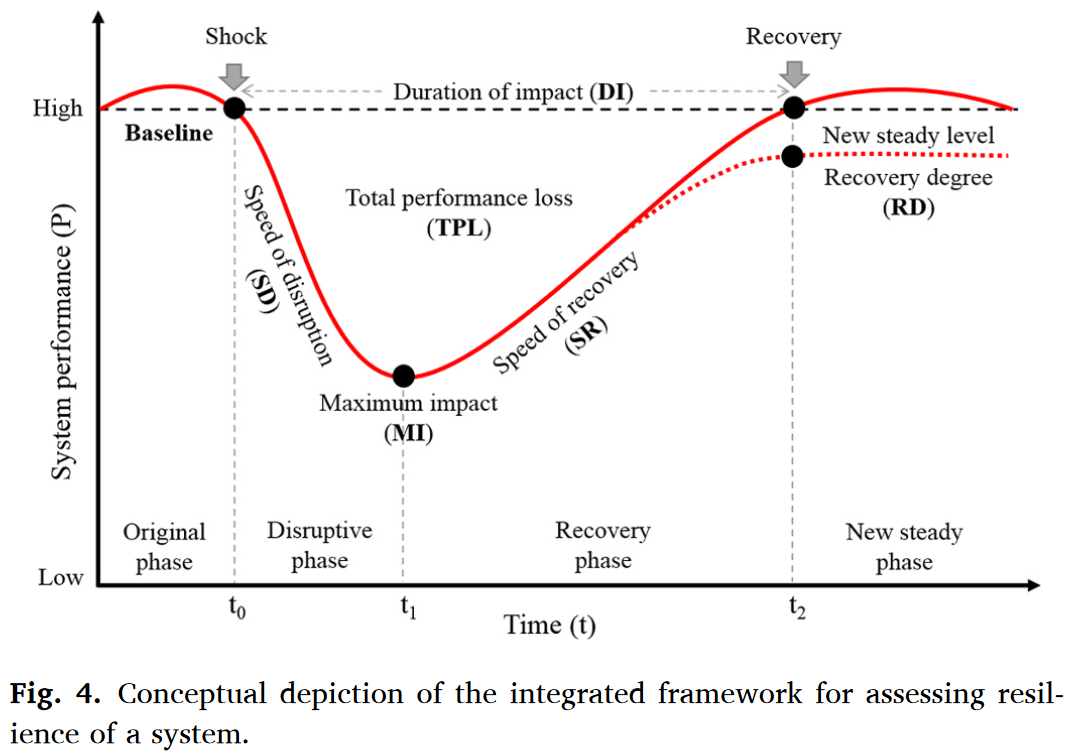
从系统整体角度上,作者又构建了两个评估整体冲击影响的指标:
- 整体性能损失$TPL$:系统性能曲线与基线的差异面积
- 冲击时长$DI$:从扰动到恢复的总时长
进一步地,可以构建时间平均性能损失$TAPL=\frac{TPL}{DI}=\frac{\int_{t_0}^{t_2}(Baseline-P(t))dt}{t_2-t_0}$。
最终的整体韧性指数$IRI=(Baseline-MI)\times\frac{SR}{SD}\times TAPL^{-1}\times RD$。
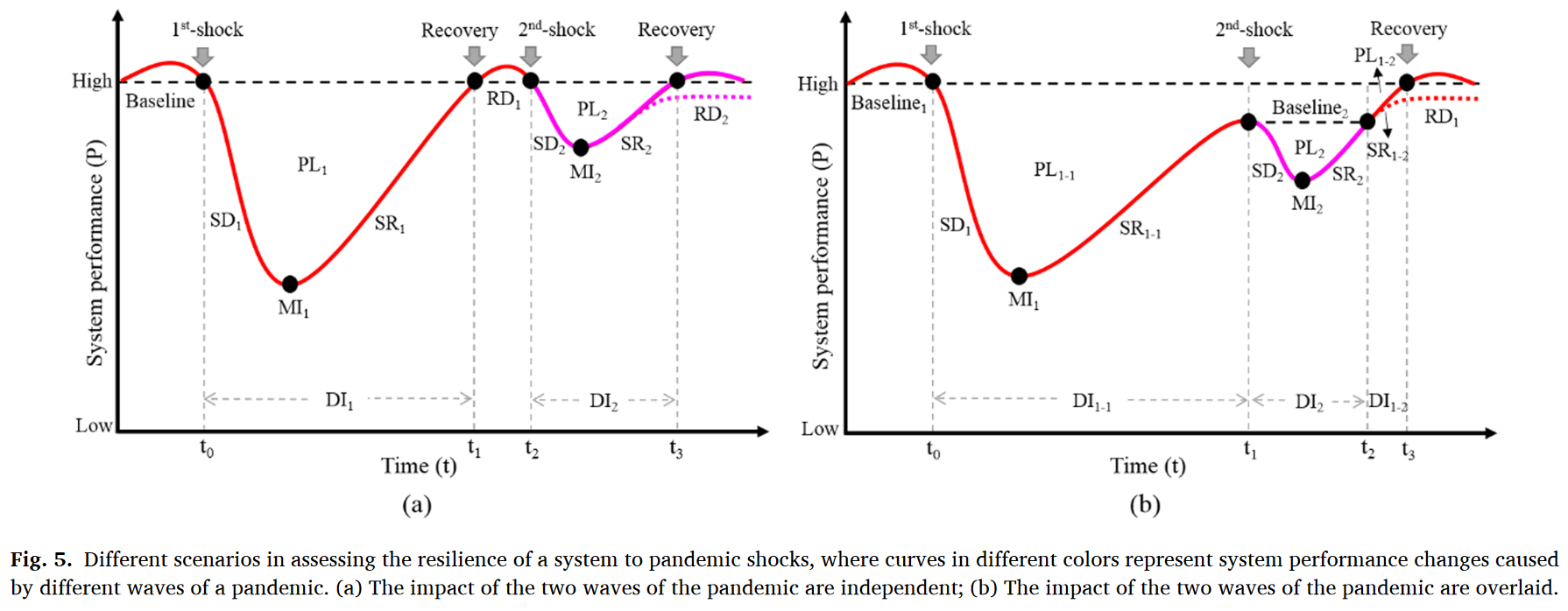
此外,考虑到疫情的多波次发生不会等待上一次冲击完全恢复,因此作者提出了分解系统性能曲线的方法。
城市视觉智能: 利用街景图像揭示隐藏的城市轮廓3
作者认为所有城市功能都有对应的视觉轮廓,因此提出一个问题:“城市轮廓在多大程度上与社区经济状态的多方面相联系?”
作者通过【Google Street View】获取了美国7个主要都市群内80个郡县两千七百万张城市图像,通过基于深度学习的计算机视觉算法提取树木、人行道、车辆、建筑等城市特征,并基于此分析了城市在街区层级的贫困、健康、犯罪和交通四个方面。
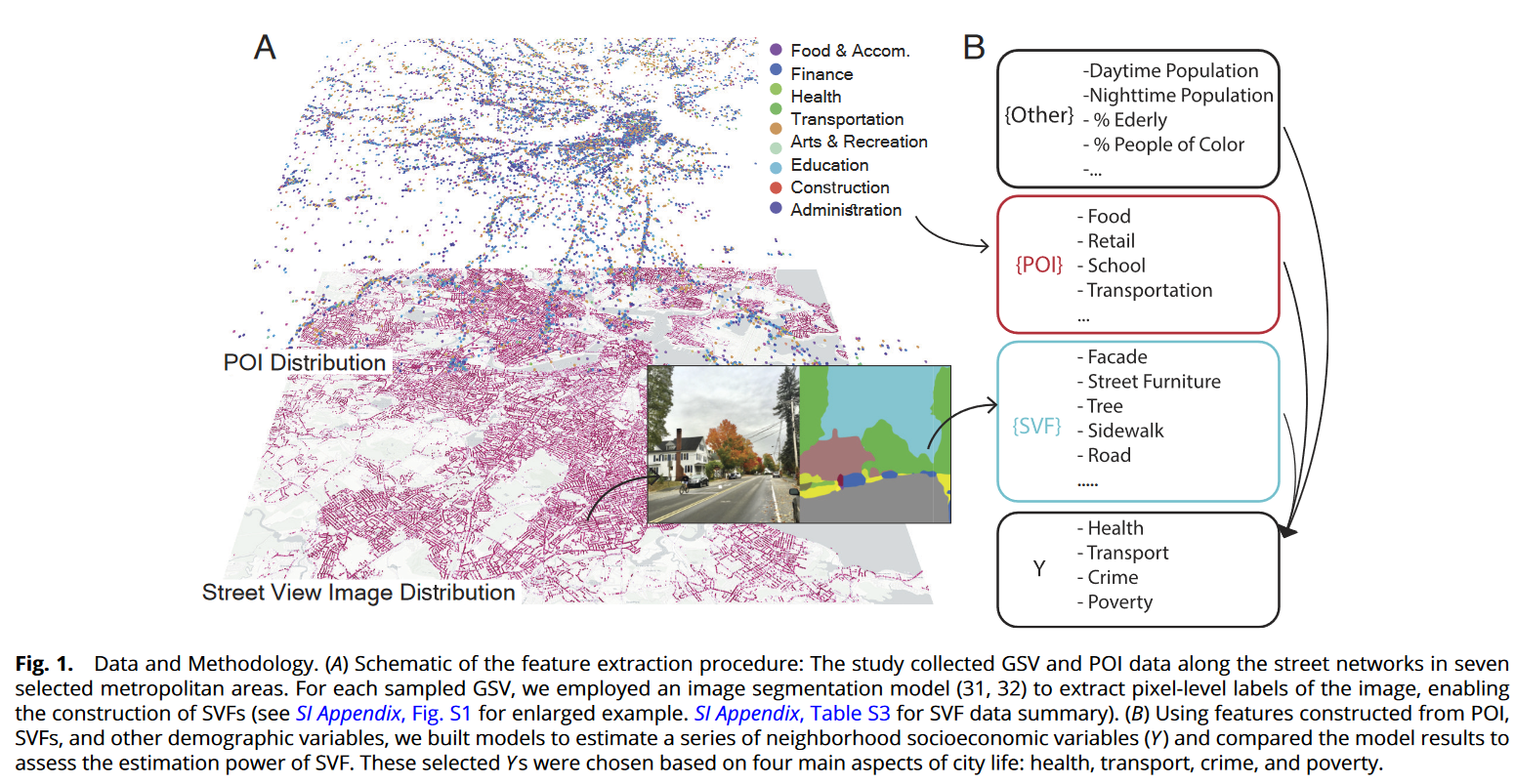
街景变量依据2010年美国人口普查局提供的普查区CT和普查街区组CBG汇总到不同的空间分辨率。对于每个空间单元,作者还计算了近邻的SVF平均值以解释空间溢出效应。
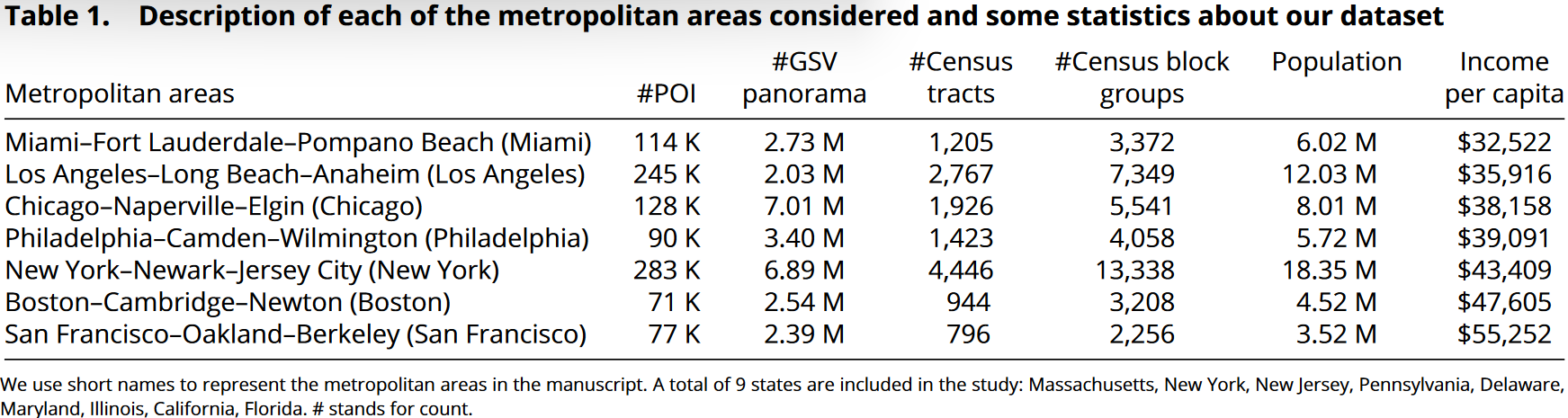
作者使用LASSO算法对数据进行了分析,结果表明SVF在社会经济方面估计能力超过POI。POI数据源自【Safegraph sore data (2019)】 National Park and Recreation, and the Transit-oriented Development Database。
但作者没有分析其他算法。
用到的其他几个数据集:夜间人口数据【ACS 5-y survey 2015-2019】;白日人口数据从【Safegraph neighborhood visiting pattern data】计算得出。
图像制作使用QGIS。
三城记:用地理环境感知的社交媒体数据揭示人类与城市的互动关系4
被标题吸引的……研究我觉得比较浅。
A tale of three cities: uncovering human-urban interactions with geographic-context aware social media data
本研究旨在通过链接人类交互的时空特征,提供对人类生活中城市活动地点的深刻理解。技术上,作者采用了自己Yin and Chi (2021)的方式利用地理位置Twitter数据获取人类活动地点及城市环境中的连接交互。作者将研究范围限制在2014年Greater Boston, Chicago,San Diego三大美国都市区的地理位置tweets。
- 文献综述
现有人类-城市交互研究大体上可以归纳为三个内部联系的视角:探访visitation:市民所在城市地理位置;活动Activity:与特征活动关联的行为;流动Mobility:城市地点或活动之间的交通。因此作者将人类-城市交互Human-urban interaction概括为人类在城市空间内存在、活动、移动的交互行为。在研究层次上,通常分为集体视角和个体视角。
集体视角研究的主要研究主题是理解人类行为地点的时空分布聚集于城市区域的功能或结构的联系。这类研究可以为人类活动与城市地理空间环境的交互提供洞见,但由于人类行为复杂多变,聚集信息无法分解到个体层次。
目前个体视角的研究主要集中在寻求个体在城市环境中的移动和活动模式。这些研究可以揭示个体移动网络结构,GPS、Call Detail Records(DCR)、地理位置整合应用和社交媒体地理信息极大地降低了收集个体信息的成本。
- 数据
作者复用了他们在先前研究中使用过的2014年Greater Boston(98024账户;12.5 m条)与Chicago(87866账户;10.2 m条)地理信息Twitter数据,同时增加了San Diego(61238账户;8 m条)作为额外的研究区域。
数据包含ID、坐标和时间戳三个属性,同时作者根据ID生成了用户轨迹$Traj_{id}={id;<loc_1,t_1>,<loc_2,t_2>,…,<loc_i,t_i>,i=1,2,3…,n}$,此外作者要求用户在同一城市发推周期至少大于30天,并根据移动速度排除了部分机器人账户。
作者补充了块级土地利用详细地图。

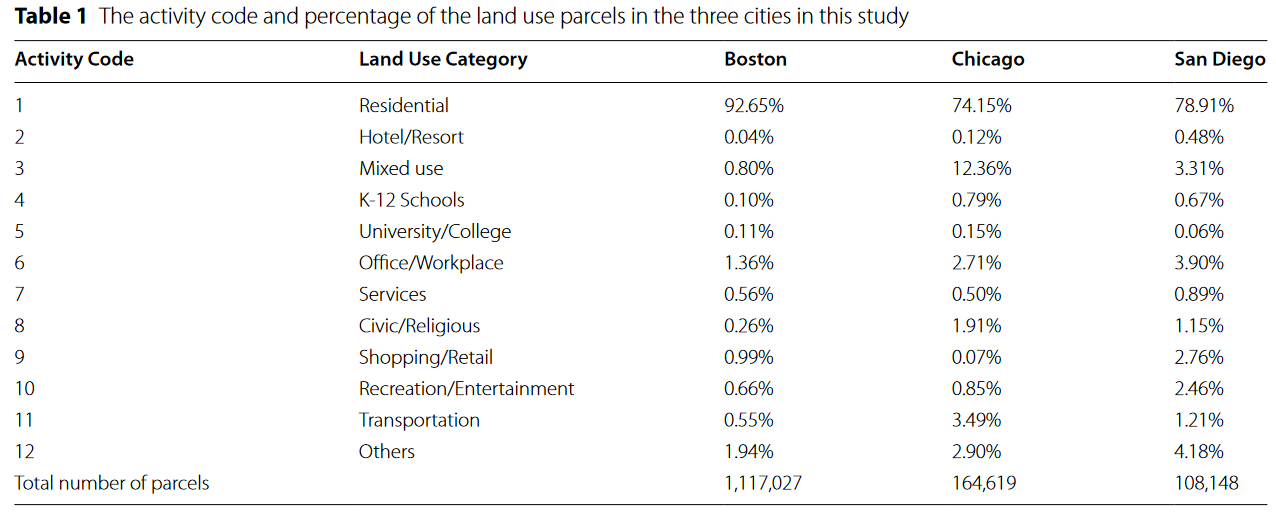
为识别用户实际活动场所,作者依据Twitter坐标10~250 m误差范围,在坐标250米半径内搜索最近块级土地利用类别,为每条推文添加土地使用地块$p_i$和Activity Code $a_i$。
作者认为只要推文数量高于用户轨迹中平均推文数量的土地使用地块才会被视作活动场所;活动场所的流行度通过每个地块的平均推文数量进行排列。
- 数据分析
Twitter用户活动序列是时间序列数据,作者引入了首次通过时间和返回时间衡量用户在同一活动地点发推间隔$\Delta t_{fp}$。
作者使用熵基模型预测活动序列,具体包括随机熵$S^{rand}$:$S_i^{rand}=log_2N$,其中$N$为用户$i$活动序列中不同地点数量;无条件熵$S^{rand}$:$S_i^{unc}=\sum\limits_{x\in X_i}P_i(x)log_2p_i(x)$,其中$p_i(x)$为Twitter用户到访活动序列地点$N_i$中第$i$个地点的概率$p_i(x)$;真实熵$S_i^{real}$:$?$,真实熵考虑了每个活动地点的出现频率及活动地点的访问顺序。
直觉上$S_i^{real}\leq S_i^{unc}\leq S_i^{rand}$。作者只使用了无条件熵和真实熵。
此处模型源自引用其他论文,有些地点没说清楚。
- 分析结果
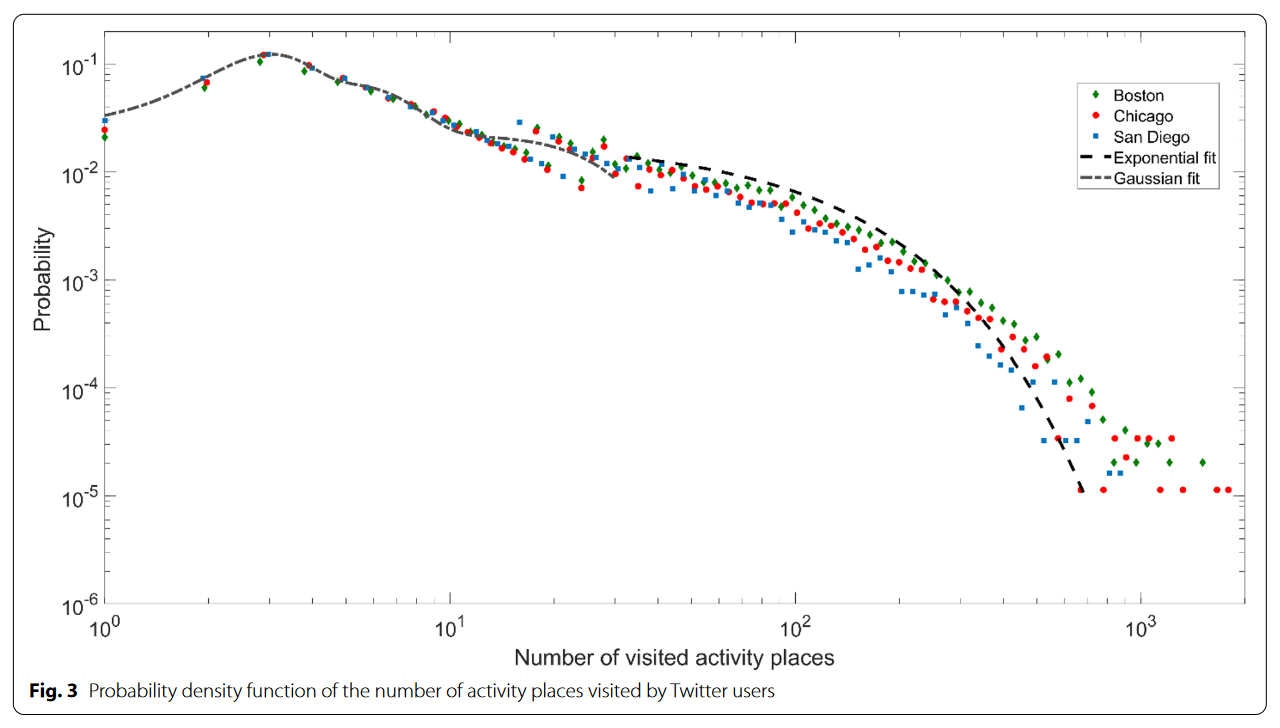
作者认为每个用户时间序列中活动地点数量在描述性统计上大致可以视作一个双峰分布,第一组用户访问了小于20个地点,他们大体上接近峰值为3的高斯分布。第二组访问大于20个地点的用户组分布要稀疏很多,倾向于服从指数分布。三个城市的分布函数高度接近。
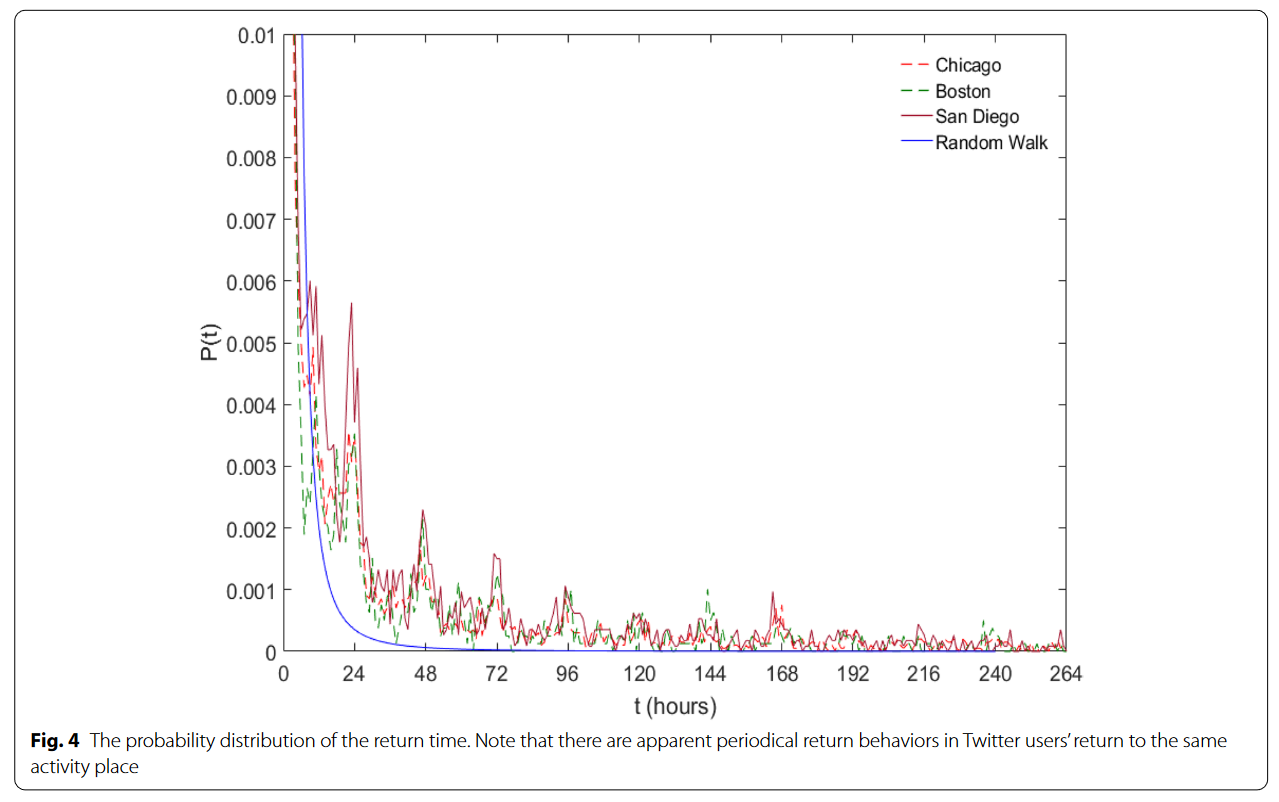
作者生成了一个随机游走序列与3个城市用户对同一活动地点的访问间隔进行对比,图像表明重访间隔与随机游走有明显差异【毫无意义的比较】,表现出清晰的24h间隔周期性特征。三个城市再次表现出相同模式。
RecSys’23 清华,shopee丨STAN:基于用户“生命周期”表征的阶段自适应多任务推荐方法5
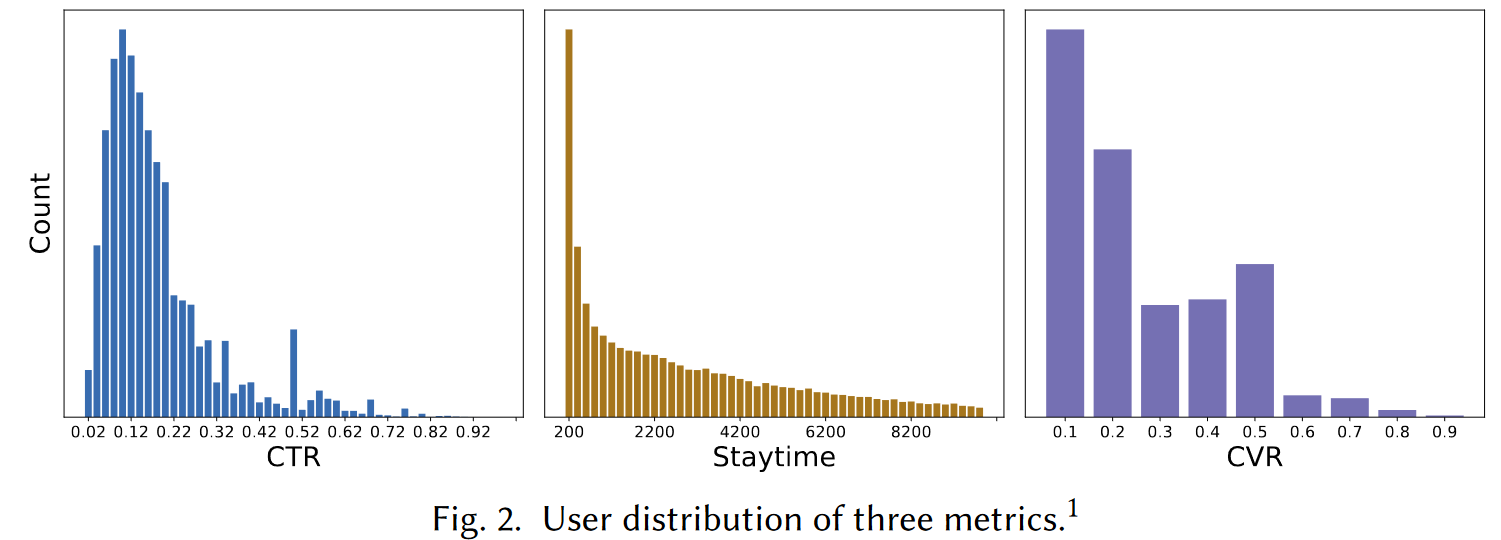
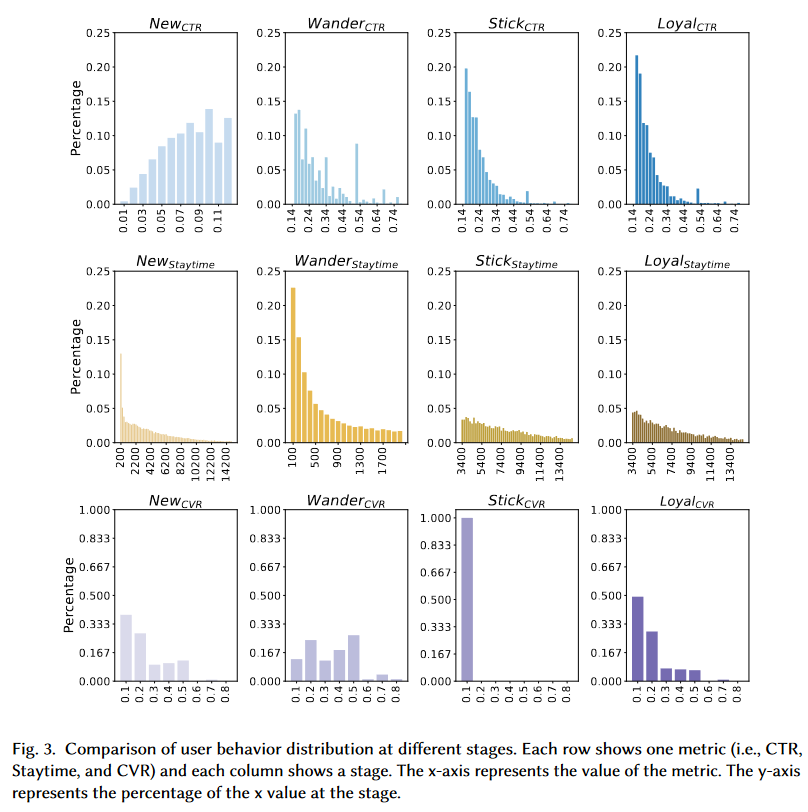
作者从电子商务平台收集了一个月的用户行为数据(点击、停留、购买),作者使用的“生命周期”是New-Wander-Stick-Loyal。New:低CTR,停留时长和CVR与整体顾客均值相同;Wander:低停留时长,较高CTR和CVR;Stick:较低CVR,高CTR和停留时长;Loyal:稳定的点击、停留和购买,表明用户对推荐结果和电商平台满意。
不了解作者从哪里找的,我看之前还以为是AIDA、AARRR或LTV。
无法理解作者的设计思路和命名依据,我不认为它们是顾客生命周期理论,倒不如说是四种不同类型顾客。
给定$m$个用户的数据集$\mathcal{D}=\{\{(U_i,V_j,y_{ij})\}_{j=1}^{n_i}\}_{i=1}^m$,向每个用户$i$展示项目$n_i$,$U_i\in\mathbb{R}^{d_1\times d_2}$为用户$i$的特征矩阵,$V_j\in\mathbb{R}^{d_3\times d_4}$表示产品特征矩阵,$d_1$为用户特征数,$d_2$为用户特征维度,$d_3$为产品特征数,$d_4$为产品特征维度。标签集$y_{ij}=[y_{ij}^1,…,y_{ij}^K]^T\in\mathbb{R}^K$包含对$K$个相关任务的测量,此处包括CTR、停留时间等。用户$i$的整体性能是$y_i=\frac{1}{n_i}\sum\limits_{j=1}^{n_i}[y_{ij}^1,…,y_{ij}^K]^T\in\mathbb{R}^K$。
本研究设计的架构包含两个部分,第一部分为多任务预测模型,为不同认为学习输入数据的表示;第二部分为潜阶段表示模块,它首先掌握用户偏好然后预测用户潜在阶段。最后,一个损失函数基于习得的用户阶段自适应调整对多个任务分配的注意力。
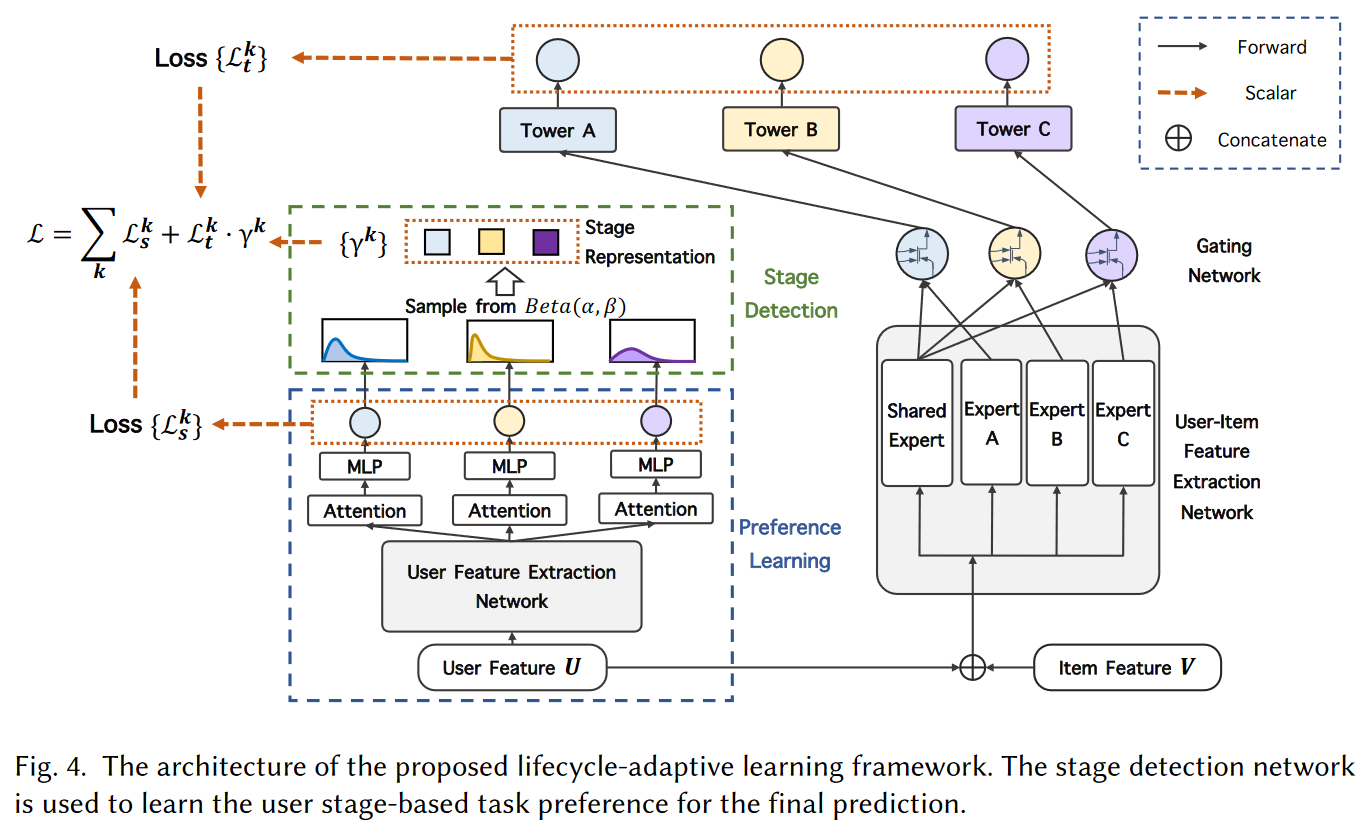
- 多任务预测网络
该部分基本基于PLE算法,但为减少不同任务之间的相互依赖问题,在共享层之后,作者没有共享专家网络。
使用$vec(\cdot)$表示矩阵矢量化。给定输入$x_{ij}=[vec(U_i)^T,vec(V_j)^T]^T\in\mathbb{R}^{d_1d_2+d_3d_4},i=1,…,m,j=1,…,n_i$;骨架网络的权重函数$w_B^k(x_{ij})=Softmaxt(W_B^kx_{ij})$获取任务$k$的权重向量。其中$W_B^k$是骨架中任务$k$的可训练参数矩阵;$H^k(x_{ij})=[Exp_{sp}^k(x_{ij}),Exp_{Sh}(x_{ij})]^T$是特定任务专家$Exp_{sp}^k(x_{ij})$和共享专家$Exp_{sh}(x_{ij})$的结合;任务$k$的gating网络$g_B^k(x_{ij})=w_B^k(x_{ij})\bigodot H^k(x_{ij})$。
每个任务$k$的预测值$\hat{y}_i^k(x_{ij})=f_T^k(g_B^k(x_{ij}))$,其中$f_T^k$为任务$k$的tower网络。
多任务学习的目标函数$\mathcal{L}=\sum\limits_k\eta^k\cdot\mathcal{L}^k$,其中$\eta^k$为超参,$\mathcal{L}^k$为特定任务损失函数。常规的做法是采用启发式规则确定$\eta^k$,但固定的$\eta^k$可能不能适配上述的多类型用户,因此作者提出了用户偏好学习模块和潜在用户阶段表示模块,动态地适应用户的偏好和阶段变化。
- 用户偏好学习
该模块包含3个构建板块:用户特征提取网络,从输入用户特征$U$中提取更多表示特征;特定任务用户表示学习单元,生成包含每个任务用户隐藏偏好的对应Embedding;任务测量预测单元,使用特定任务Embedding预测每个任务的值。
用户特征提取网络$U_i^{‘}=f(U_i)$,其中$U_i^{‘}\in\mathbb{R}^{d_1\times d_2},i=1,…,n$。函数$f$是一个自注意单元,能够较好的处理长期依赖、识别重要特征。令$W_QU_i,W_KU_i,W_vU_i$分别为query、key和value矩阵,其中$W_Q,W_K,W_V$均为$d_1\times d_1$权重矩阵。自注意机制为$f(U_i)=Softmax(\frac{1}{\sqrt{d_1}}W_QU_i(W_KU_i)^T)W_VU_i$。
特定任务用户表示学习单元同样是Attention单元,对于任务$k$,对应的Embedding$s_i^k=U_i^{‘}\bigodot Softmax(W^k\cdot U_i^{‘}),k=1,…,K$,其中权重矩阵$W^k\in\mathbb{R}^{d_2\times d_2}$在训练中习得。
任务测量预测单元直接在Embedding基础上使用单层前馈网络$\tilde{y}_i^k=Sigmoid(MLP^k(s_i^k)),i=1,…,n;k=1,..,K$。
为解释用户行为的有效性,作者创建了一个标签,取一段时间内$\tilde{y}_i^k$平均行为值,伪标签$l_i^k=\frac{1}{\mathcal{|D_i|}}\sum\limits_{y_j^k\in\mathcal{D}_i}y_j^k$,其中$\mathcal{D}_i=\bigcup_{j=1}^{n_{i^{‘}}}\{(U_{i^{‘}},V_j,y_{i^{‘}})\|i^{‘}<i\}$是$\mathcal{D}$只包含前$i$个实例的子集。该方法整合了过去一段时间的用户偏好,令表示更准确。
损失函数$\mathcal{L}_s^k(\tilde{y}^k,l^k)=\sum\limits_{i=1}^n(l_i^k-\tilde{y}_i^k)^2$。
- 潜在用户阶段检测
当用户样本较少时预测$\tilde{y}^k$需要被调整,假设$\tilde{y}^k\sim Beta(\alpha^k,\beta^k)$,$\alpha^k$和$\beta^k$分布表示在实验中用户执行/不执行动作(点击、购买等)的次数,$\alpha^k$和$\beta^k$使用Algorithm 1进行更新,随着更多样本喂入模型,$\gamma^k$会将$\tilde{y}^k$改善的更可靠稳健。

- STAN损失函数
框架中包含两个部分的损失函数:多任务学习预测网络$\mathcal{L}_t^k$和阶段检测网络$\mathcal{L}_s^l$。整体的目标函数是基于任务特定偏好$\gamma^k$的线性组合$\mathcal{L}(\hat{y}^k,\tilde{y}^k,y^k,l^k)=\sum\limits_{k=1}^K(\gamma^k\cdot\mathcal{L}_t^k(\hat{y}^k,y^k)+\mathcal{L}_s^k(\tilde{y}^k,l^k))$,其中$\mathcal{L}_t^k(\hat{y}^,y^k)=\sum\limits_{i=1}^n(y_i^klog\hat{y}_i^k+(1-y_i^k)log(1-\hat{y}_i^k))$。
- 实验
- 数据
- 公开数据集:WeChat-Video Recommendation System dataset
- 产业数据集:2022年某月某电商平台数据
- 数据
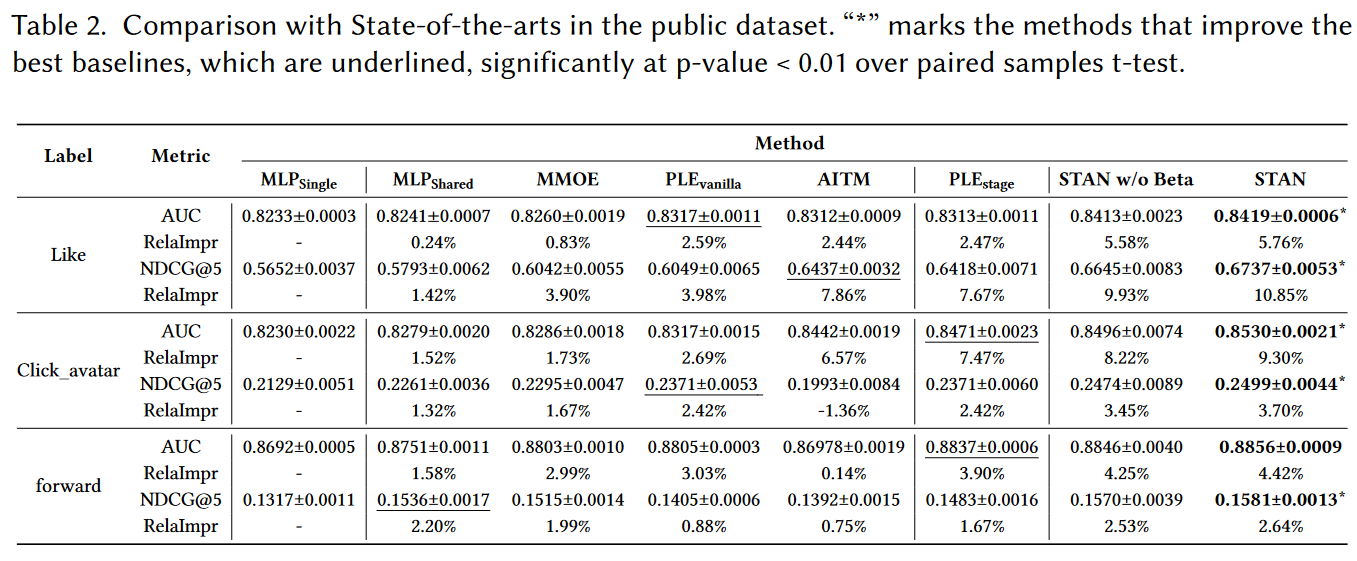
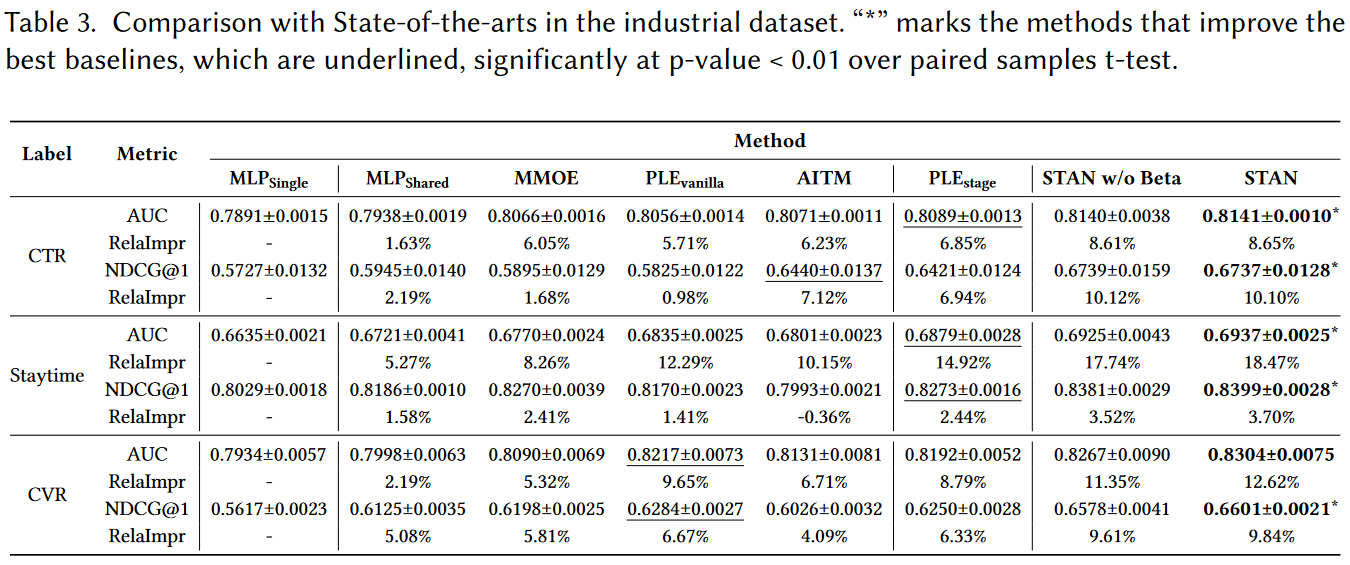
- 线上A/B测试
- 2023-03-15 ~ 2023-04-04电商直播场景
- CTR +3.94%
- staytime + 3.05%
- CVR + 0.88%
谢宇:社会科学研究的三个基本原理
我认为只有对社会科学研究的方法有深刻的理解,我们才能具体地运用统计的方法。如果没有这种基础知识支持的话,统计方法是没有太大用途的。
William Jevons说其实mean和average是不一样的。比如说长度,同一个人的身高测量50次得到的数据是不一样的,50个人的身高分别测量一次得到的数据也是不一样的。前者实际上是一个测量的误差,它真实的东西只有一个;而后者则是50个人之间的真正的差别,这个差别并不是误差,而是实际上的差异。
社会科学的重要性在于研究为什么个体和个体有差异,而不只是比较平均数。
- 变异性原理(Variability Principle)
- 变异性是社会科学研究的真正本质
- 社会分组原理(Social Grouping Principle)
- 社会分组只有根据社会结果(social outcomes)来分才会是有意义的
- 不是看你分组的原则是什么,是真的还是假的,是符合这个理论还是那个理论。从统计的观点来讲,分组的意义在于它有利于研究社会结果的差异
- 分组的意义在于它是否能解释差异
- 社会分组能减少社会结果的差异性,减少得越多,社会分组就越有意义
- 社会科学中的这个误差是一个真实性的、理解性的误差,是知识上的一个缺陷,是真实的而不是可以忽略不计的。物理学的误差经过测量许多次取平均数就可以忽略掉,而在社会科学中误差就是知识上的缺陷
- 社会情境原理(Social Context Principle)
- 群体变异性的模式会随着社会情境(social context)的变化而变化,这种社会情境常常是由时间和空间来界定的
- 社会科学经常要用到时空的概念
清华政治学系丨计算社会科学与研究范式之争:理论的终结?
从学科发展的历史来看,大数据的涌现仅仅是重启了计算社会科学,而非创造了新的学科。
计算社会科学会改变学者们把收集和分析数据看成两个分离过程的思维定势。
计算社会科学冲击社会科学研究所带来的范式转换可以被视为上帝之手(大数据研究)与研究者视角(传统研究)的再次竞合。而这样的竞合,并非空前未见;过去有类似的对话,例如非参数模型(预测导向)与参数模型(理论驱动)的交锋、贝叶斯学派(弱模型)和频率学派(强模型)的争论。这次的竞合可以视为过去方法论对话的延续与再启动。不同以往的是,过去的争论是在小数据的基础上不同方法的选择,此次的竞合则是在大数据的基础上探索方法融合的可能性。
MIT加州理工让ChatGPT证明数学公式,数学成见证AI重大突破首个学科6
作者利用开源的Lean数据图书馆数据构建了一个只需要1 GPU 周时间训练的开源大语言定理证明模型,并证实了它的性能由于基准模型与GPT-4。
自动定理证明ATP是一个重要的领域,它生成可以被严格检验的数学证明,是形式验证的基础,对证明高风险应用的正确性和安全性至关重要。
然而,由于搜索空间过大,在许多应用中全自动的定理证明通常是不可行的,因此交互定理证明ITP作为可替代范式被提出。在ITP中,人类专家与Coq,Isabelle,Lean等辅助证明软件进行交互,共同构建证明。
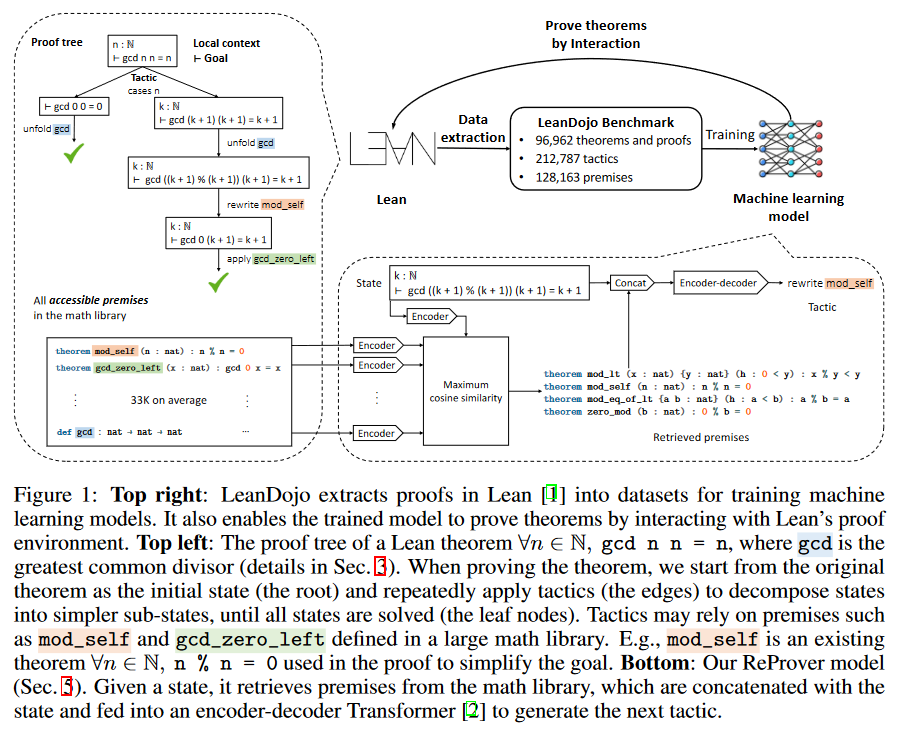
形式证明本质上是计算机程序,但与传统程序不同,形式证明可以通过证明助手进行验证,因此可以视作特殊的代码生成任务:严格评估且不具有模型幻觉空间。形式证明的特征与LLMs高度契合,因此将大语言模型与数学证明助手相结合具有广阔前景。
本研究聚焦于开源证明助手Lean,LeanDojo框架实现了两个基本功能:提取数据 & 使模型以编程方式与Lean进行交互。
Lean
2019年年底的数据库数据,未找到最新的。
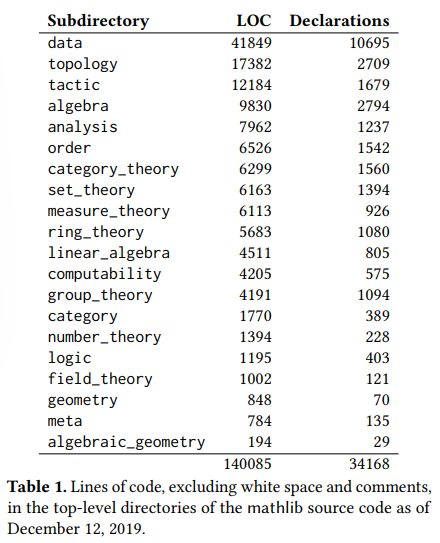

在数据提取方面,LeanDojo可以提取原始Lean代码中无法直接看到的训练数据,如证明步骤中间状态组成的证明树。LeanDojo将现有工具中的证明检查错误(将正确证明误判为错误)比例从21.1%降低至1.4%。
LeanDojo通过检索增强LLM解决了定理证明的一个关键瓶颈:前提选择。现有的基于LLM证明器都是将当前状态作为输入,然后生成下一个证明步骤(策略)。通常,证明过程开始于将原始定理作为初始状态,不断应用策略将之分解为简单子状态,直至所有状态被解决。
然而,整合所有可能的前提传入大语言模型是不现实的,因此现有的方法都是记忆证明状态与已有定理的关联,如果训练数据中包含解决类似目标的样本,那么LLM证明器就可以奏效,但是这样的方法无法处理包含未知词法的定理或类似的新颖场景。
一种潜在的解决方法是选择部分明确的前提补充记忆。LeanDojo通过从Lean中提取数据(含定义和使用前提的位置),使用户可以利用检索增强的LLM解决前提选择问题。具体地,LeanDojo引入了ReProver(检索增强证明器):在给定当前状态下,它根据Lean数学库mathlib检索生成一个使用少量前提条件的策略。
本研究的检索器建立在Dense Passage Retriever(DPR)基础上,但有两个创新:其一,在证明定理时并非所有前提都可以访问,LeanDojo通过对Lean代码分析筛选可访问的前提,平均将前提数量从128k降低至33k;其二,DPR需要使用困难负例进行训练,作者提出了in-file negative方法,即从与真实前提同在一个Lean源文件中抽样hard negative。
- 前提检索
给定状态$s$作为查询,$\mathcal{P}=\{p_i\}_{i=1}^N$为前提候选库,DPR从$\mathcal{P}$中检索$m$个与状态$s$余弦相似度最大的前提$\{p_{i}^{‘}\}_{i=1}^m$的排序列表。在DPR中,$s$和$p_i$均是Embedding到向量空间的纯文本。
正式地,采用一个拥有参数$\theta$的函数$f$,它将状态和前提分别Embedding到$h$维向量空间:$f(s,\theta),f(p_i,\theta)\in\mathbb{R}^h$。作者通过最大化$\frac{f(s,\theta)^Tf(p_i,\theta)}{||f(s,\theta)||_2||f(p_i,\theta)||_2}$检索前提。$f$通过一个跟随着平均池化的Transformer Encoder获取:$f(\cdot, \theta)=AvgPool(Enc(\cdot, \theta))$。
给定$b$个状态作为一批次,对每个状态从ground truth中抽取一个正例前提,从$\mathcal{P}$中抽取$n$个负例前提。同时,这些负例被所有批内状态共享,所以称为批内负例。这样每个状态都与$b\cdot(n+1)$个前提相关联,其中至少1个前提是正例。令$l_{ij}\in\{0,1\}$定义为状态-前提对$(s_i,p_j)$是否为正例,最终的损失函数为$\mathcal{L}(\theta)=\sum\limits_{i=1}^b\sum\limits_{j=1}^{b\cdot(n+1)}|l_{ij}-\frac{f(s_i,\theta)^Tf(p_j,\theta)}{||f(s_i,\theta)||_2||f(p_j,\theta)||_2}|^2$。
- 可行前提中检索
作者将检索范围限定在定理之前的同一文件中定义的前提,以及从其他文件中导入的前提。作者将LeanDojo基准数据集128163个前提缩减到33134个。
- 文件内负例
为提高DPR训练性能,作者抽取了$k$个文件内负例和$n-k$个随机负例进行训练。
- 策略生成
检索的前提会与状态连接,之后传入encoder-decoder Transformer ByT5,在没有强化学习和辅助数据的情况下生成策略用于策略生成,训练目标是最小化与人类书写测量交叉熵损失。
之后作者使用best-first search搜索证明。本研究提出的算法创新性主要在检索功能上。
作者通过从mathlib数据集中提取了96962个定理/证明作为基准,由于人类书写定理/证明具有重复性和相似性,前人已经证明简单地随机划分样本可能导致模型记住证明而高估性能,因此作者设计了具有挑战性的划分,测试集要求模型通过至少一个训练集未曾用过的全新前提来生成定理,最终使用了2000个验证集样本和2000个测试集样本。
作者使用LeanDojo基准在单个GPU上消耗了5天训练模型,结果表明ReProver可以证明51.4%的定理,高于不具备检索模型的47.5%及GPT-4通过零次学习Zero-shot生成策略的基线28.8%。在现有的数据集MiniF2F和ProofNet上分别证明了26.5%和13.8%的定理,使用更少的训练资源到达了除强化学习外最前沿模型的相同水准。此外,LeanDojo证明了65个未曾在Lean上证明的定理。

技术技巧
数据预处理 丨Pandas AI,和Pandas说人话
基于Pandas和Open AI,可以偷懒用
-
Nan, L. X., Park, S. K., & Yang, Y. (2023). Rejections Are More Contagious than Choices: How Another’s Decisions Shape Our Own. Journal of Consumer Research, ucad007. https://doi.org/10.1093/jcr/ucad007 ↩
-
Liu, Y., Wang, X., Song, C., Chen, J., Shu, H., Wu, M., Guo, S., Huang, Q., & Pei, T. (2023). Quantifying human mobility resilience to the COVID-19 pandemic: A case study of Beijing, China. Sustainable Cities and Society, 89, 104314. https://doi.org/10.1016/j.scs.2022.104314 ↩
-
Fan, Z., Zhang, F., Loo, B. P. Y., & Ratti, C. (2023). Urban visual intelligence: Uncovering hidden city profiles with street view images. Proceedings of the National Academy of Sciences, 120(27), e2220417120. https://doi.org/10.1073/pnas.2220417120 ↩
-
Yin, J., & Chi, G. (2022). A tale of three cities: Uncovering human-urban interactions with geographic-context aware social media data. Urban Informatics, 1(1), 20. https://doi.org/10.1007/s44212-022-00020-2 ↩
-
Li, W., Zheng, W., Xiao, X., & Wang, S. (2023). STAN: Stage-Adaptive Network for Multi-Task Recommendation by Learning User Lifecycle-Based Representation (arXiv:2306.12232). arXiv. http://arxiv.org/abs/2306.12232 ↩
-
Yang, K., Swope, A. M., Gu, A., Chalamala, R., Song, P., Yu, S., Godil, S., Prenger, R., & Anandkumar, A. (2023). LeanDojo: Theorem Proving with Retrieval-Augmented Language Models (arXiv:2306.15626). arXiv. http://arxiv.org/abs/2306.15626 ↩